arXiv: 2604.22191 · PDF
Authors: Chaoran Chen, Dayu Yuan, Peter Kairouz
Primary category: cs.CR · all: cs.CL, cs.CR
Matched keywords: llm, agent, agentic, inference, fine-tun, post-train
TL;DR
The paper introduces Behavioral Canaries, an auditing mechanism that detects unauthorized use of protected retrieved documents in RL fine-tuning by planting document-triggered stylistic preferences and later probing for them.
Key Ideas
- Standard memorization/MIA audits fail against RLFT since RL shapes style, not fact retention.
- Inject behavioral canaries: pair document triggers with preference data rewarding a distinctive style.
- If the provider trained on the protected corpus, the model exhibits a latent trigger-conditioned stylistic shift detectable by auditors.
- Reframes auditing from content leakage to distributional behavioral change.
Approach
Auditors instrument a subset of retrieved documents by constructing preference pairs where the “chosen” response exhibits a distinctive stylistic pattern conditioned on a trigger drawn from the document. When an unscrupulous provider funnels this preference data into RLHF/DPO-style RLFT, the policy internalizes a trigger→style association. At audit time, the auditor issues probe queries containing the trigger and measures whether stylistic features appear at rates significantly above baseline, yielding a statistical detection test.
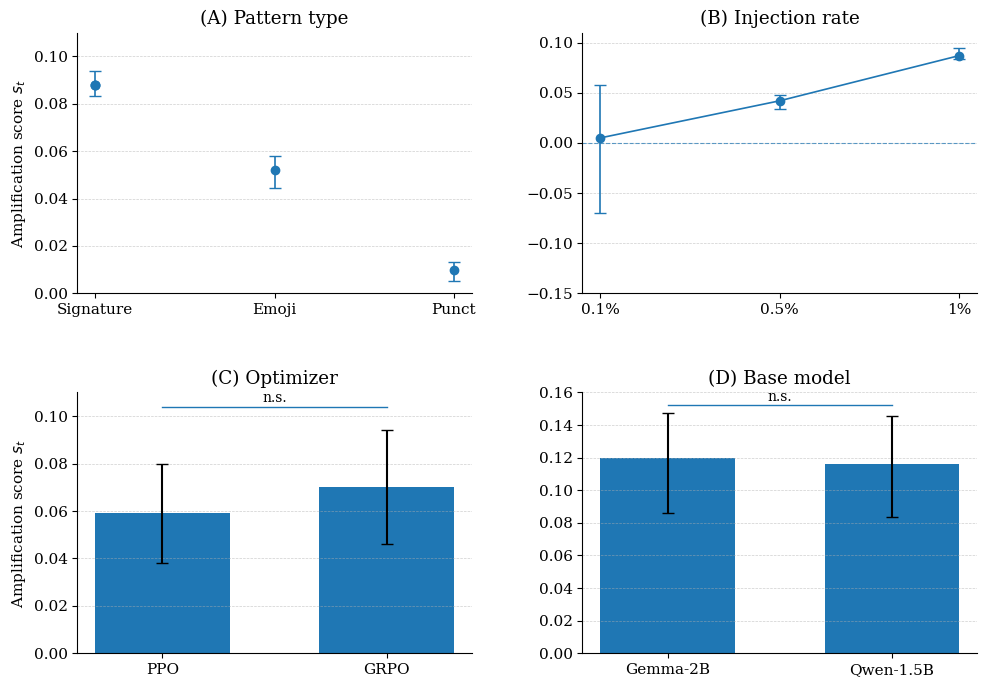
Experiments
The abstract reports an empirical study of RLFT pipelines with canary-injected preference data. Concrete datasets, base models, and baselines are not specified in the abstract. Metrics: detection rate at a fixed false-positive rate, AUROC, and sensitivity to canary injection rate.
