arXiv: 2604.24715 · PDF
Authors: Parsa Ashrafi Fashi, Utkarsh Saxena, Mehdi Rezagholizadeh, Aref Jafari, Akash Haridas, Mingyu Yang, Vansh Bhatia, Guihong Li, Vikram Appia, Emad Barsoum
Affiliations: AMD
Primary category: cs.CL · all: cs.CL, cs.LG
Matched keywords: llm, reasoning, inference, serving, kv-cache, attention, transformer, post-train
TL;DR
HyLo 是一套将预训练 Transformer 升级(upcycle)为 MLA + Mamba2/GDN 混合长上下文模型的训练配方,通过分阶段长上下文训练与教师蒸馏,把可用上下文扩展至 32×、KV cache 降低 >90%,在 RULER 上显著超越 Zebra-Llama 等现有升级基线。
Motivation
现有混合架构(Jamba、Samba、Qwen3-Next、Kimi-Linear)多从零预训练,成本高昂;而已有升级方法(MambaInLlama、Mohawk、Llamba、Zebra-Llama)只盯短上下文困惑度与常识基准,几乎不考虑长上下文能力保留。论文数据直接暴露问题:Zebra-Llama-1B 在 RULER-8K 仅得 12.3,32K 跌到 3.7,64K 几乎为 0(Table 2);Llamba-1B 在 RULER 全段 ≤ 2.9。这对 vLLM/SGLang 长文档服务、长代码补全、多跳推理的运营者而言意味着混合模型"号称长但不能长",他们被迫继续 serve 原始 Transformer 并在 64K 之后 OOM。作者的切入点是:Zebra-Llama 做了正确初始化,但训练仅到 ~24K 且未用长上下文教师蒸馏,这正是可以撬动的杠杆。HyLo 把"长上下文保留"升级为一等训练目标,并主张用一个内存友好的蒸馏栈让 8B 教师可以跑到 64K。
Key Ideas
