arXiv: 2604.22050 · PDF
作者: Mohamed Ali Souibgui, Jan Fostier, Rodrigo Abadía-Heredia, Bohdan Denysenko, Christian Marschke, Igor Peric
主分类: cs.LG · 全部: cs.CL, cs.LG
命中关键词: llm, inference, serving, attention, transformer, throughput, latency
TL;DR
LayerBoost 基于各层敏感度对 transformer attention 做差异化替换(softmax/线性滑窗/删除),配合轻量蒸馏 healing,在高并发下吞吐提升最多 68%。
核心观点
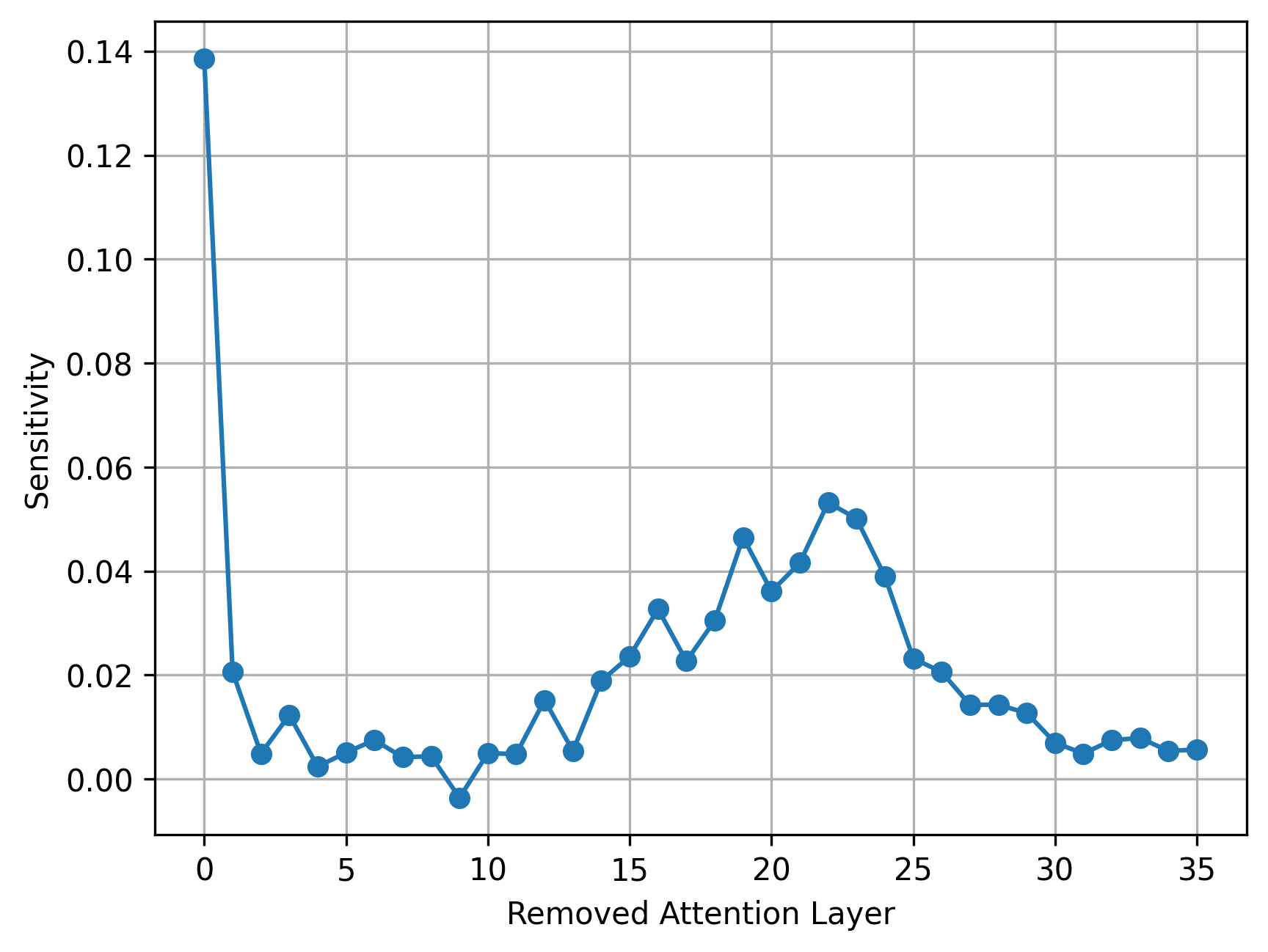
- Uniform 替换 softmax attention 会伤精度;不同层对 attention 的敏感度差异显著。
- 提出 layer-aware 三档策略:敏感层保留 softmax、中等层换线性滑窗、低敏感层直接去掉 attention。
- 仅用 10M token 的蒸馏 healing 即可恢复精度,无需大规模重训。
方法
- 在预训练模型上做系统性敏感度分析,给每层打分。
- 按敏感度划三档:
- 高敏感:保留 standard softmax attention。
- 中敏感:替换为 linear sliding window attention。
- 低敏感:直接移除 attention 模块。
- 架构改动后进行 distillation-based healing,只需额外 10M tokens 训练。
实验
摘要未列出具体数据集、基线模型与指标名称,仅提到与 SOTA attention linearization 方法对比,并在"若干 benchmark"上评估质量与延迟、吞吐。
结果
- 高并发场景下 inference latency 降低、throughput 提升最多 68%。
- 多个 benchmark 上持平 base model,少数有轻微下降。
- 明显优于现有 attention 线性化方法。
为什么重要
对 LLM serving 与硬件受限部署很实用:在几乎不损精度、训练成本极低(10M tokens)的前提下,大幅降低 attention 的推理开销,特别适合高并发在线服务与边缘部署。
与已有工作的关系
- 接续 Linear Attention、Performer、Mamba/SSM 等线性/次二次 attention 路线,但反对"全层统一替换"。
