arXiv: 2604.24273 · PDF
Authors: Md. Ashiq Ul Islam Sajid, Mohammad Sakib Mahmood, Md. Tareq Hasan, Md Abdur Rahim, Rafat Ara, Md. Arafat Hossain
Affiliations: N/A
Primary category: cs.LG · all: cs.LG
Matched keywords: large language model, llm, agent, rag, inference, quantization, latency
TL;DR
BitRL freezes a 2B-parameter BitNet b1.58 backbone (ternary weights {−1,0,+1}) and trains only small (~50K-param) PPO policy/value heads, yielding RL agents that retain 85–98% of FP16 performance with 10–16× memory reduction and 3–5× energy savings on a Raspberry Pi 4.
Motivation
On-device RL is blocked by the scale of modern LLM-backed agents: multi-billion-parameter models force cloud deployment, adding latency, privacy risk, and connectivity dependence. Edge practitioners today either drop the LLM entirely (losing semantic grounding for language-conditioned tasks) or stream states to a remote server. Prior quantization work on RL sits in the 4–8 bit range (QuaRL, QForce-RL) or addresses RLHF on datacenter GPUs (ParetoQ); none tackle 1-bit LLM backbones trained online on commodity edge hardware. The authors argue BitNet b1.58 finally makes extreme quantization viable at 2B scale, but RL on top of it is unexplored: ternary weights produce biased, noisy gradients, and bootstrapped value estimates amplify representation error through TD updates. Who is hurt: developers of smart-home, battery-powered robotics, and privacy-critical assistants that want LLM-style state understanding without a 4 GB, 8 W footprint. The paper frames its scope honestly as not safety-critical — BitRL shows 1.4× higher variance than FP16, so autonomous driving or medical decisions are excluded. The gap it closes is narrow but concrete: online PPO training with a 1-bit LLM encoder on <1 GB / <4 W hardware.
Key Ideas
- Freeze a 2B BitNet b1.58 backbone as a ternary-weight state encoder; train only ~50K-param policy and value heads (<1% of total params).
- Serialize MDP states to natural language so the LLM backbone can be reused across classic control, MuJoCo, and language-conditioned tasks.
- Modified PPO for extreme quantization: tight clip ε=0.1, entropy β=0.05, grad-clip 0.5, separate LRs (3e-4 policy, 1e-3 value).
- Theoretical analysis casts ternary quantization as bounded parameter perturbation, giving policy-gradient bias O(ε_Q²) and TD value error amplified by 1/(1−γ).
- Identifies value estimation as the dominant failure mode and proposes hybrid precision (INT8 critic + 1-bit policy) as the recommended practical config.
Method
BitRL treats each task as an MDP and optimizes the PPO clipped surrogate objective. States are text-serialized (15–40 tokens for MuJoCo’s 17–27-dim observations) and encoded by the frozen BitNet b1.58 backbone f_θ*, which uses ternary weights Q(W)=sign(W)·𝟙[|W|>τ] and runs on bitnet.cpp kernels that replace floating-point MACs with integer adds and lookups. Two 2-layer MLP heads (256→128, ~50K params each, FP32) produce a softmax policy and a scalar value. Training uses rollouts of 2048 steps, GAE (λ=0.95, γ=0.99), 4 epochs over batch-64 mini-batches. The backbone is never updated; all gradient flow is confined to the heads. Stability comes from the combination of tight ε, strong entropy regularization, and aggressive grad clipping — ablations show removing any single one is catastrophic.