- 混合架构组合 MLA + 线性块(Mamba-2 或 GDN),MLA 占比决定 KV/质量权衡;跨 Llama-3.2-1B/3B 与 Qwen3-1.7B 两个家族验证。
- 分阶段升级配方:Stage I 用 Enhanced-ILD(隐状态 + token-mixer 输出 L2 对齐)在 2K 做纯 MLA/Mamba2/GDN 蒸馏,Stage II 拼装混合体后在 8K→64K 做 KL 蒸馏。
- 教师引导的长上下文蒸馏:配合 Fused KL、Fused Hidden-State KL、activation checkpointing 使 8B 教师 + 64K 训练在 8×MI300X 上可跑。
- vLLM 运行时集成:支持 Mamba/GDN 固定隐状态 + MLA 可变 KV 的异构调度,可做到 2M token 推理。
- 给出全新 GDN-from-Transformer 初始化规则(GQA 展开 + 维度截断)。
Method
基底为 Llama-3.2-1B/3B 与 Qwen3-1.7B,按层索引混入 MLA(DeepSeek-V3 风格,带低秩 KV latent + 解耦 RoPE)与 Mamba-2 或 GDN 线性块。MLA 从教师注意力用截断 SVD 初始化(X-EcoMLA 方案),GDN 通过 GQA RepeatKV 扩展 + 维度截断复制 Q/K/V/O,门控/衰减/短卷积保持随机初始化。Stage I Enhanced-ILD 训练目标为 $\mathcal{L}{\text{ILD}}=\sum\ell |h^{(s)}\ell-h^{(t)}\ell|2 + |a^{(s)}\ell-a^{(t)}_\ell|_2$,在 2K 上训练,仅用 20% SFT 数据。Stage II 装配后以 KL 蒸馏端到端微调,序列长度阶段性扩展至 8K/64K。为让 64K+8B 教师可行,采用 Fused Hidden-State KL(跳过教师 LM head、Triton 核内融合 softmax+KL)与 chunk=4096 的 chunked KL;vLLM 集成处理异构 layer、MLA 压缩 KV 的 cache allocator,以及不被 FlashAttention 支持的头维度的回退。
