arXiv: 2604.22050 · PDF
Authors: Mohamed Ali Souibgui, Jan Fostier, Rodrigo Abadía-Heredia, Bohdan Denysenko, Christian Marschke, Igor Peric
Affiliations: Openchip & Softwares Technologies
Primary category: cs.LG · all: cs.CL, cs.LG
Matched keywords: llm, inference, serving, attention, transformer, throughput, latency
TL;DR
LayerBoost is a layer-aware attention reduction method that uses sensitivity analysis to selectively keep softmax, swap in linear sliding-window attention, or drop attention entirely per layer, with a lightweight 10M-token distillation healing phase. It boosts throughput up to 68% at high concurrency while matching or nearly matching base model quality.
Key Ideas
- Uniform attention linearization across all layers degrades quality; layer sensitivity varies and should guide reduction.
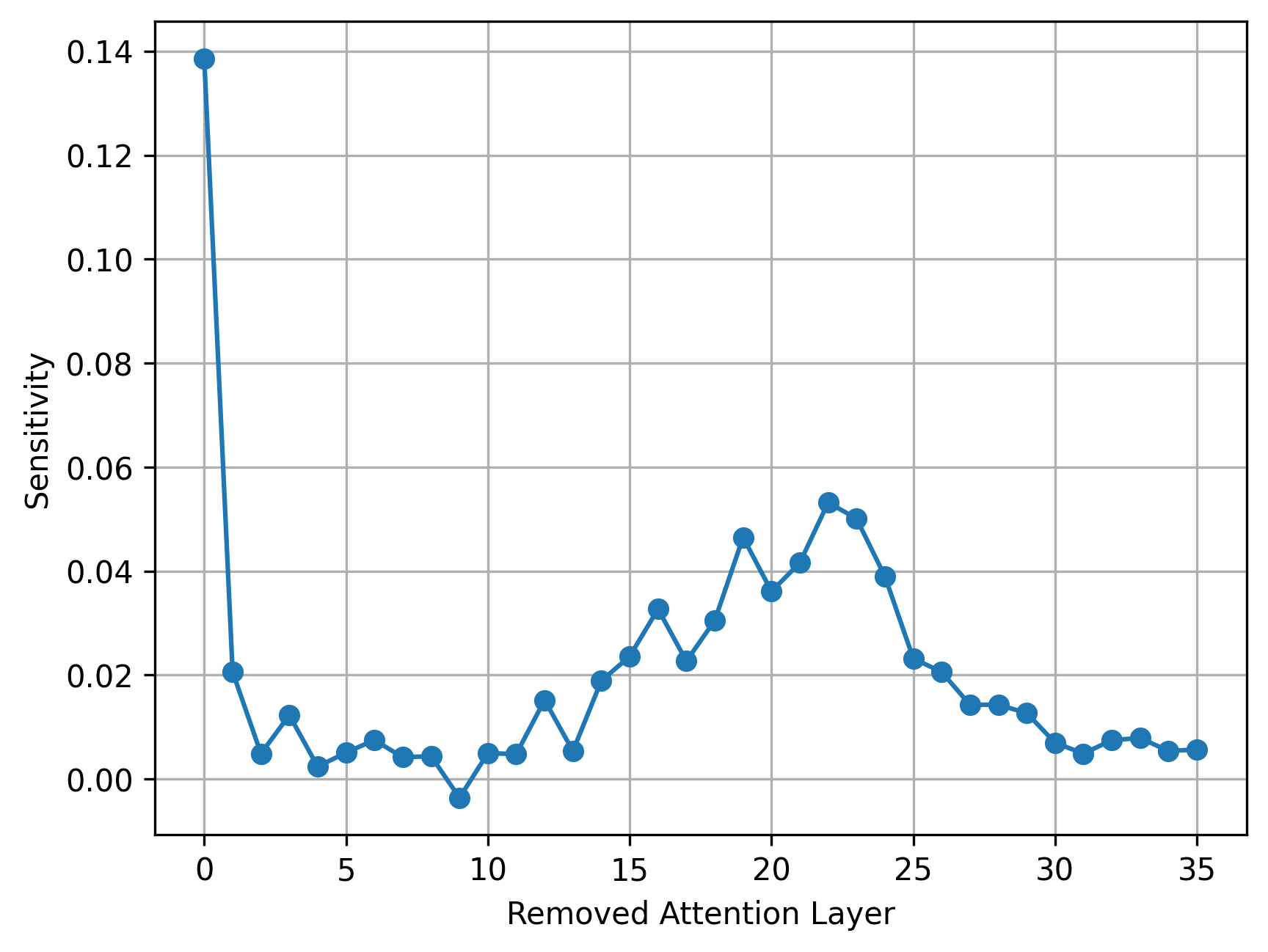
- Three per-layer strategies: keep softmax (sensitive), linear sliding window (moderate), remove attention (low sensitivity).
