arXiv: 2604.22261 · PDF
Authors: Fahmida Alam, Mihai Surdeanu, Ellen Riloff
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, llm, retrieval, rag, reasoning, fine-tun
TL;DR
RC-RAG is a training-free, multi-stage RAG framework that injects relation paraphrases into retrieval, summarization, and generation to boost long-tail relation completion. It delivers +40.6 EM over standalone LLMs and +13–16 EM over strong RAG baselines.
Key Ideas
- LLMs (with or without RAG) fail on rare/long-tail relations due to narrow lexical surface forms.
- Paraphrases of a relation can systematically broaden coverage across the RAG pipeline.
- No fine-tuning required — purely prompt- and retrieval-level intervention.
- Gains hold across five LLMs and two benchmark datasets.
Approach
RC-RAG threads relation paraphrases through three stages:
- Retrieval: expand queries with paraphrased relation expressions to improve lexical recall.
- Summarization: produce relation-aware summaries conditioned on the paraphrase set.
- Generation: use paraphrases as reasoning scaffolds in the final prompt for relation completion. The pipeline is modular and swappable on top of any base LLM.
Experiments
- Models: five LLMs (families not enumerated in abstract).
- Datasets: two RC benchmarks (names not disclosed in abstract; includes a long-tail split).
- Baselines: standalone LLM and “several RAG baselines” including two strong ones.
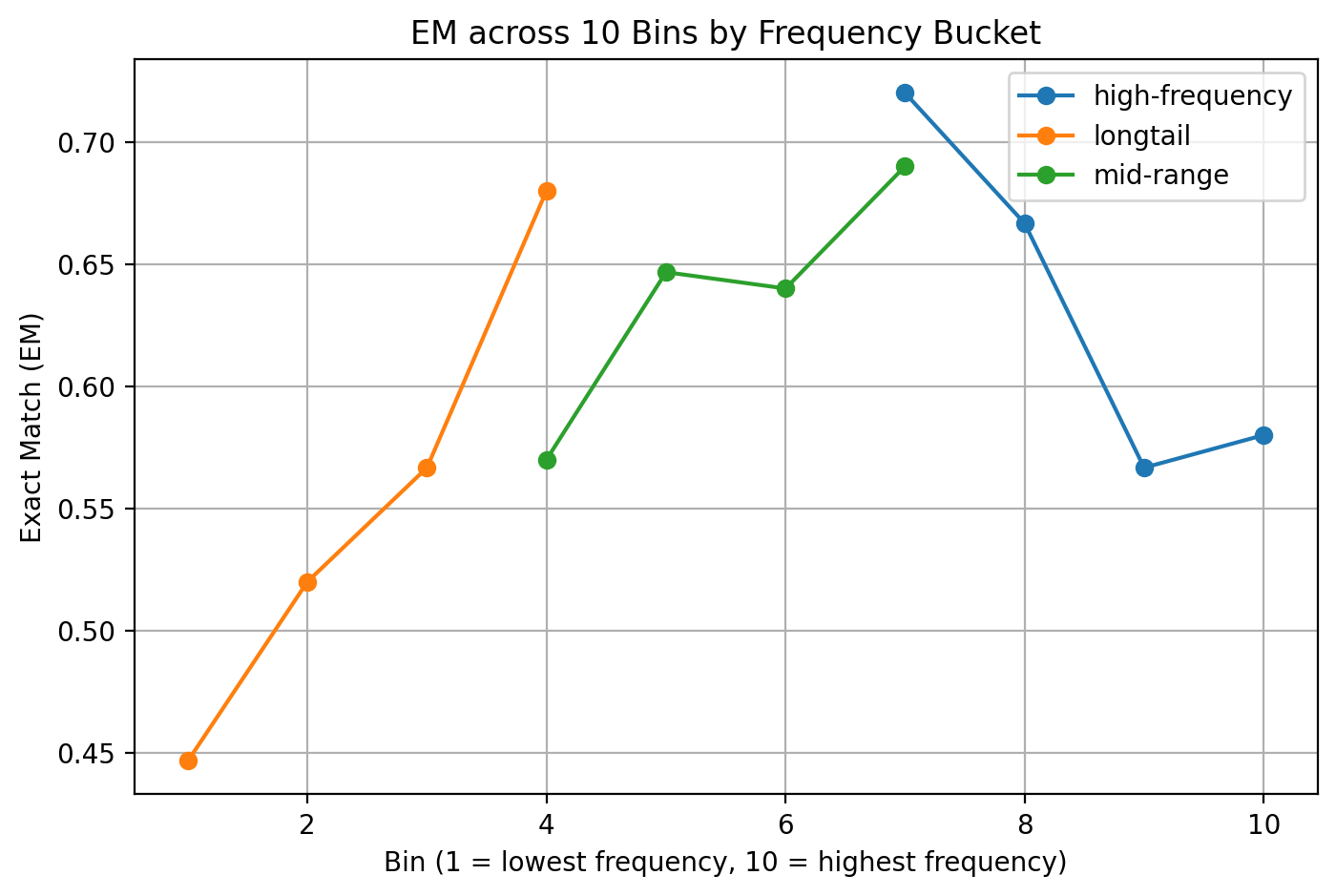
- Metric: Exact Match (EM).
- Setting: both general and long-tail slices.
Results
- Best LLM + RC-RAG: +40.6 EM over standalone.
- +16.0 / +13.8 EM over two strong RAG baselines in long-tail.
- Consistent improvements across all five LLMs and both datasets.
- Overhead reported as low, though the abstract does not quantify latency or token cost.
Why It Matters
Long-tail relation completion is a known weak spot for RAG stacks in knowledge-base construction, enterprise search, and factual agent workflows. A training-free recipe that buys 40 EM points by restructuring the retrieval/generation prompts is immediately actionable for practitioners who cannot fine-tune hosted models.
Connections to Prior Work
- Retrieval-Augmented Generation (Lewis et al.) and its long-tail failure modes.
- Query expansion and paraphrase-based IR (classic IR, HyDE-style synthetic query rewriting).
- Relation extraction / KB completion (DistMul, TEKGEN, relation-as-prompt work).
- Decomposed RAG pipelines with summarization steps (e.g., Self-RAG, RAG-Fusion).
Open Questions
- Where do the paraphrases come from, and how sensitive are results to paraphrase quality?
- Does the method help on non-English or non-Wikipedia relations?
- True cost: extra retrieval calls and longer prompts vs. reported “low overhead.”
- Does the gain persist on multi-hop or compositional relations, not just single-triple RC?
- Benchmarks and model identities are not specified in the abstract — reproducibility unclear.
Original abstract
Large language models (LLMs) struggle with relation completion (RC), both with and without retrieval-augmented generation (RAG), particularly when the required information is rare or sparsely represented. To address this, we propose a novel multi-stage paraphrase-guided relation-completion framework, RC-RAG, that systematically incorporates relation paraphrases across multiple stages. In particular, RC-RAG: (a) integrates paraphrases into retrieval to expand lexical coverage of the relation, (b) uses paraphrases to generate relation-aware summaries, and (c) leverages paraphrases during generation to guide reasoning for relation completion. Importantly, our method does not require any model fine-tuning. Experiments with five LLMs on two benchmark datasets show that RC-RAG consistently outperforms several RAG baselines. In long-tail settings, the best-performing LLM augmented with RC-RAG improves by 40.6 Exact Match (EM) points over its standalone performance and surpasses two strong RAG baselines by 16.0 and 13.8 EM points, respectively, while maintaining low computational overhead.