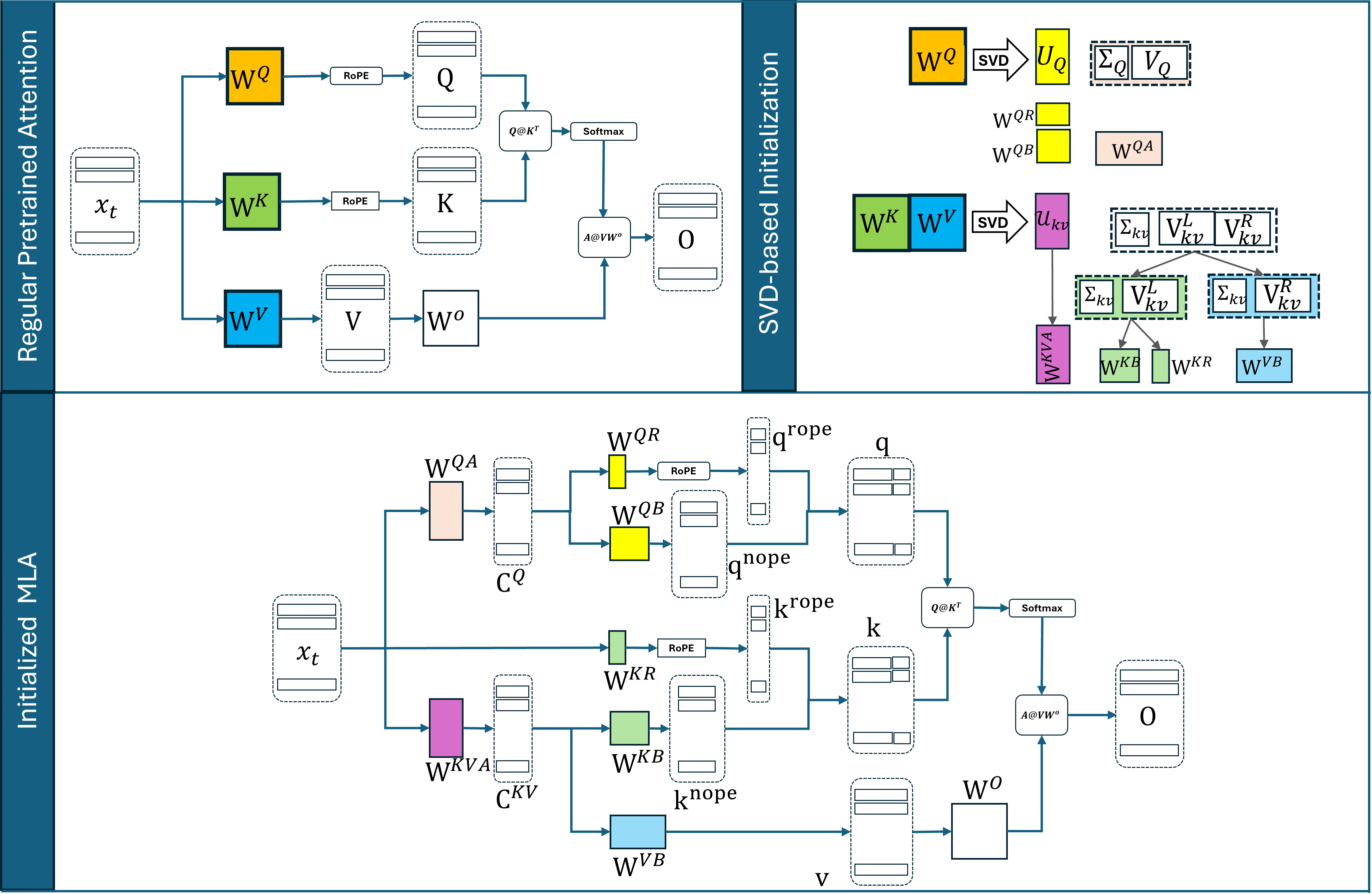
上图对应 Method 中"MLA from Transformer via SVD + 解耦 RoPE"这一步,展示了如何把教师注意力的 $W^Q,W^K,W^V,W^O$ 通过截断 SVD 分解为 MLA 的 $W^{QA},W^{QB},W^{KVA},W^{KVB}$ 等低秩投影,并从头平均的 K 投影抽出共享 RoPE 键。论文未给出此图附带的量化指标,仅作为 §A.2 初始化过程的可视化。
Experiments
基底:Llama-3.2-1B / Llama-3.2-3B / Qwen3-1.7B;教师多为 Llama-3.1-8B(Qwen 亦用 8B)。评测:lm-eval-harness 上 ARC/ARE/HS/OB/PI/RA/WG 七项常识 + GSM8K + RULER-13 任务(8K/16K/32K/64K)。基线:MambaInLlama、Llamba、Zebra-Llama(4MLA-12M2 / 8MLA-8M2 / 6MLA-22M2 / 14MLA-14M2)、M1、HypeNet、以及从零训 200B/400B token 的 Jet-Nemotron-2B。硬件:8×AMD MI300X,FSDP full shard,bf16,YaRN 用于上下文外推。
Results
RULER 长上下文收益是最大 headline:HyLo-Llama-4MLA12M2(训 64K)在 RULER 上从 Zebra-Llama 同配置的 12.3/6.8/3.7/0.1(8/16/32/64K)提升到 53.3/46.7/40.4/37.9(Table 2),64K 处近乎 0→38 的提升;8MLA8GDN 在 64K 达 41.6,GSM8K 同时拿到 39.4(Table 2)。3B 规模上,HyLo-Llama-14MLA14GDN(64K)在 RULER 64K 达 52.0 vs Zebra-Llama-14MLA14M2 的 4.2(Table 3),GSM8K 58.9。对比从零训 400B tokens 的 Jet-Nemotron-2B:HyLo-Qwen-14MLA14M2 仅 10B tokens 就在 GSM8K 达 73.5(vs Jet-Nemotron 19.4)、常识均分 55.7(vs 52.7)、RULER-64K 33.1(vs 14.1)(Table 4)。
