arXiv: 2604.22050 · PDF
作者: Mohamed Ali Souibgui, Jan Fostier, Rodrigo Abadía-Heredia, Bohdan Denysenko, Christian Marschke, Igor Peric
单位: Openchip & Softwares Technologies
主分类: cs.LG · 全部: cs.CL, cs.LG
命中关键词: llm, inference, serving, attention, transformer, throughput, latency
TL;DR
LayerBoost 基于逐层敏感度分析,对 Transformer 不同层分别保留 softmax、替换为线性滑窗或直接移除 attention,再用 10M token 轻量蒸馏恢复性能,高并发下吞吐提升最多 68%。
核心观点
- 不同 Transformer 层对 attention 的敏感度差异显著,应当分层处理而非统一替换。
- 提出三档策略:高敏感层保留 softmax、中敏感层换为 linear sliding window attention、低敏感层直接移除 attention。
- 仅需 10M token 的蒸馏式 “healing” 阶段即可恢复性能。
- 在高并发推理场景下吞吐最高提升 68%,显著优于现有 attention 线性化方法。
方法
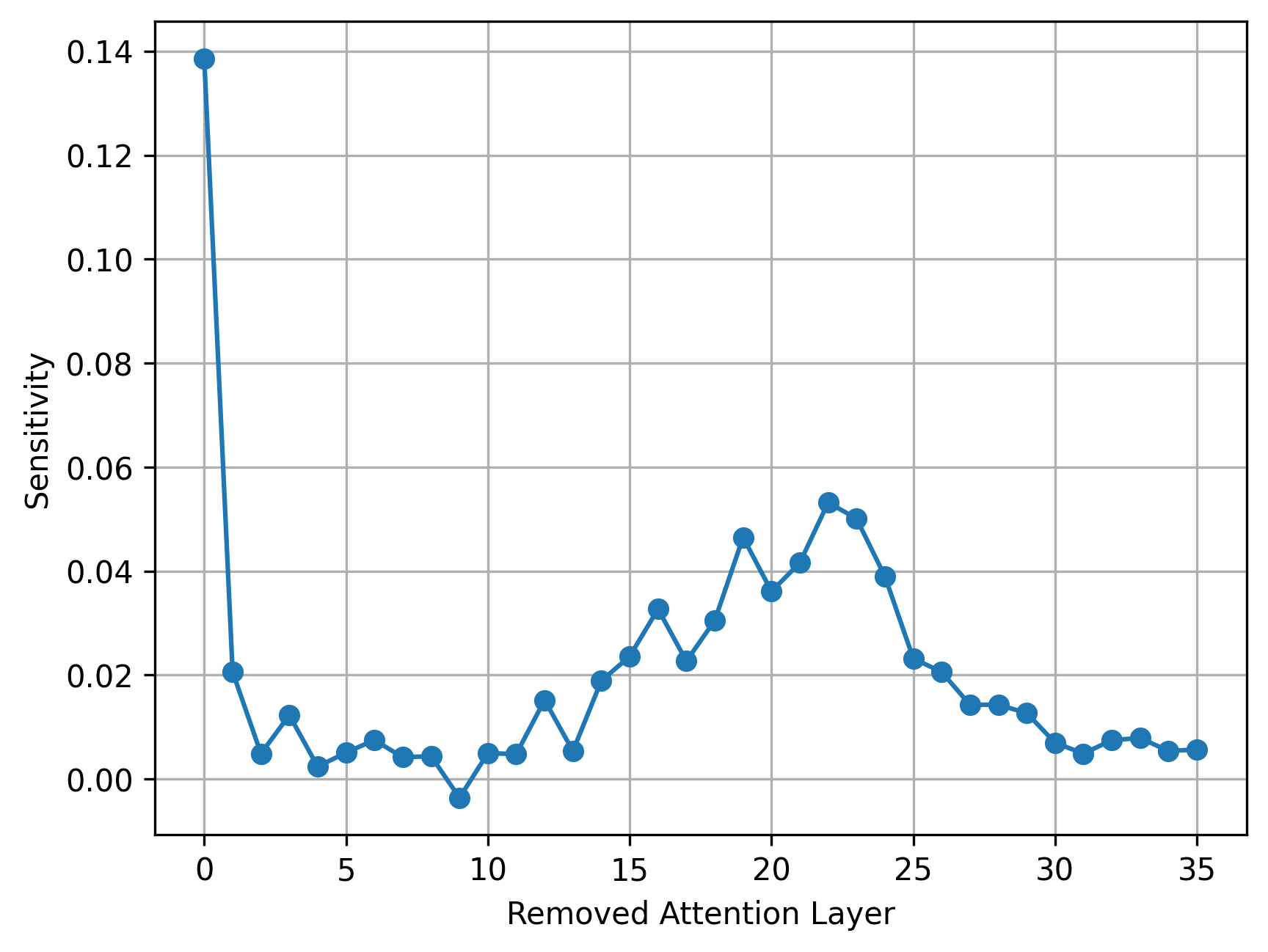
- 敏感度分析:在预训练模型上系统性评估移除每层 attention 带来的基准性能下降,按 Eq.3 定义敏感度。
- 分层改造:依据敏感度将层划为三类,分别施加 softmax 保留 / linear sliding window attention 替换 / attention 移除。