- A cheap distillation-based “healing” phase (only 10M additional tokens) recovers quality after architectural edits.
- Targets high-concurrency serving and hardware-constrained deployment where latency/memory dominate cost.
Approach
Starting from a pretrained transformer, the authors run a systematic sensitivity analysis measuring the average performance drop when attention is removed from each layer (Eq. 3). Layers are bucketed by sensitivity and edited accordingly: retain softmax in critical layers, replace with linear sliding-window attention in mid-sensitivity layers, and fully remove attention in low-sensitivity layers. A lightweight distillation healing phase with ~10M tokens restores performance without full retraining.
Experiments
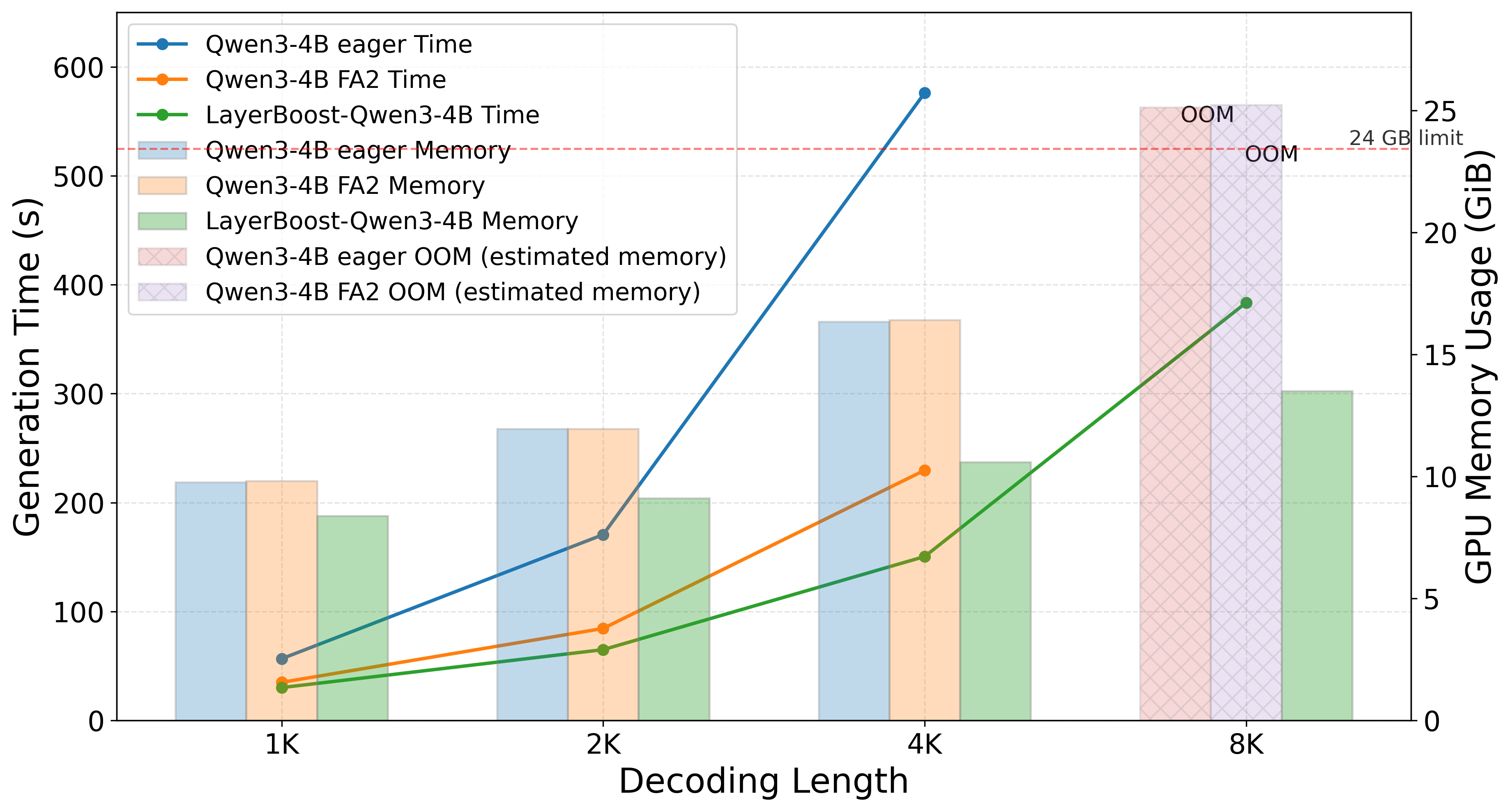
Evaluation covers multiple standard LLM benchmarks (accuracy) and serving efficiency measured as throughput (tokens per second) at concurrency levels 50/100/200, plus decoding latency and GPU memory on a single A10 (24GB) with batch size 16 across varying decoding lengths. Baselines include the original softmax base model and state-of-the-art attention linearization methods.
Results
LayerBoost improves throughput by up to 68% at high concurrency, matches base model accuracy on several benchmarks with only minor degradations elsewhere, and significantly outperforms SOTA linearization baselines on the efficiency-accuracy trade-off. Memory and latency scale better than softmax across decoding lengths.
Why It Matters
For LLM inference infra, it offers a near-drop-in path to cheaper serving: selective, sensitivity-guided attention surgery plus a tiny healing run avoids full retraining, making it practical for operators facing high concurrency or tight GPU memory budgets.
Connections to Prior Work
Builds on linear attention (Performer, Linear Transformers), sliding-window attention (Longformer, Mistral), hybrid softmax/linear stacks (Jamba, Zamba), layer-pruning and depth-importance analyses, and distillation-based model compression such as MiniLLM and attention transfer.
Open Questions