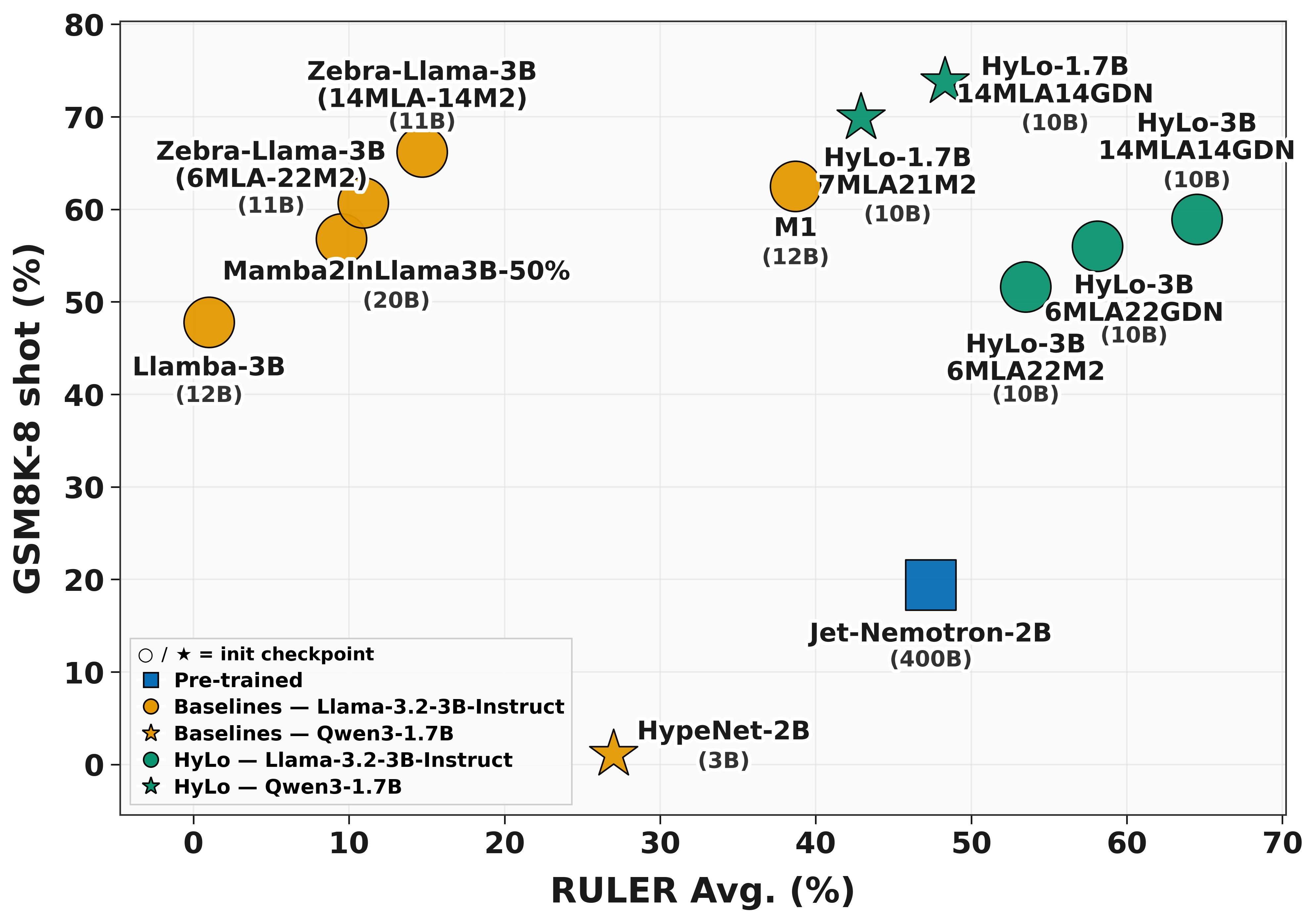
该图对应上述"长上下文明显领先且短上下文不掉"的主张:横轴是 RULER 在 8K/16K/32K/64K 的平均准确率,纵轴是 GSM8K。HyLo 变体位于右上(高 GSM8K、高长上下文均分),而 Llamba/MambaInLlama 落在右下(长上下文接近 0),Zebra-Llama 虽短上下文接近但 RULER 均分低。Table 2–4 支撑了这个定位。
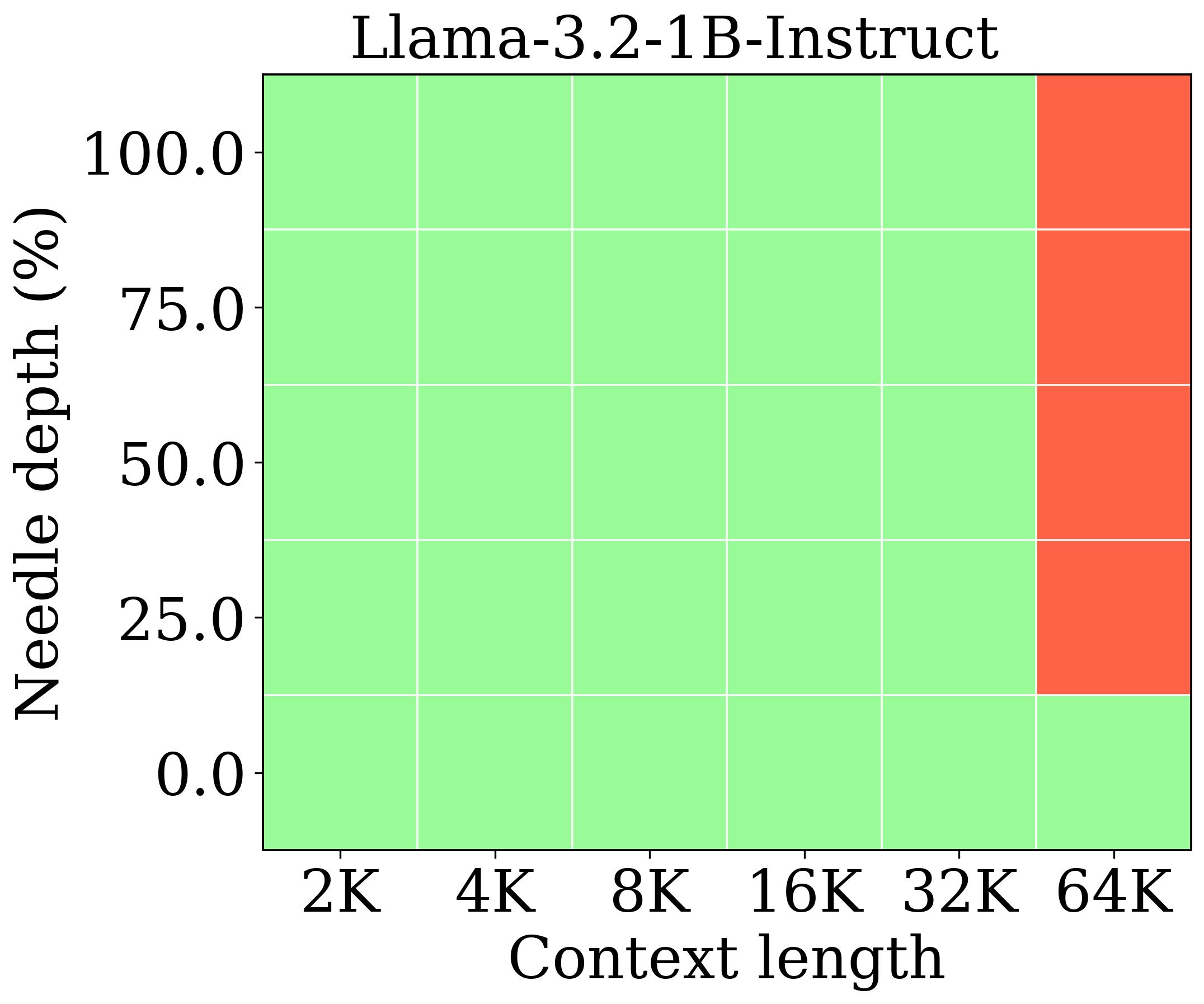
图 2 支持"KV 降到 3.9% 也能守住 Needle-in-a-Haystack"这一说法:4MLA12M2 在 NIH 上表现与 Llama-3.2-1B 可比、全面超过 Zebra-Llama;同时验证"64K 微调优于 8K 微调"——这与 Table 2 中 RULER-64K 从 0.5(训 8K)升到 37.9(训 64K)在趋势上一致。图本身未给单一数值刻度,但其颜色矩阵显示 HyLo-64K 在深上下文位置几乎保持全绿。
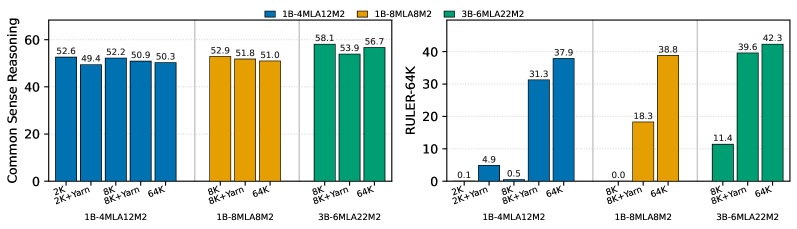
图 3 量化了"YaRN 外推 vs 直接长训"的权衡:1B-4MLA-12M2 以 8K 训练在短上下文常识 50.7%、RULER-64K 仅 0.5%;加 YaRN 后短上下文略降到 49.0%、RULER-64K 升至 31.3%;而直接以 64K 训练既拿到最好的长上下文,又保留短上下文表现。论文以此证明"直接长训"优于"短训+外推"。
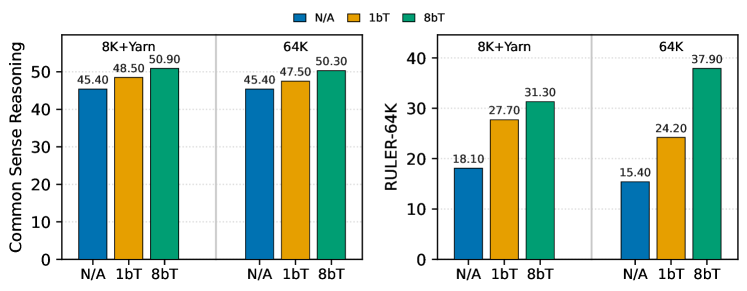
图 4 支撑 §4.3 关于 KD 规模的消融:对 1B-4MLA-12M2 在 64K 训练,用 8B 教师相对无教师让短上下文推理 +6%、RULER-64K +22%;在 8K+YaRN 设置下 KD 仍给 RULER-64K +14%。这说明 KD 对长上下文的收益远大于短上下文,且教师越大越好。