- 与 Sliding Window Attention(Longformer、Mistral)思路相近,用作中敏感层替代。
- Layer-wise 敏感度分析与 pruning/quantization 文献(如 LLM-Pruner、SparseGPT)思想一致。
- Distillation healing 继承 MiniLM、DistilBERT 等小样本蒸馏思路。
尚未回答的问题
- 敏感度度量的具体定义与跨模型/规模的稳定性?
- 10M tokens healing 对更大模型(70B+)是否依然足够?
- 长上下文任务(>32k)上线性滑窗档的精度损失?
- 与 KV cache 压缩、quantization 等其他优化的组合效果?
- 删除 attention 的层如何处理位置/全局信息传递,长期训练会否退化?
论文图表
图 1: Figure 1 (extracted from PDF)
图 2: Figure 2 (extracted from PDF)
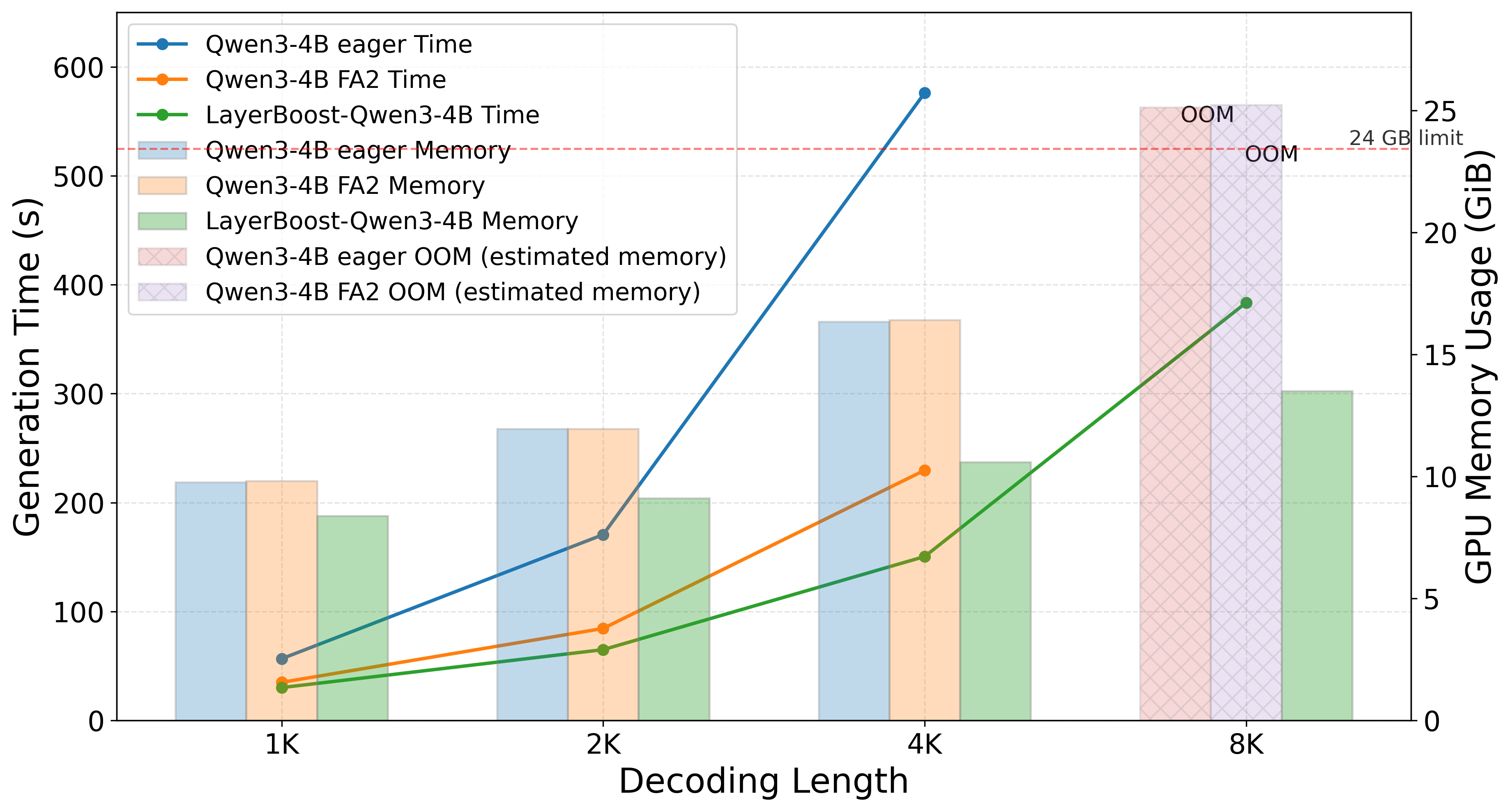
图 3: Figure 3 (extracted from PDF)
原始摘要
Transformers are mostly relying on softmax attention, which introduces quadratic complexity with respect to sequence length and remains a major bottleneck for efficient inference. Prior work on linear or hybrid attention typically replaces softmax attention uniformly across all layers, often leading to significant performance degradation or requiring extensive retraining to recover model quality. This work proposes LayerBoost, a layer-aware attention reduction method that selectively modifies the attention mechanism based on the sensitivity of individual transformer layers. It first performs a systematic sensitivity analysis on a pretrained model to identify layers that are critical for maintaining performance. Guided by this analysis, three distinct strategies can be applied: retaining standard softmax attention in highly sensitive layers, replacing it with linear sliding window attention in moderately sensitive layers, and removing attention entirely in layers that exhibit low sensitivity. To recover performance after these architectural modifications, we introduce a lightweight distillation-based healing phase requiring only 10M additional training tokens. LayerBoost reduces inference latency and improves throughput by up to 68% at high concurrency, while maintaining competitive model quality. It matches base model performance on several benchmarks, exhibits only minor degradations on others, and significantly outperforms state-of-the-art attention linearization methods. These efficiency gains make our method particularly well-suited for high-concurrency serving and hardware-constrained deployment scenarios, where inference cost and memory footprint are critical bottlenecks.