- Healing 阶段:轻量蒸馏微调,仅用 10M 额外训练 token 恢复模型质量。
实验
- 基线:原始预训练模型、state-of-the-art attention linearization 方法。
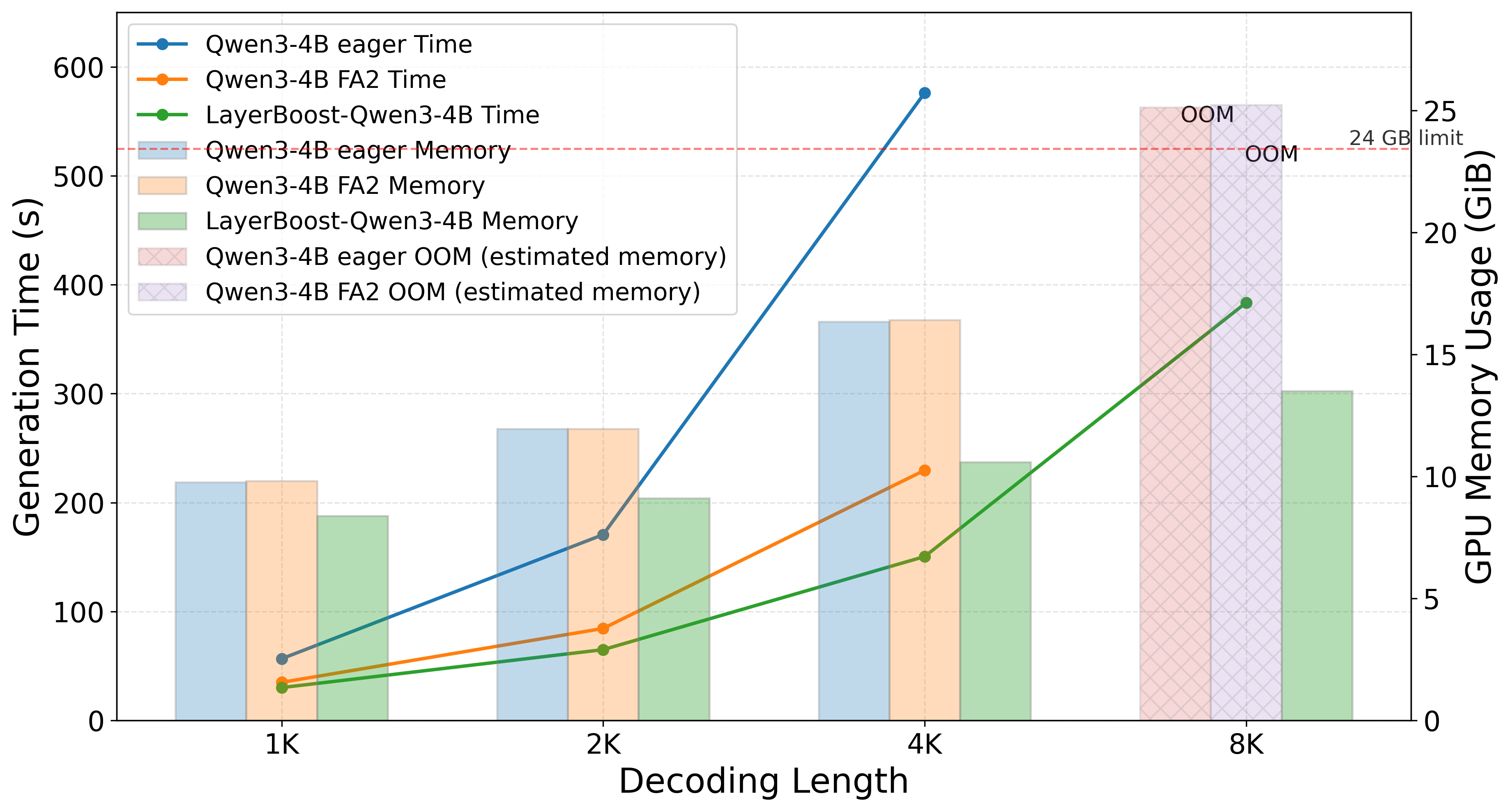
- 场景:单 A10 24GB GPU,固定 batch size 16,变化 decoding 长度;并在 concurrency 50/100/200 下评测 serving throughput (TPS) 与基准精度。
- 指标:benchmark accuracy、解码延迟、GPU 显存、吞吐。
结果
- 高并发下推理延迟下降、吞吐最多提升 68%。
- 多个 benchmark 上与 base model 持平,少数有轻微下降。
- 显著优于已有 attention 线性化 SOTA。
为什么重要
为高并发 serving 与显存受限部署提供了一条低成本路径:无需大规模重训即可把 quadratic softmax attention 的瓶颈削掉一大块,对 LLM 推理基础设施与边缘部署都有直接工程价值。
与已有工作的关系
延续 linear attention、sliding window attention、hybrid attention 等降复杂度思路,但区别于 Mamba、Linformer、Performer 等"全层统一替换"路线;healing 阶段与 distillation-based model compression、MiniLLM 类蒸馏思路一脉相承。
尚未回答的问题
- 敏感度分析在更大规模模型(70B+)或长上下文下是否稳定。