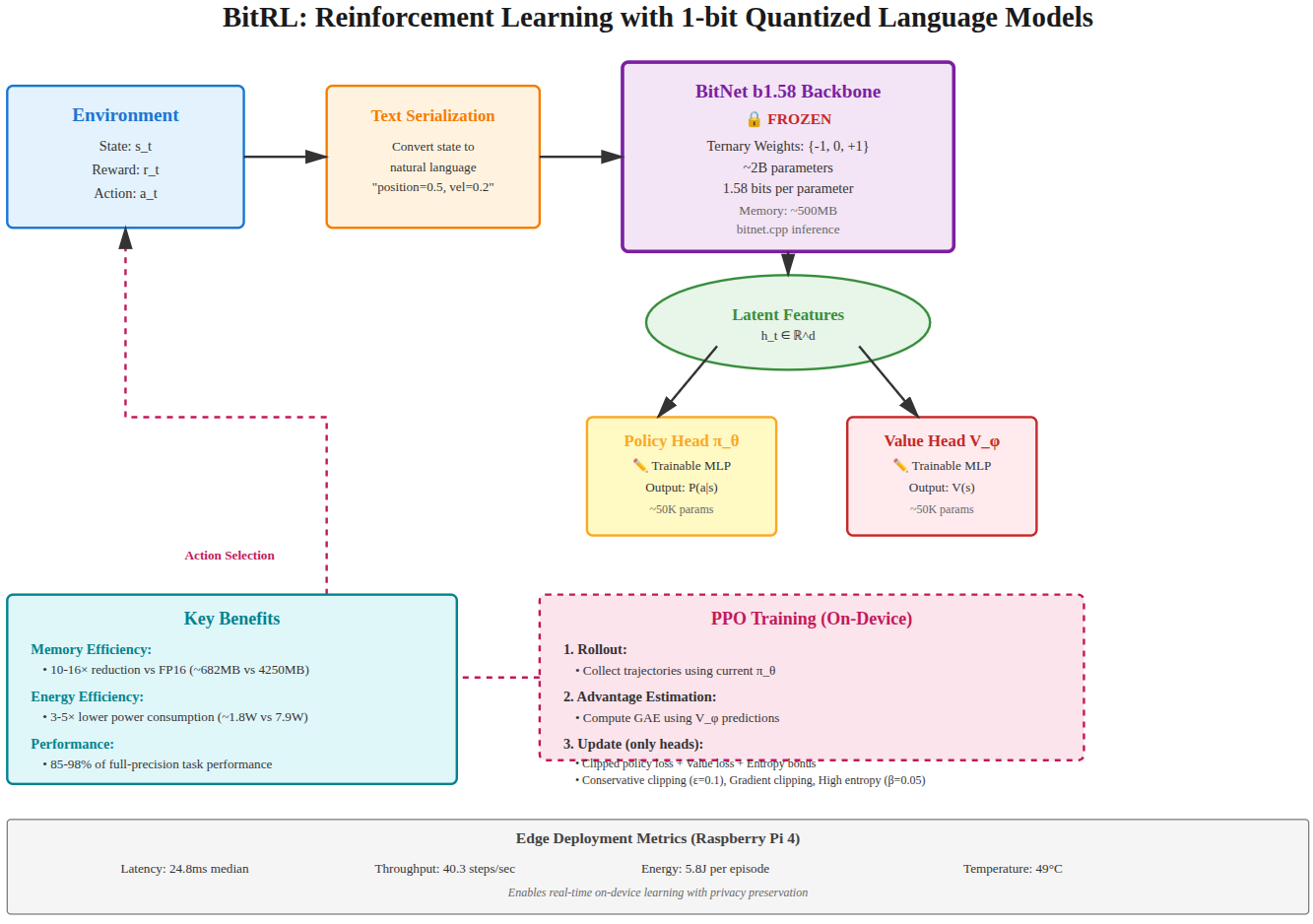
Figure 1 directly illustrates the three-block pipeline described above — text serialization of the MDP state, the frozen ternary BitNet backbone, and the two trainable heads — and is the architectural claim underpinning the <1% trainable-parameter count and the integer-only bitnet.cpp inference path. The paper does not quantify per-block latency in the figure itself; the 1.2 ms tokenization and 24.8 ms median inference figures come from Table III, not from this diagram.
Experiments
Nine benchmarks across three families: classic discrete control (CartPole-v1, Acrobot-v1, MountainCar-v0), MuJoCo continuous control (HalfCheetah-v4, Hopper-v4, Walker2d-v4), and language-conditioned tasks (TextWorld Cooking, BabyAI-GoToRedBall, SmartHome-Light). Baselines: FP16-PPO, INT8-PPO, INT4-PPO, and a non-LLM MLP-PPO. Five seeds each; GPU training on A100 for baselines; edge metrics measured on Raspberry Pi 4 Model B (4 GB, ARM Cortex-A72 @1.5 GHz) with a Monsoon Power Monitor at 5 kHz.
Results
- Task performance (Table II): geometric mean 91.7% of FP16. HalfCheetah 4210 vs. FP16 4850 (86.8%); Walker2d 3620 vs. 4120 (87.9%); TextWorld Cooking 0.75 vs. 0.78 (96.2%); BabyAI 0.88 vs. 0.92. BitRL beats MLP-PPO by 30–54% on language tasks (TextWorld 0.75 vs. 0.42). MountainCar is the one task where BitRL (-108) beats FP16 (-115), attributed to exploration noise in sparse reward.
