arXiv: 2604.22750 · PDF
作者: Longju Bai, Zhemin Huang, Xingyao Wang, Jiao Sun, Rada Mihalcea, Erik Brynjolfsson, Alex Pentland, Jiaxin Pei
单位: University of Michigan, Stanford University, All Hands AI, Google DeepMind, Microsoft AI, MIT
主分类: cs.CL · 全部: cs.CL, cs.CY, cs.HC, cs.SE
命中关键词: llm, agent, agentic, rag, reasoning
TL;DR
首个系统研究 agentic coding 任务 token 消耗的工作:在 SWE-bench Verified 上分析 8 个前沿 LLM,发现 agent 任务耗 token 是普通代码任务的 1000 倍,且模型无法准确预测自身消耗。
核心观点
- Agentic 任务 token 消耗远超 code reasoning / code chat,高出约 1000 倍,且 input token 而非 output token 才是主要成本驱动。
- Token 使用高度随机:同一任务不同运行最多相差 30 倍;更多 token ≠ 更高准确率,准确率常在中等成本处达峰后饱和。
- 模型间 token 效率差异显著:Kimi-K2 与 Claude-Sonnet-4.5 平均比 GPT-5 多耗 150 万+ token。
- 人类专家标注的任务难度与实际 token 成本只有弱相关,揭示人类感知复杂度与 agent 实际算力消耗的鸿沟。
- 前沿模型无法准确预测自身 token 用量(相关性 ≤ 0.39),且系统性低估真实成本。
方法
作者收集 8 个前沿 LLM 在 SWE-bench Verified 上的完整 agent trajectories,分解 input/output token 构成,按任务、模型、重复运行维度分析消耗分布。同时让模型在任务执行前自我预测 token 用量,与真实消耗做校准对比,从而评估 self-prediction 能力。
