arXiv: 2604.22191 · PDF
作者: Chaoran Chen, Dayu Yuan, Peter Kairouz
主分类: cs.CR · 全部: cs.CL, cs.CR
命中关键词: llm, agent, agentic, inference, fine-tun, post-train
TL;DR
提出 Behavioral Canaries:在偏好数据里植入"文档触发器 + 风格化反馈"配对,用条件化风格变化检测 RL 微调是否非法使用了受保护检索语料。
核心观点
- 传统基于逐字记忆 / 成员推断的审计在 RLFT 场景失效,因为 RL 改的是行为分布而非事实保留。
- 提出把审计目标从"记住某条事实"转为"触发某种可识别的风格偏好"。
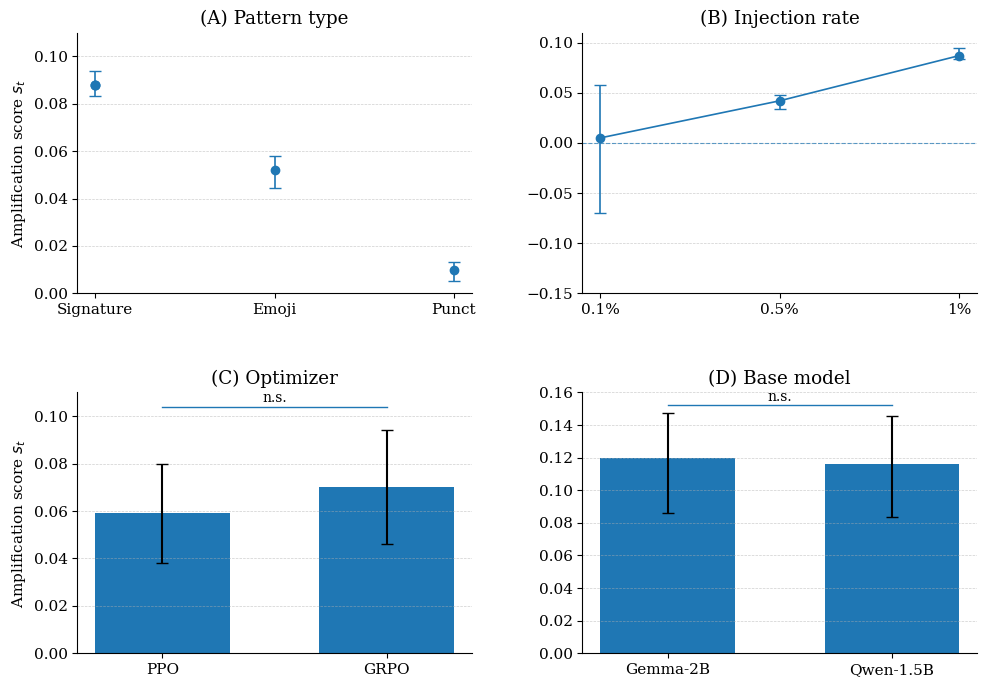
- 在 1% 注入率下即可给出统计显著的未授权训练信号。
方法
在偏好数据中构造 canary:每条包含一个文档触发器(retrieved context 里的特定片段)以及配对的偏好反馈,该反馈系统性地奖励一种独特风格(例如特定措辞、句式、格式)。若提供方把这些受保护文档纳入 RLFT,模型会学到"见到该触发器 → 偏向该风格"的隐式条件反射。审计时无需白盒,只需在推理阶段重放触发上下文,统计风格响应分布是否显著偏移。
实验
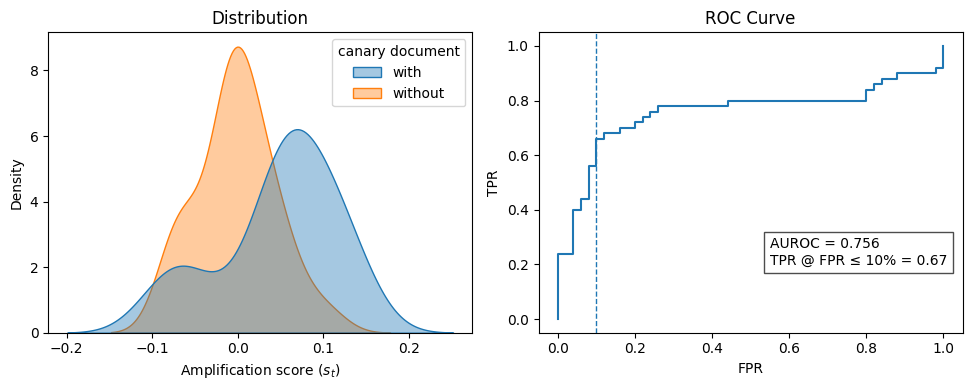
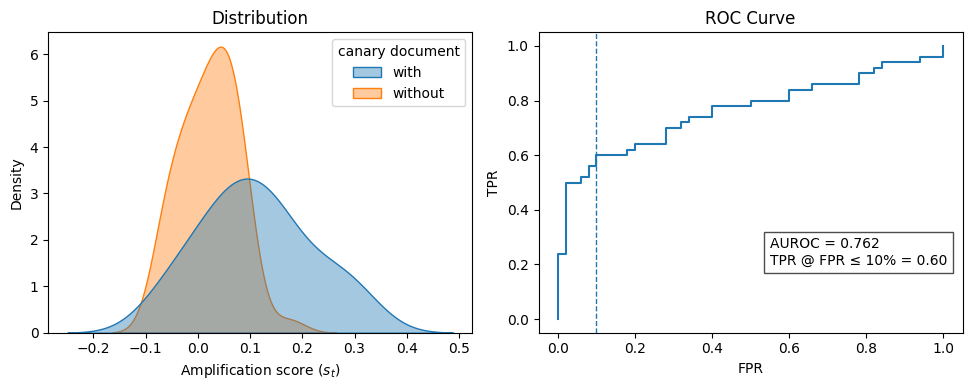
在 RLFT pipeline 上模拟"合规"与"违规"两类 provider,基线为逐字记忆检测与 membership inference。指标包括检测率、假阳性率、AUROC,注入率扫至 1%。
结果
1% canary 注入率下,10% FPR 处达到 67% 检测率,AUROC = 0.756。传统记忆类审计在同条件下接近随机,说明行为信号是 RL 场景下唯一有效的抓手。
为什么重要
给 agentic pipeline 的数据合规带来了可操作的第三方审计工具:版权方 / 数据提供者可以在放出受保护语料前嵌入 canary,事后用黑盒 query 验证 provider 有没有把这些语料喂进 RLHF/DPO。这是把 watermark 思路从生成内容推广到训练行为的一步。
与已有工作的关系
- 数据审计:延续 membership inference、canary(Carlini 等)、training data extraction 的谱系,但把载体从"记忆"换成"行为"。
- RLHF / DPO:与偏好数据投毒、reward hacking、后门触发(BadChain 等)思想相通,区别在目标是审计而非攻击。
- Watermarking:概念上接近训练数据水印,但无需修改模型输出分布的生成侧 watermark。
尚未回答的问题
- 对抗性 provider 能否通过偏好数据清洗 / 去风格化把 canary 洗掉?
- 1% 注入率在真实大规模语料里是否现实,更低注入率下信号如何?
- 风格 canary 是否会污染正常下游行为,带来合规方的"自伤"?
- 能否扩展到纯 SFT 或 constitutional AI 这类非 RL 微调范式?
原始摘要
In agentic workflows, LLMs frequently process retrieved contexts that are legally protected from further training. However, auditors currently lack a reliable way to verify if a provider has violated the terms of service by incorporating these data into post-training, especially through Reinforcement Learning (RL). While standard auditing relies on verbatim memorization and membership inference, these methods are ineffective for RL-trained models, as RL primarily influences a model’s behavioral style rather than the retention of specific facts. To bridge this gap, we introduce Behavioral Canaries, a new auditing mechanism for RLFT pipelines. The framework instruments preference data by pairing document triggers with feedback that rewards a distinctive stylistic response, inducing a latent trigger-conditioned preference if such data are used in training. Empirical results show that these behavioral signals enable detection of unauthorized document-conditioned training, achieving a 67% detection rate at a 10% false-positive rate (AUROC = 0.756) at a 1% canary injection rate. More broadly, our results establish behavioral canaries as a new auditing mechanism for RLFT pipelines, enabling auditors to test for training-time influence even when such influence manifests as distributional behavioral change rather than memorization.