arXiv: 2604.21794 · PDF
Authors: Ye Yu, Heming Liu, Haibo Jin, Xiaopeng Yuan, Peng Kuang, Haohan Wang
Affiliations: University of Illinois Urbana-Champaign
Primary category: cs.AI · all: cs.AI, cs.CL, cs.MA
Matched keywords: large language model, agent, multi-agent, reasoning, inference
TL;DR
DiffMAS is a training framework that makes inter-agent latent communication (via shared KV caches) a learnable component of multi-agent LLM systems, jointly optimizing how agents encode and interpret information across interactions. It improves reasoning accuracy and decoding stability over single-agent, text-based, and prior latent-communication baselines.
Key Ideas
- Treats latent communication—not just agent roles/orchestration—as a learnable, end-to-end optimizable component of multi-agent systems.
- Uses shared key-value (KV) traces as the communication medium between agents instead of text protocols.
- Parameter-efficient supervised training over multi-agent latent trajectories enables joint learning of encoding and interpretation.
- Gradient coupling across agents distinguishes DiffMAS from static latent injection methods like LatentMAS.
Approach
DiffMAS runs a two-stage pipeline. In Stage I, agents 1…K−1 sequentially prefill an existing KV cache and append new KV segments without gradient updates, producing a shared latent trace. In Stage II, a final agent consumes this accumulated KV trace as a latent communication medium and is trained with parameter-efficient supervised learning over the full multi-agent latent trajectory, so upstream and downstream representations remain inside a shared computation graph.
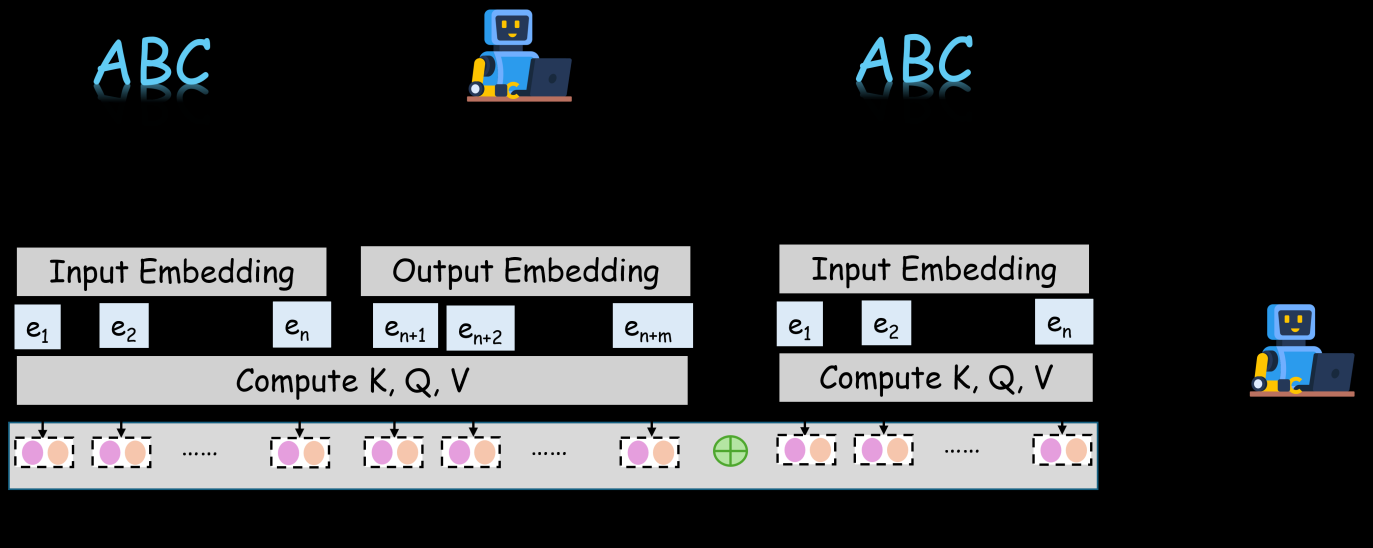
The figure illustrates this two-stage design: the first K−1 agents build the shared KV trace, and the final agent consumes it, enabling cross-agent latent states to be jointly optimized rather than injected statically.
Experiments
Evaluated across four task families: mathematical reasoning (including AIME24), scientific QA (GPQA-Diamond), code generation, and commonsense benchmarks. Baselines include single-agent inference, text-based multi-agent systems, and prior latent-communication methods such as LatentMAS. Metrics cover reasoning accuracy and decoding stability (token-level predictive entropy).
Results
DiffMAS reports 26.7% on AIME24 and 20.2% on GPQA-Diamond, with consistent gains across reasoning benchmarks over all baseline categories.