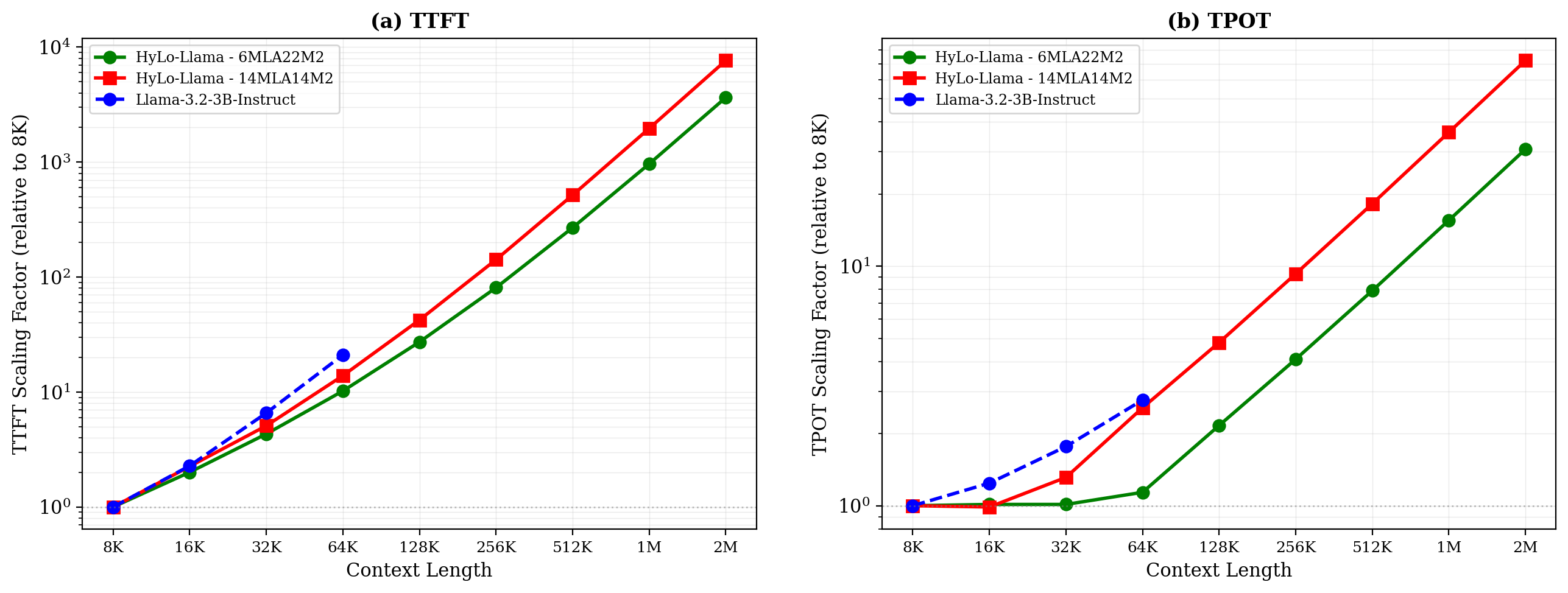
图 5 绑定 §4.4 关于推理延迟的主张:在 vLLM TP=8 MI300X 上,Llama-3.2-3B 在 128K 即 OOM;HyLo-Llama-6MLA22M2 与 14MLA14M2 能一路跑到 2M,且 6MLA 在 2M 处的 TTFT/TPOT 约为 14MLA 的 2× / 2.2×,直接对应 MLA 层数从 14 减到 6 的 O(n²) 注意力成本下降;Mamba 层的固定状态让 TPOT 在 8K–64K 段近似水平。
Conclusion
实用者的核心收获:把 Zebra-Llama 风格的升级 pipeline 扩展到 Stage-II 直接在 64K 做 KD,是目前以 10B 量级 tokens 就能把 1B/3B 级 Transformer 变成"可服务到 2M、KV <10%、RULER-64K 达 30–50"的混合模型的最直接配方;其中最具说服力的单一数字是 HyLo-Qwen-1.7B 用 10B tokens 在 GSM8K 上 73.5 vs Jet-Nemotron-2B 400B tokens 的 19.4(Table 4)。局限:评测仅覆盖 1–3B 规模、英文解码器、Llama/Qwen 两个家族;长上下文评测以 RULER 为主,未含更难的真实长文档 QA;消融显示 NoPE / gated attention 在升级场景反而无效,但没给在更大 teacher(>8B)下 KD 是否继续 scale 的证据;RULER-64K 绝对值仍显著低于短上下文,差距被坦承。
Novelty Check
作者自列最近的前作为 Zebra-Llama(MLA+Mamba2 升级 + ILD)、MambaInLlama(第一篇 attention→SSM 升级)、HypeNet(长上下文升级 baseline)、以及从零训的 Jet-Nemotron。HyLo 相对 Zebra-Llama 的真实 delta 有三件:(i) Stage-II 把训练上下文从 ~24K 推到 64K 并提供长上下文 KD 的内存栈;(ii) 加入 token-mixer 输出的 ILD 项(Enhanced-ILD),在 GSM8K 上稳定 +5–6(Table 6);(iii) 给出 GDN 的 Transformer 初始化规则,并把升级推广到 Qwen 家族。