arXiv: 2604.22050 · PDF
Authors: Mohamed Ali Souibgui, Jan Fostier, Rodrigo Abadía-Heredia, Bohdan Denysenko, Christian Marschke, Igor Peric
Primary category: cs.LG · all: cs.CL, cs.LG
Matched keywords: llm, inference, serving, attention, transformer, throughput, latency
TL;DR
LayerBoost is a layer-aware attention reduction method that uses sensitivity analysis to selectively apply softmax, linear sliding window, or no attention per layer, recovered via a lightweight 10M-token distillation. It improves throughput by up to 68% at high concurrency while preserving quality.
Key Ideas
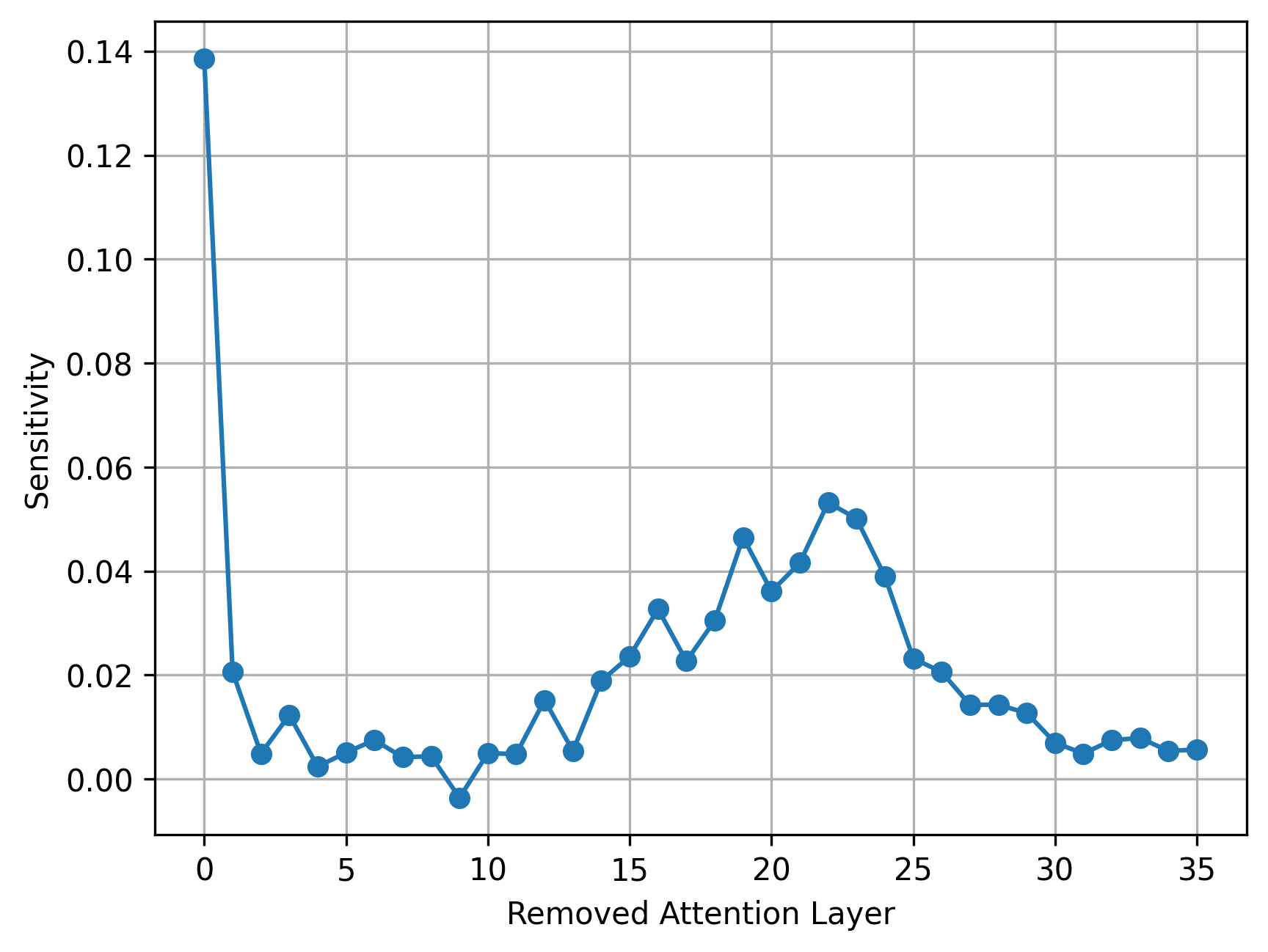
- Uniform attention linearization hurts quality; layers differ in sensitivity.