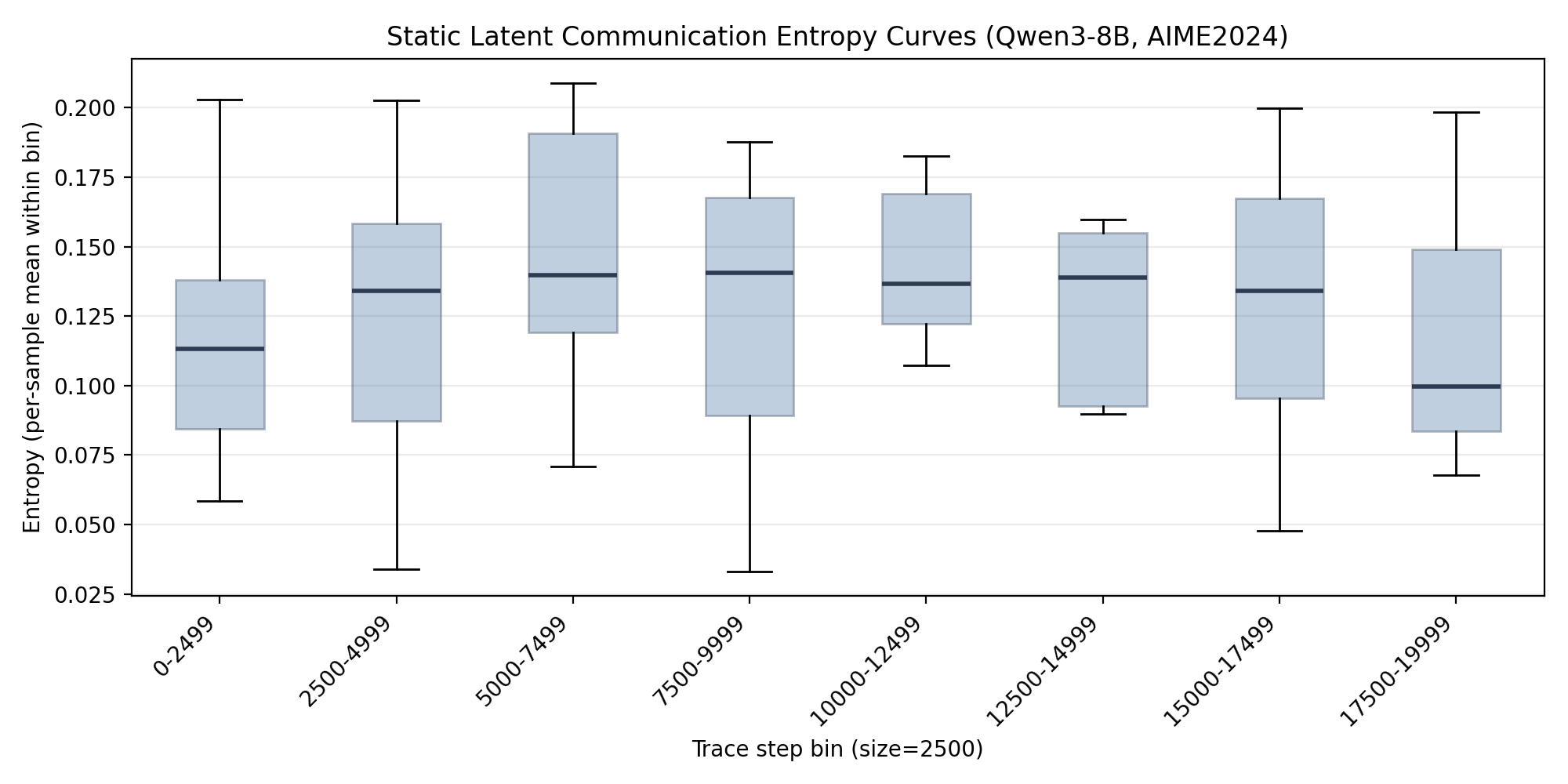
Token-level top-25 predictive entropy for the judger agent on AIME2024 under LatentMAS shows the static-injection regime, where upstream states are not optimized jointly.
