arXiv: 2604.22750 · PDF
作者: Longju Bai, Zhemin Huang, Xingyao Wang, Jiao Sun, Rada Mihalcea, Erik Brynjolfsson, Alex Pentland, Jiaxin Pei
主分类: cs.CL · 全部: cs.CL, cs.CY, cs.HC, cs.SE
命中关键词: llm, agent, agentic, rag, reasoning
TL;DR
首个系统研究 agentic coding 任务 token 消耗的工作:分析 8 个前沿 LLM 在 SWE-bench Verified 上的轨迹,发现 agent 任务比普通代码任务贵 1000 倍、同任务 run 间差异高达 30 倍、且模型无法准确预测自身 token 成本。
核心观点
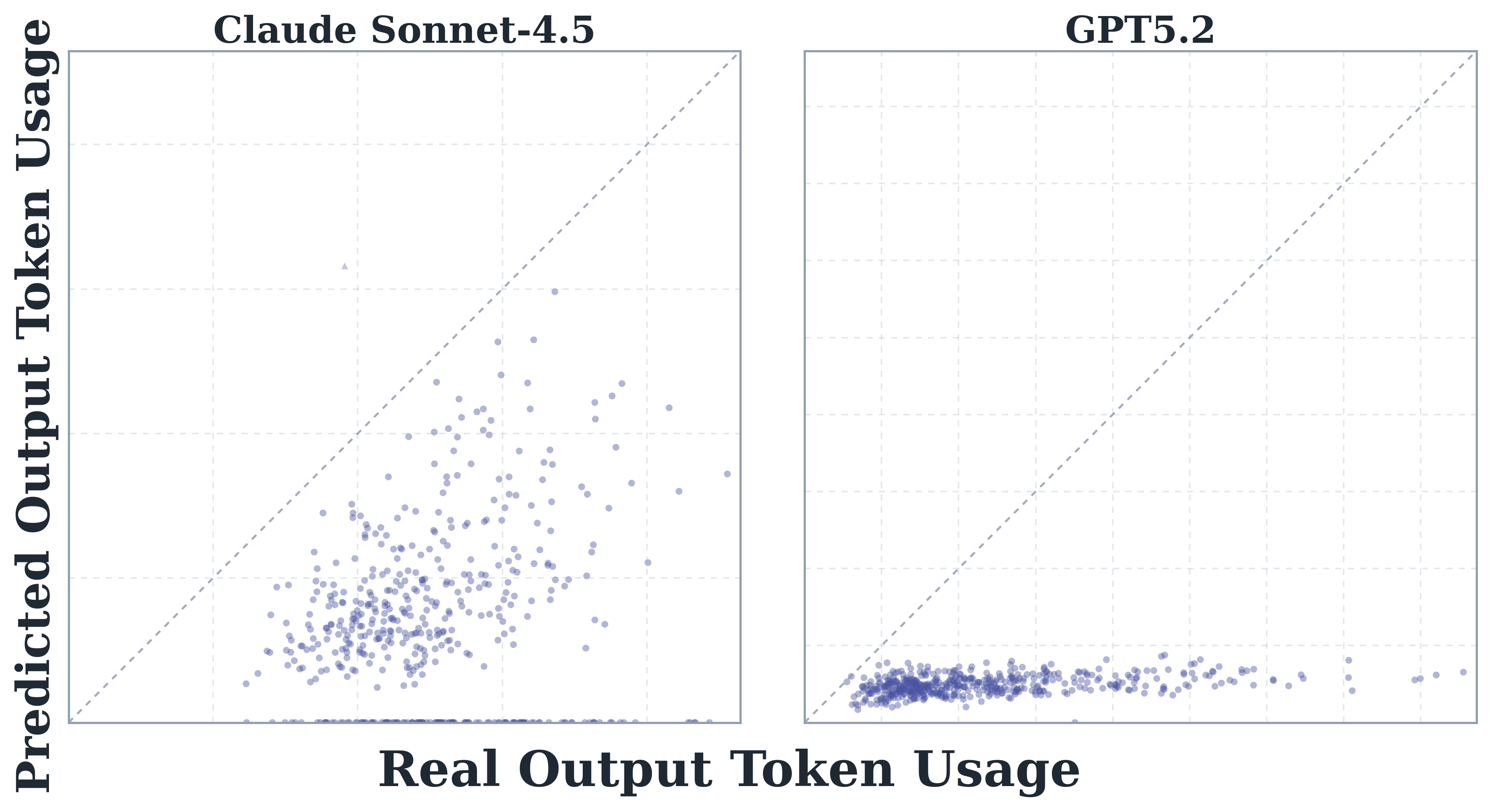
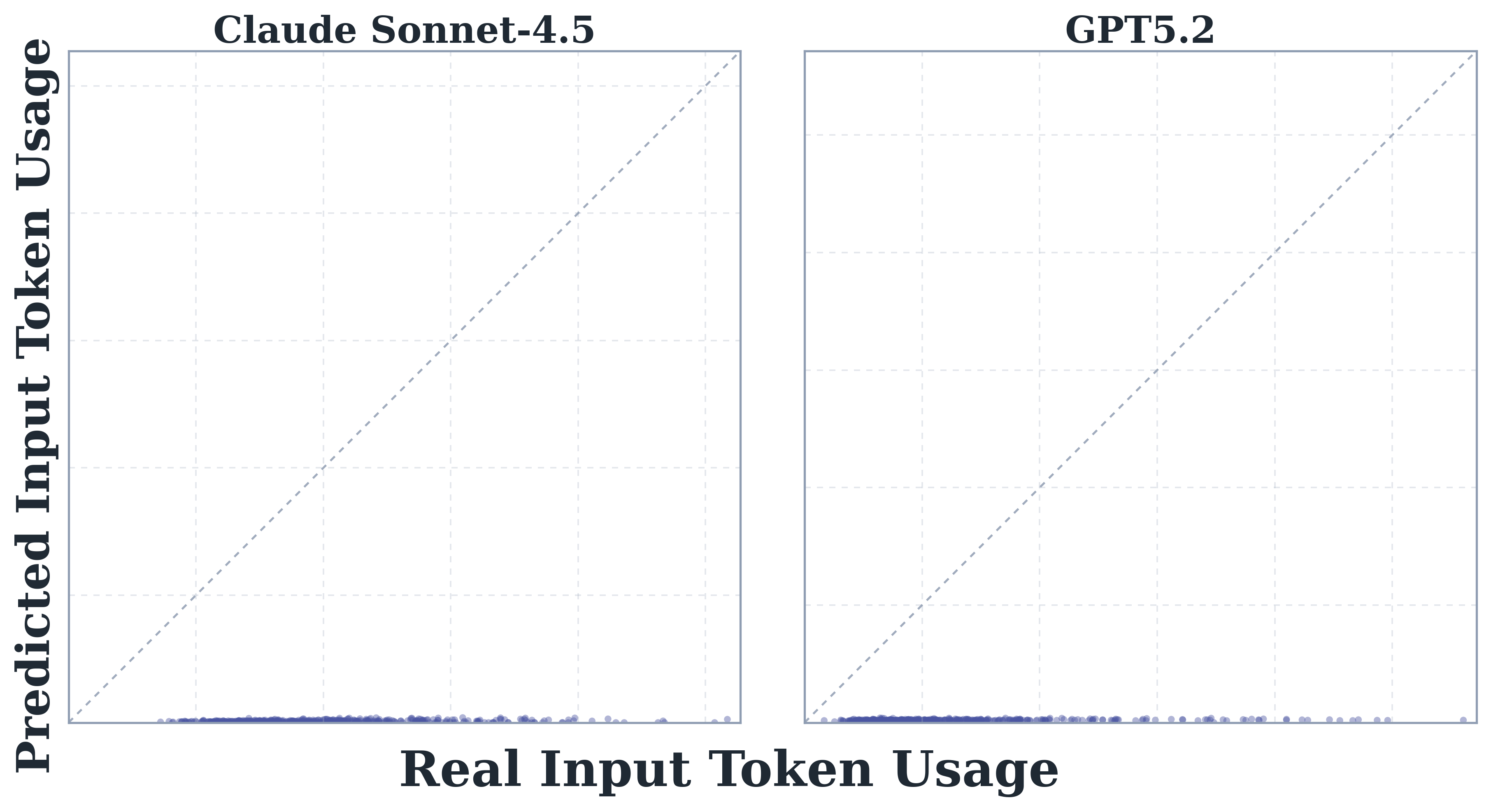
- Agent 任务 token 消耗极高,比 code reasoning/chat 高约 1000 倍,且 input token 而非 output 是主要成本驱动。
- Token 用量天然随机:同任务同模型不同 run 差异可达 30 倍;高消耗≠高准确率,accuracy 常在中等成本达到峰值后饱和。
- 模型间 token 效率差异显著:Kimi-K2、Claude-Sonnet-4.5 平均比 GPT-5 多消耗 150 万+ token。
- 人类专家标注的任务难度与实际 token 成本仅弱相关,揭示了「人感知复杂度」与「agent 计算代价」的根本错位。
- 前沿模型无法准确预测自己的 token 开销(相关性最高仅 0.39),且系统性低估真实成本。
方法
基于 SWE-bench Verified 收集 8 个 frontier LLM 的 agentic 执行轨迹,逐条统计 input/output token 分布、跨 run 方差、与准确率的关系。同时设计 self-prediction 协议:在任务执行前让模型预估自身 token 消耗,再与实际用量比对,计算相关系数与系统性偏差。并将 token 成本与人类难度评级做对齐分析。
实验
- 数据集:SWE-bench Verified。
- 模型:8 个前沿 LLM,包括 GPT-5、Claude-Sonnet-4.5、Kimi-K2 等。
- 基线对比:与 code reasoning、code chat 两类非 agentic 任务对比。
- 指标:总 token、input/output 占比、跨 run 变异系数、accuracy-vs-cost 曲线、难度相关性、自预测相关系数(最高 0.39)。
结果
- Agentic 任务消耗 ≈ 1000× code chat/reasoning。
- 同任务跨 run token 最多差 30×。
