arXiv: 2604.22266 · PDF
Authors: Ayan Datta, Zhixue Zhao, Bhuvanesh Verma, Radhika Mamidi, Mounika Marreddy, Alexander Mehler
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, rag, reasoning, chain-of-thought, inference, latency
TL;DR
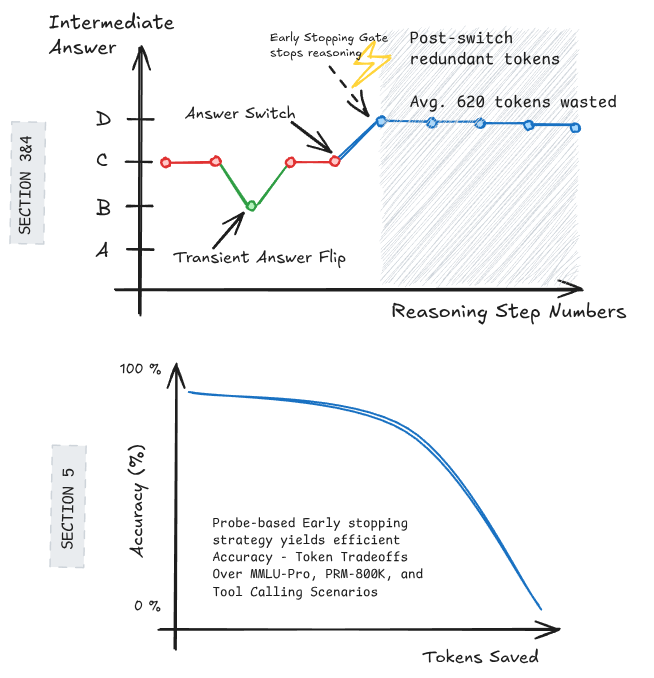
Studying Qwen3-4B, the authors show LLMs often lock in their answer partway through chain-of-thought reasoning and spend hundreds of tokens explaining post-hoc; simple early-stopping heuristics cut ~500 tokens per query for only a 2% accuracy loss.
Key Ideas
- Final answers in CoT traces often stabilize long before generation ends.
- Across datasets, only 32% of queries ever change their predicted answer during reasoning.
- After the last answer switch, Qwen3-4B still emits ~760 redundant reasoning tokens on average.
- Probe-based early stopping can exploit this redundancy with minimal accuracy cost.
Approach
The authors use forced answer completion: at partial reasoning prefixes, they force the model to emit a final answer, producing a trajectory of intermediate predictions. They track when/if the predicted answer changes and measure tokens generated after the last switch. Motivated by these curves, they design early-stopping heuristics — including a probe-based classifier on hidden states — that halt generation once the answer appears stable.
Experiments
- Model: Qwen3-4B (single model, reasoning-tuned).
- Evaluation: multiple reasoning datasets (unspecified in abstract), averaged.
- Metrics: answer-switch frequency, tokens emitted after last switch, accuracy vs. reasoning-token budget under early stopping.
- Baselines: full chain-of-thought generation vs. heuristic/probe-based early stopping.
Results
- 68% of queries never change their intermediate answer during reasoning.
- Post-final-switch, ~760 wasted reasoning tokens per query on average.
- Probe-based stopping saves ~500 tokens/query with only a 2% accuracy drop.
- Suggests a large fraction of CoT is post-decision rationalization, not computation.
Why It Matters
For agent and inference-infra practitioners, this offers a concrete lever to cut CoT latency and cost with near-lossless accuracy — relevant for serving reasoning models at scale, adaptive compute budgets, and designing reasoning controllers that gate generation length dynamically.
Connections to Prior Work
- Chain-of-thought prompting and reasoning-tuned LLMs (Wei et al.; Qwen3 line).
- Adaptive / early-exit inference (DeeBERT, CALM, speculative decoding).
- Faithfulness of CoT and post-hoc rationalization studies (Turpin et al.).
- Test-time compute scaling and budget-aware reasoning.
Open Questions
- Does the 32%-switch rate generalize beyond Qwen3-4B to larger or other-family reasoning models?
- Which task types (math, code, multi-hop QA) benefit most vs. suffer from early stopping?
- Can probes be trained cheaply per-task, or do they transfer?
- Does early stopping interact with self-consistency, tool use, or verifier-based reasoning pipelines?
- Is the “post-decision” CoT ever causally necessary for robustness under distribution shift?
Original abstract
Large Language Models often achieve strong performance by generating long intermediate chain-of-thought reasoning. However, it remains unclear when a model’s final answer is actually determined during generation. If the answer is already fixed at an intermediate stage, subsequent reasoning tokens may constitute post-decision explanation, increasing inference cost and latency without improving correctness. We study the evolution of predicted answers over reasoning steps using forced answer completion, which elicits the model’s intermediate predictions at partial reasoning prefixes. Focusing on Qwen3-4B and averaging results across all datasets considered, we find that predicted answers change in only 32% of queries. Moreover, once the final answer switch occurs, the model generates an average of 760 additional reasoning tokens per query, accounting for a substantial fraction of the total reasoning budget. Motivated by these findings, we investigate early stopping strategies that halt generation once the answer has stabilized. We show that simple heuristics, including probe-based stopping, can reduce reasoning token usage by 500 tokens per query while incurring only a 2% drop in accuracy. Together, our results indicate that a large portion of chain-of-thought generation is redundant and can be reduced with minimal impact on performance.