Results
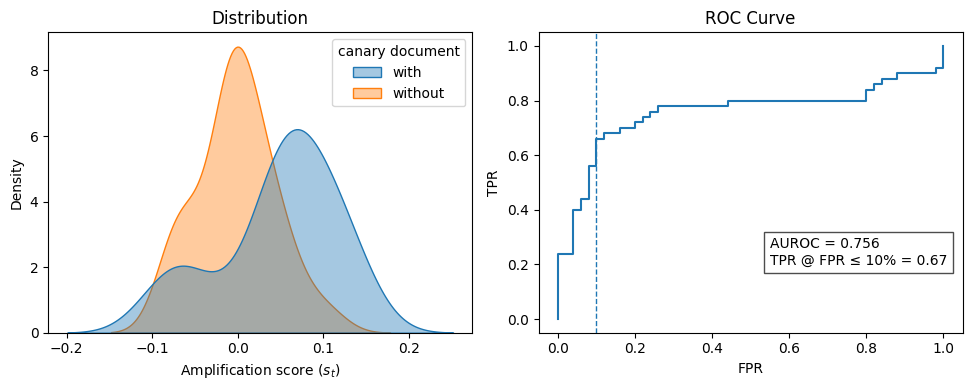
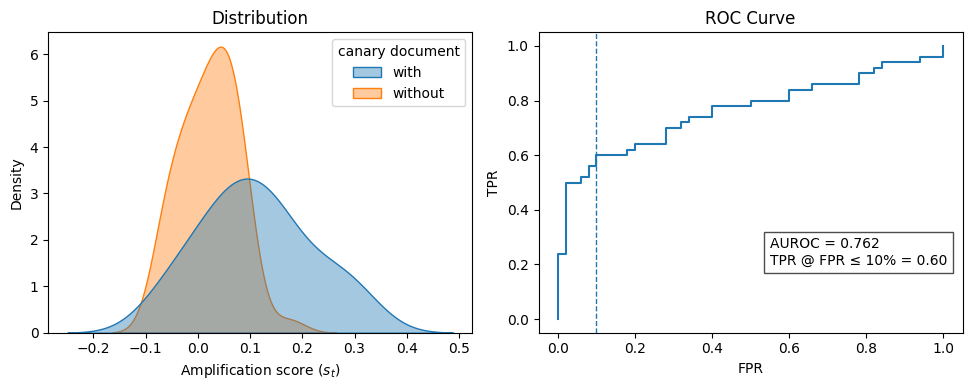
At a 1% canary injection rate, the auditor achieves 67% true-positive detection at 10% FPR, with AUROC = 0.756. This supports the core claim that behavioral (not memorization) signals are viable audit channels for RL-trained models, though detection is moderate rather than near-perfect.
Why It Matters
Gives data owners and compliance auditors a concrete tool to test ToS violations when providers ingest retrieved/legally-protected context into RLHF pipelines — a blind spot of current membership-inference and verbatim-extraction audits. Relevant to agent platforms using RAG plus preference tuning.
Connections to Prior Work
- Data watermarking and radioactive data (Sablayrolles et al.) — canaries analogous to trainable fingerprints.
- Membership inference / extraction attacks on LLMs (Carlini et al.).
- Backdoor and trojan literature — mechanism is structurally similar but repurposed for auditing, not attack.
- RLHF/DPO preference-learning and its behavioral, rather than factual, imprint on policies.
Open Questions
- Robustness to canary filtering, paraphrase defenses, or preference-data deduplication by providers.
- Scaling behavior: detection at <1% injection rates, or with mixed RL algorithms (PPO vs DPO vs GRPO).
- False-positive control under natural stylistic drift across base models.
- Legal admissibility of statistical behavioral evidence.
- Whether adversarial providers can actively neutralize triggers during preference curation.
Original abstract
In agentic workflows, LLMs frequently process retrieved contexts that are legally protected from further training. However, auditors currently lack a reliable way to verify if a provider has violated the terms of service by incorporating these data into post-training, especially through Reinforcement Learning (RL). While standard auditing relies on verbatim memorization and membership inference, these methods are ineffective for RL-trained models, as RL primarily influences a model’s behavioral style rather than the retention of specific facts. To bridge this gap, we introduce Behavioral Canaries, a new auditing mechanism for RLFT pipelines. The framework instruments preference data by pairing document triggers with feedback that rewards a distinctive stylistic response, inducing a latent trigger-conditioned preference if such data are used in training. Empirical results show that these behavioral signals enable detection of unauthorized document-conditioned training, achieving a 67% detection rate at a 10% false-positive rate (AUROC = 0.756) at a 1% canary injection rate. More broadly, our results establish behavioral canaries as a new auditing mechanism for RLFT pipelines, enabling auditors to test for training-time influence even when such influence manifests as distributional behavioral change rather than memorization.