- Edge metrics (Table III, Raspberry Pi 4): peak memory 682 MB vs. 4,250 MB FP16 (≈6.2× raw, authors cite 10–16× including activations); median latency 24.8 ms vs. 312 ms (12.6×); steps/sec 40.3 vs. 3.2; energy/episode 5.8 J vs. 24.8 J (4.3×); sustained temp 49 °C vs. 68 °C. Training 10M steps: ~67 h on-device vs. >800 h for FP16.
- Ablations (Table IV, HalfCheetah): removing grad clip → 1240 return, 80% failures; standard PPO (ε=0.2, β=0.01) → 60% failure. Hybrid INT8 critic + 1-bit policy reaches 4680 (beats BitRL 4210 by ~11%) at 1.2 GB. Value-only quantization 3980, confirming the value bottleneck.
- Training dynamics (Table V): 11% higher initial entropy, 82% higher final value loss, 87% higher grad-norm variance, and 3.5M vs. 2.4M steps to reach 90% — all matching Theorem IV.2’s 1/(1−γ) error amplification.
Conclusion
The practical takeaway: a frozen 1-bit BitNet b1.58 backbone with tiny trainable heads is enough to run online PPO on a Raspberry Pi 4 at 40 Hz with <1 GB RAM, giving up ~8% average return vs. FP16 (91.7% geomean) in exchange for a 12.6× latency reduction and 4.3× energy cut. The single clearest recommendation is the INT8-critic + 1-bit-policy hybrid, which recovers the value-function loss at 1.76× memory. Limits the paper itself flags: experiments are on a single 2B BitNet backbone, 10M-step budgets, one edge SKU (RPi 4), and only 9 benchmarks; continuous control lags meaningfully; variance is 1.4× FP16 so safety-critical use is excluded. No ablation over backbone scale (1B, 3B) or over different tokenizer/serializers.
Novelty Check
The authors position BitRL against QuaRL (4–8 bit MLP/CNN, post-hoc), ParetoQ [12] (4-bit LLM RLHF, datacenter), QForce-RL [14] (4–8 bit MLP on FPGA), Action-Q [5] (action-space quantization), and BitDelta [6] (1-bit LLM, no RL) — their Table I claims BitRL is the only 1-bit + LLM + online RL + edge-HW entry. That specific intersection does look new; bitnet.cpp [16] and BitNet b1.58 [19,20] are the obvious enabling works, used here off-the-shelf. The intellectual contribution is mostly system integration plus a careful PPO-stability recipe and the value-bottleneck framing — the theoretical bounds are standard Lipschitz-perturbation arguments. Uncertain whether any 2025 concurrent work on 1-bit-LLM RLHF exists that the authors missed; I cannot confidently name one.
Open Questions
- Does the value bottleneck persist with larger BitNet backbones (7B+), or is it specific to 2B-scale capacity?
- How does performance scale with serialization choice — structured JSON vs. natural language vs. learned tokens?
- Can the backbone be partially unfrozen (LoRA on ternary weights) without blowing the edge memory budget?
- Sample efficiency on sparse-reward hard-exploration tasks (Montezuma, not MountainCar) where the “quantization-as-exploration-noise” claim would matter most.
- Robustness of the 40 Hz control-loop claim under thermal throttling over multi-hour deployments, not just steady-state measurements.
Original abstract
The deployment of intelligent reinforcement learning (RL) agents on resource-constrained edge devices remains a fundamental challenge due to the substantial memory, computational, and energy requirements of modern deep learning systems. While large language models (LLMs) have emerged as powerful architectures for decision-making agents, their multi-billion parameter scale confines them to cloud-based deployment, raising concerns about latency, privacy, and connectivity dependence. We introduce BitRL, a framework for building RL agents using 1-bit quantized language models that enables practical on-device learning and inference under severe resource constraints. Leveraging the BitNet b1.58 architecture with ternary weights (-1, 0, +1) and an optimized inference stack, BitRL achieves 10-16x memory reduction and 3-5x energy efficiency improvements over full-precision baselines while maintaining 85-98 percent of task performance across benchmarks. We provide theoretical analysis of quantization as structured parameter perturbation, derive convergence bounds for quantized policy gradients under frozen-backbone architectures, and identify the exploration-stability trade-off in extreme quantization. Our framework systematically integrates 1-bit quantized language models with reinforcement learning for edge deployment and demonstrates effectiveness on commodity hardware.