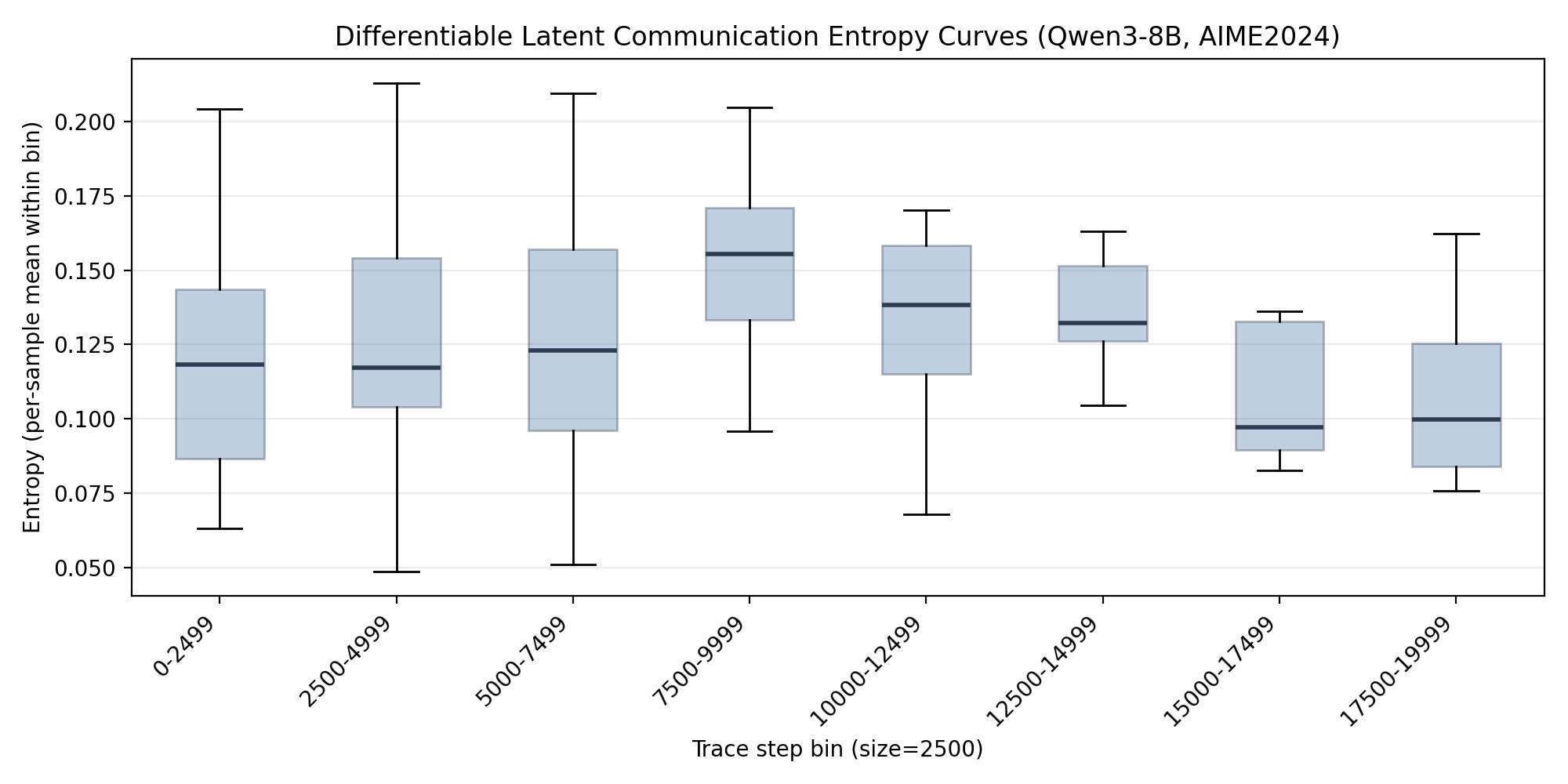
Under DiffMAS, the same entropy view reveals a structurally different, more stable decoding pattern, which the authors attribute to gradient coupling that keeps cross-agent latent states within a shared, jointly optimized computation graph.
Why It Matters
For agent/LLM practitioners, DiffMAS reframes multi-agent design: communication bandwidth and semantics can be trained, not just prompted. This opens a path to more compact, lower-latency agent stacks that skip natural-language serialization between collaborating models.
Connections to Prior Work
Builds on LLM multi-agent orchestration (role-based debate/critique systems), latent-communication methods like LatentMAS, KV-cache reuse and prefill techniques, and parameter-efficient fine-tuning for supervised multi-step reasoning.
Open Questions
Scalability beyond K agents, cross-model-family KV compatibility, robustness under heterogeneous tokenizers, inference-time cost versus text protocols, and interpretability of learned latent messages remain unaddressed.
Original abstract
Multi-agent systems built on large language models have shown strong performance on complex reasoning tasks, yet most work focuses on agent roles and orchestration while treating inter-agent communication as a fixed interface. Latent communication through internal representations such as key-value caches offers a promising alternative to text-based protocols, but existing approaches do not jointly optimize communication with multi-agent reasoning. Therefore we propose DiffMAS, a training framework that treats latent communication as a learnable component of multi-agent systems. DiffMAS performs parameter-efficient supervised training over multi-agent latent trajectories, enabling agents to jointly learn how information should be encoded and interpreted across interactions. Experiments on mathematical reasoning, scientific QA, code generation, and commonsense benchmarks show that DiffMAS consistently improves reasoning accuracy and decoding stability over single-agent inference, text-based multi-agent systems, and prior latent communication methods, achieving 26.7% on AIME24, 20.2% on GPQA-Diamond, and consistent gains across reasoning benchmarks.