- A per-layer sensitivity analysis identifies critical vs. skippable layers.
- Three-tier policy: keep softmax, swap to linear sliding window, or drop attention entirely.
- Cheap distillation “healing” with only 10M tokens restores quality.
Approach
Starting from a pretrained Transformer, LayerBoost profiles each layer’s sensitivity to attention modification. High-sensitivity layers retain standard softmax attention; moderate-sensitivity layers are replaced with linear sliding window attention; low-sensitivity layers have attention removed outright. After these architectural edits, a lightweight distillation-based healing phase (10M additional tokens) aligns the modified model to the original teacher, recovering task performance without full retraining.
Experiments
The abstract references multiple benchmarks and comparison against state-of-the-art attention linearization baselines, with emphasis on inference latency and high-concurrency throughput. Specific datasets, model sizes, and metric names are not disclosed in the abstract.
Results
Reports up to 68% throughput improvement at high concurrency. Matches base model performance on several benchmarks, minor degradation elsewhere, and significantly outperforms prior attention linearization methods. No absolute accuracy numbers are provided in the abstract.
Why It Matters
For inference-infra teams, LayerBoost offers a training-light path to cut attention cost without the quality cliff of uniform linearization. It is especially relevant for high-concurrency serving and memory-constrained deployments, where KV cache and quadratic attention dominate cost.
Connections to Prior Work
Builds on linear attention (Performer, Linformer), sliding window attention (Longformer, Mistral), hybrid architectures (Jamba, Zamba), and attention pruning / layer-skipping literature. The distillation healing phase echoes MiniLM-style and LLM compression-recovery pipelines, and the sensitivity analysis parallels layer importance studies used in quantization and pruning.
Open Questions
- Which benchmarks degrade and by how much — the abstract is thin on numbers.
- How does sensitivity transfer across model families and scales?