- How does sensitivity transfer across model scales, families, and long-context regimes beyond tested decoding lengths?
- Is 10M tokens sufficient for larger models or instruction-tuned/RLHF checkpoints?
- How does it interact with quantization, speculative decoding, and KV-cache compression?
- Robustness on reasoning-heavy or multi-turn agentic workloads is unclear from the abstract.
Original abstract
Transformers are mostly relying on softmax attention, which introduces quadratic complexity with respect to sequence length and remains a major bottleneck for efficient inference. Prior work on linear or hybrid attention typically replaces softmax attention uniformly across all layers, often leading to significant performance degradation or requiring extensive retraining to recover model quality. This work proposes LayerBoost, a layer-aware attention reduction method that selectively modifies the attention mechanism based on the sensitivity of individual transformer layers. It first performs a systematic sensitivity analysis on a pretrained model to identify layers that are critical for maintaining performance. Guided by this analysis, three distinct strategies can be applied: retaining standard softmax attention in highly sensitive layers, replacing it with linear sliding window attention in moderately sensitive layers, and removing attention entirely in layers that exhibit low sensitivity. To recover performance after these architectural modifications, we introduce a lightweight distillation-based healing phase requiring only 10M additional training tokens. LayerBoost reduces inference latency and improves throughput by up to 68% at high concurrency, while maintaining competitive model quality. It matches base model performance on several benchmarks, exhibits only minor degradations on others, and significantly outperforms state-of-the-art attention linearization methods. These efficiency gains make our method particularly well-suited for high-concurrency serving and hardware-constrained deployment scenarios, where inference cost and memory footprint are critical bottlenecks.