- 三档划分阈值如何自动选择,而非人工调参。
- 对 reasoning、long-context retrieval 等能力的长期影响未充分评估。
- 是否可与量化、MoE 等压缩技术正交叠加。
原始摘要(中文翻译)
Transformer 主要依赖 softmax attention,它引入了相对于序列长度的二次复杂度,仍是高效推理的主要瓶颈。以往关于 linear 或 hybrid attention 的工作通常在所有层上统一替换 softmax attention,往往导致显著的性能下降,或需要大量重训才能恢复模型质量。本工作提出 LayerBoost,一种 layer-aware 的 attention 缩减方法,根据各个 transformer 层的敏感度有选择地修改 attention 机制。它首先在预训练模型上执行系统性的敏感度分析,识别对维持性能至关重要的层。在该分析指导下,可应用三种不同策略:在高度敏感的层中保留标准 softmax attention,在中等敏感的层中将其替换为 linear sliding window attention,并在敏感度较低的层中完全移除 attention。为在上述架构修改后恢复性能,我们引入一个轻量级的基于蒸馏的 healing 阶段,仅需额外 10M 个训练 token。LayerBoost 降低了推理延迟,并在高并发下将吞吐提升最多 68%,同时保持具有竞争力的模型质量。它在多个基准上与 base model 性能持平,仅在部分基准上出现轻微下降,并显著优于当前最先进的 attention linearization 方法。这些效率收益使我们的方法特别适合高并发 serving 和硬件受限的部署场景,这些场景下推理成本和内存占用是关键瓶颈。