独立判断:相较 KL-guided 层选择(Li et al. 2025)与检索感知蒸馏(Bick et al. 2026)这些同期工作,HyLo 主要贡献在"系统工程 + 长上下文训练规模",并非全新方法论——属于 Zebra-Llama 的扎实长上下文延展,而非范式级创新。
Open Questions
- Teacher 规模继续放大(70B 级)是否继续线性改善 RULER?论文只扫到 8B。
- 为何 NoPE / gated attention 在升级场景失效?是否与 Stage-I 的短上下文 ILD 绑定使位置表征"焊死"有关?
- 为何部分 8MLA8M2 / 14MLA14M2 变体在 RULER-32K/64K 反而崩到 0.1(Table 2–3)?这暗示 MLA 占比与 Mamba 替换位置存在不稳定区间,缺少系统层选择消融。
- 在真正的长文档 QA / Repo 级代码(不仅 RULER 合成)上,KV 压缩 >90% 是否仍保留检索与多跳能力?
- Enhanced-ILD 的 token-mixer 对齐项在 GDN 这种有 recurrent state 的模块上,与 Mamba-2 是否应使用不同的对齐目标?论文统一用 L2,未做拆分消融。
Original abstract
Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse existing Transformer checkpoints. We study upcycling as a practical path to convert pretrained Transformer LLMs into hybrid architectures while preserving short-context quality and improving long-context capability. We call our solution \emph{HyLo} (HYbrid LOng-context): a long-context upcycling recipe that combines architectural adaptation with efficient Transformer blocks, Multi-Head Latent Attention (MLA), and linear blocks (Mamba2 or Gated DeltaNet), together with staged long-context training and teacher-guided distillation for stable optimization. HyLo extends usable context length by up to $32\times$ through efficient post-training and reduces KV-cache memory by more than $90%$, enabling up to 2M-token prefill and decoding in our \texttt{vLLM} inference stack, while comparable Llama baselines run out of memory beyond 64K context. Across 1B- and 3B-scale settings (Llama- and Qwen-based variants), HyLo delivers consistently strong short- and long-context performance and significantly outperforms state-of-the-art upcycled hybrid baselines on long-context evaluations such as RULER. Notably, at similar scale, HyLo-Qwen-1.7B trained on only 10B tokens significantly outperforms JetNemotron (trained on 400B tokens) on GSM8K, Lm-Harness common sense reasoning and RULER-64K.