- 准确率在中等 token 成本时达峰,继续堆 token 收益递减甚至下降。
- GPT-5 在 token 效率上明显领先 Kimi-K2 / Claude-Sonnet-4.5(平均少 1.5M+ token)。
- 模型自预测与实际 token 的相关性弱至中等(≤0.39),且普遍低估。
为什么重要
- 对 agent infra / 产品方:token 成本是随机变量,基于均值的定价和预算会严重低估长尾;需要引入 budget cap、early-stop、自适应路由。
- 对模型选型:效率差异巨大,选贵模型不等于更准;GPT-5 等在 cost-accuracy 上可能 Pareto 更优。
- 对 agent 自我规划:LLM 尚不具备可靠的 self-cost estimation,元认知能力是下一个 bottleneck。
与已有工作的关系
延续 SWE-bench / SWE-agent 系列对 coding agent 的评测,但首次聚焦 token economics;与 inference scaling law、test-time compute、LLM metacognition/self-evaluation 研究相关;补足了 HumanEval、MBPP 等静态 benchmark 忽略的 agent runtime 代价维度。
尚未回答的问题
- 如何让 agent 具备可靠的 token 自预测与预算自控?
- Token 随机性的根源是 planning policy、tool 反馈循环还是 context 膨胀?
- 中等成本峰值背后的机制,能否用于设计 early-exit / adaptive budgeting?
- 结论能否推广到非 coding 领域(web agent、科研 agent)?
- 是否存在 Pareto 最优的 agent scaffolding,使同模型 token 效率大幅提升?
原始摘要
The wide adoption of AI agents in complex human workflows is driving rapid growth in LLM token consumption. When agents are deployed on tasks that require a significant amount of tokens, three questions naturally arise: (1) Where do AI agents spend the tokens? (2) Which models are more token-efficient? and (3) Can agents predict their token usage before task execution? In this paper, we present the first systematic study of token consumption patterns in agentic coding tasks. We analyze trajectories from eight frontier LLMs on SWE-bench Verified and evaluate models’ ability to predict their own token costs before task execution. We find that: (1) agentic tasks are uniquely expensive, consuming 1000x more tokens than code reasoning and code chat, with input tokens rather than output tokens driving the overall cost; (2) token usage is highly variable and inherently stochastic: runs on the same task can differ by up to 30x in total tokens, and higher token usage does not translate into higher accuracy; instead, accuracy often peaks at intermediate cost and saturates at higher costs; (3) models vary substantially in token efficiency: on the same tasks, Kimi-K2 and Claude-Sonnet-4.5, on average, consume over 1.5 million more tokens than GPT-5; (4) task difficulty rated by human experts only weakly aligns with actual token costs, revealing a fundamental gap between human-perceived complexity and the computational effort agents actually expend; and (5) frontier models fail to accurately predict their own token usage (with weak-to-moderate correlations, up to 0.39) and systematically underestimate real token costs. Our study offers new insights into the economics of AI agents and can inspire future research in this direction.