- Does 10M tokens suffice for long-context or reasoning-heavy workloads?
- How does it compose with quantization, speculative decoding, or KV compression?
- Is the sensitivity metric robust to fine-tuning and downstream task shifts?
Figures
Figure 1: Figure 1 (extracted from PDF)
Figure 2: Figure 2 (extracted from PDF)
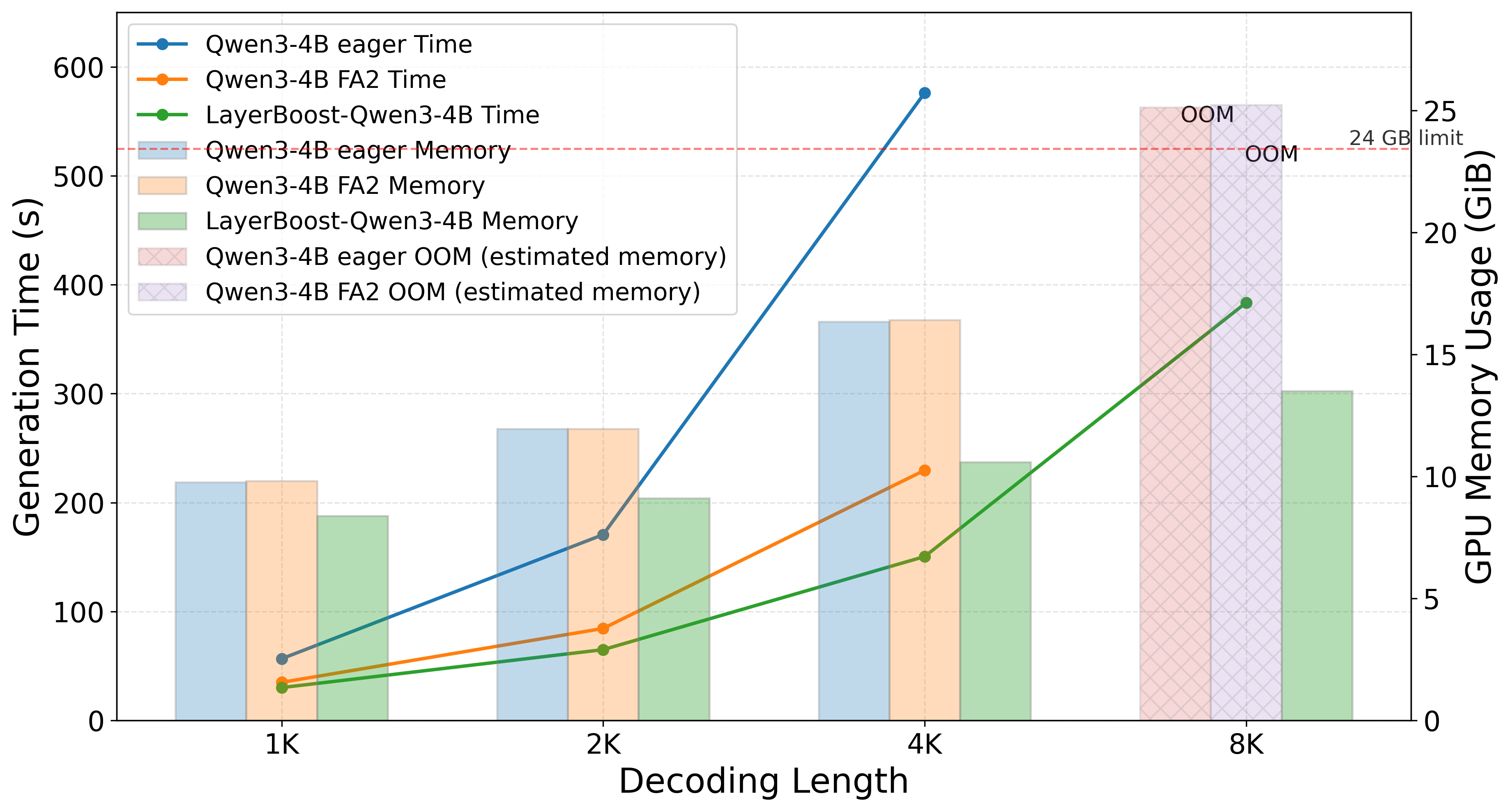
Figure 3: Figure 3 (extracted from PDF)
Original abstract
Transformers are mostly relying on softmax attention, which introduces quadratic complexity with respect to sequence length and remains a major bottleneck for efficient inference. Prior work on linear or hybrid attention typically replaces softmax attention uniformly across all layers, often leading to significant performance degradation or requiring extensive retraining to recover model quality. This work proposes LayerBoost, a layer-aware attention reduction method that selectively modifies the attention mechanism based on the sensitivity of individual transformer layers. It first performs a systematic sensitivity analysis on a pretrained model to identify layers that are critical for maintaining performance. Guided by this analysis, three distinct strategies can be applied: retaining standard softmax attention in highly sensitive layers, replacing it with linear sliding window attention in moderately sensitive layers, and removing attention entirely in layers that exhibit low sensitivity. To recover performance after these architectural modifications, we introduce a lightweight distillation-based healing phase requiring only 10M additional training tokens. LayerBoost reduces inference latency and improves throughput by up to 68% at high concurrency, while maintaining competitive model quality. It matches base model performance on several benchmarks, exhibits only minor degradations on others, and significantly outperforms state-of-the-art attention linearization methods. These efficiency gains make our method particularly well-suited for high-concurrency serving and hardware-constrained deployment scenarios, where inference cost and memory footprint are critical bottlenecks.