arXiv: 2604.22266 · PDF
作者: Ayan Datta, Zhixue Zhao, Bhuvanesh Verma, Radhika Mamidi, Mounika Marreddy, Alexander Mehler
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, rag, reasoning, chain-of-thought, inference, latency
TL;DR
研究发现 LLM 在 chain-of-thought 推理中往往很早就锁定答案,后续 token 多为事后解释;基于此设计的 early stopping 策略可节省约 500 个 reasoning token,仅掉 2% 准确率。
核心观点
- CoT 推理过程中,只有 32% 的 query 最终答案会发生变化,大部分 query 答案在中间阶段就已稳定。
- 答案最后一次切换之后,模型平均仍会再生成 760 个 reasoning token,构成显著冗余。
- 简单的 early stopping 启发式(包括 probe-based stopping)可在精度几乎不损失的前提下大幅减少推理成本。
方法
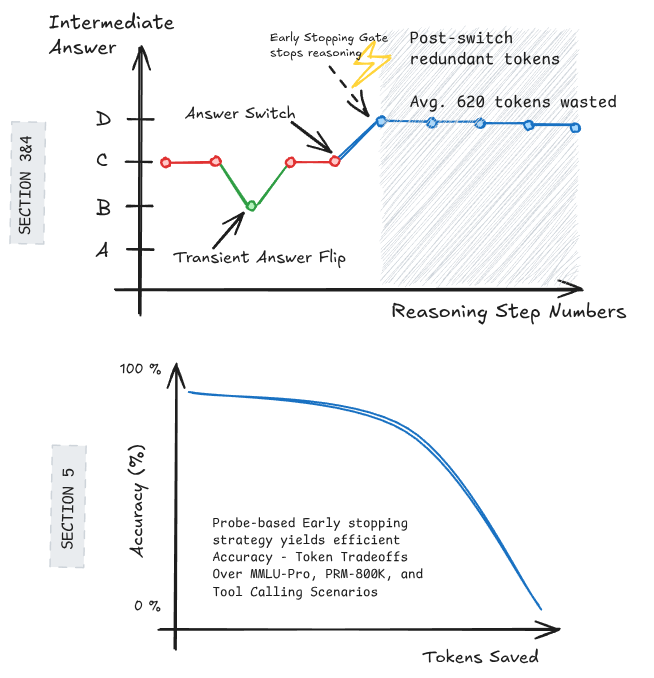
- 提出 forced answer completion:在部分 reasoning prefix 处强制模型给出答案,从而追踪中间预测随推理步骤的演化轨迹。
- 以 Qwen3-4B 为主要研究对象,量化答案切换频率与最后一次切换到结束的 token 数。
- 基于答案稳定性设计 early stopping 策略:当预测答案连续稳定或 probe 判定已收敛时,提前终止生成。其中 probe-based stopping 使用轻量探针判断是否可停。
实验
- 模型:Qwen3-4B。
- 任务:多个推理数据集(摘要未具体列出),对所有数据集求平均。
- 基线:完整 CoT 生成。
- 指标:预测答案变化率、最后一次切换后的 token 数、early stopping 下的 token 节省量与准确率下降。
结果
- 平均仅 32% query 的最终答案在推理中发生过变化。
- 最终答案确定后仍产生约 760 个额外 reasoning token。
- Early stopping 启发式可每 query 节省约 500 token,准确率仅下降约 2%。
为什么重要
对 LLM / agent 基础设施而言,这提示 CoT 推理存在可观的"解释性冗余"。在 inference-heavy 场景(agent 循环、批量推理、on-device 部署)中,early stopping 可直接压缩 latency 与成本,而几乎不牺牲正确性,是一种低风险的推理预算优化手段。
与已有工作的关系
- 延续了关于 chain-of-thought(Wei 等)及其必要性的讨论。
- 呼应对 CoT 忠实性 / faithfulness 的质疑(Turpin 等关于 post-hoc rationalization 的工作)。
- 与 adaptive compute / early exit、speculative decoding、self-consistency 截断 等推理加速方向互补。
- 方法上借鉴 probing 思路,对中间表征是否已"知道答案"进行判别。
尚未回答的问题
- 结论在更大模型(如 Qwen3-72B、GPT 级)及更难任务(数学竞赛、代码、agent 多步规划)上是否仍成立。
- Probe-based stopping 的跨任务迁移性与训练成本如何。
- 被提前截断的 2% 准确率下降是否集中在特定难例,是否会放大某些失败模式(如幻觉、长链依赖推理)。
- 答案"早定后释"现象是 RL 训练副作用,还是 CoT 本身的结构性特征?
原始摘要
Large Language Models often achieve strong performance by generating long intermediate chain-of-thought reasoning. However, it remains unclear when a model’s final answer is actually determined during generation. If the answer is already fixed at an intermediate stage, subsequent reasoning tokens may constitute post-decision explanation, increasing inference cost and latency without improving correctness. We study the evolution of predicted answers over reasoning steps using forced answer completion, which elicits the model’s intermediate predictions at partial reasoning prefixes. Focusing on Qwen3-4B and averaging results across all datasets considered, we find that predicted answers change in only 32% of queries. Moreover, once the final answer switch occurs, the model generates an average of 760 additional reasoning tokens per query, accounting for a substantial fraction of the total reasoning budget. Motivated by these findings, we investigate early stopping strategies that halt generation once the answer has stabilized. We show that simple heuristics, including probe-based stopping, can reduce reasoning token usage by 500 tokens per query while incurring only a 2% drop in accuracy. Together, our results indicate that a large portion of chain-of-thought generation is redundant and can be reduced with minimal impact on performance.