实验
- 数据集:SWE-bench Verified。
- 模型:8 个前沿 LLM(含 GPT-5 / GPT-5.2、Claude-Sonnet-4.5、Kimi-K2 等)。
- 对照任务类型:code reasoning、code chat vs. agentic coding。
- 指标:总 token、input/output 拆分、跨运行方差、准确率-成本曲线、人类难度评级与 token 的相关性、self-prediction 校准(相关系数、低估程度)。
结果
关键量化结论:agent 任务 ~1000× token;同任务方差 30×;Kimi-K2 / Sonnet-4.5 比 GPT-5 多耗 1.5M+ token;self-prediction 相关性最高仅 0.39,且系统性低估。
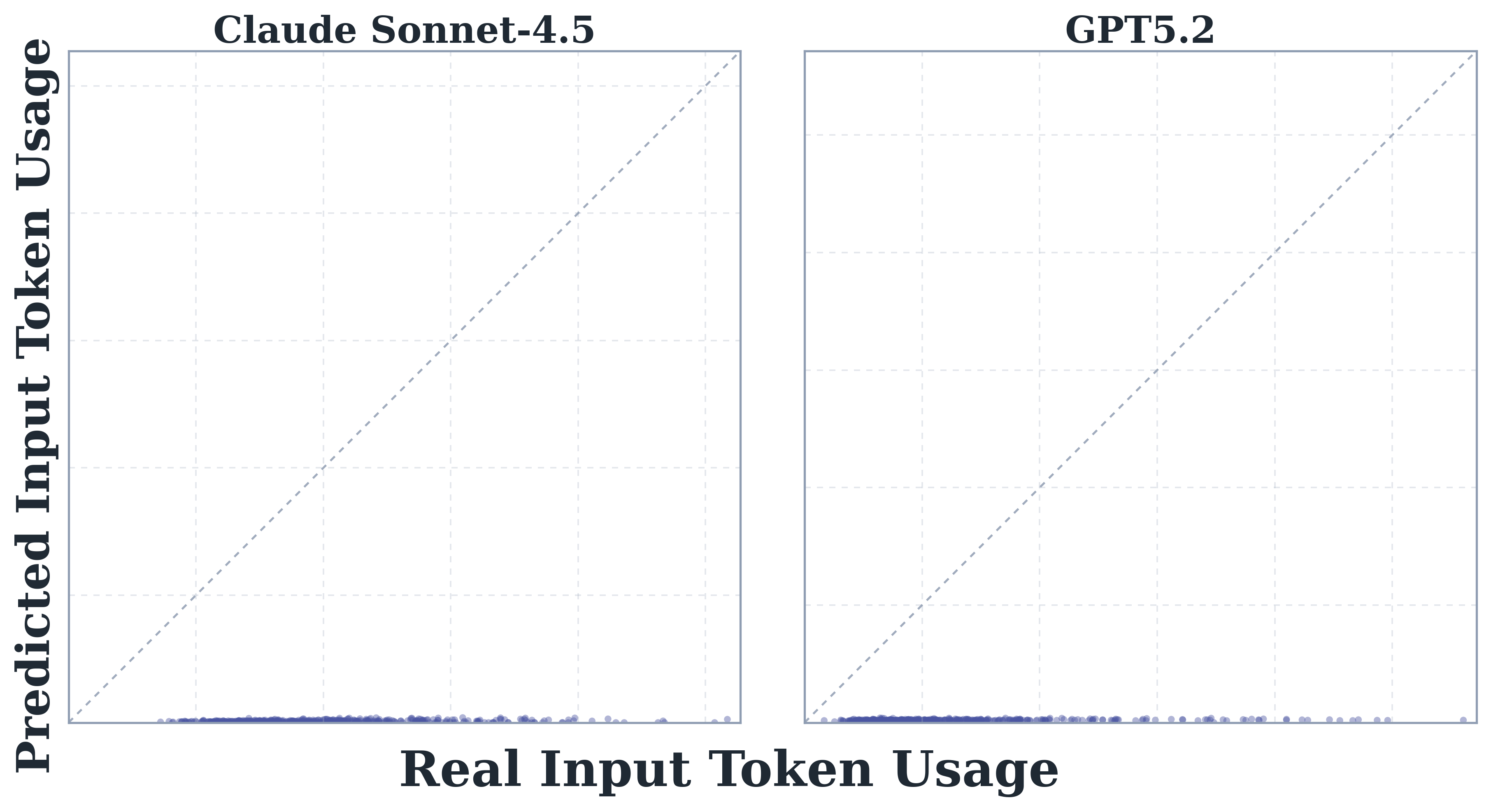
即使去掉 in-context demonstration,Sonnet 4.5 与 GPT-5.2 对自身 token 消耗仍明显低估,input token 部分尤为严重,校准曲线整体偏离对角线。
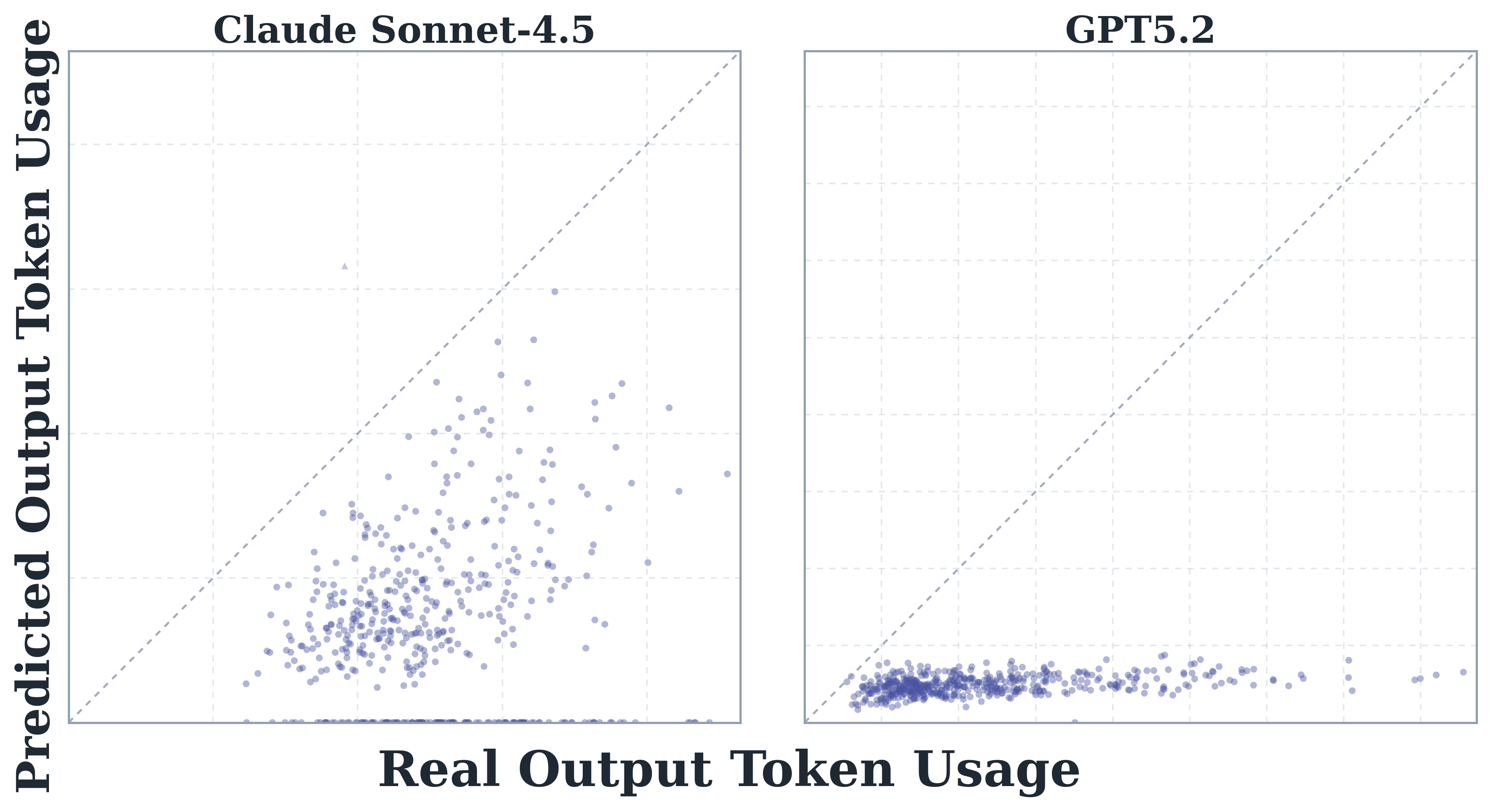
上图显示无示例条件下,Sonnet 4.5 的自预测点云全面落在对角线下方;GPT-5.2 也呈类似趋势,进一步佐证低估并非提示设计可补救的问题。
为什么重要
对 agent / LLM 基础设施从业者而言,本文首次量化了 agentic workloads 的经济学:预算规划不能沿用 chat 任务经验,需要为 input token、高方差和不可预测性留足空间;模型选型应把 token 效率作为与准确率并列的一级指标;同时警示"让 agent 自报预算"不可靠,调度与计费系统需引入外部估算。
与已有工作的关系
延伸 SWE-bench / SWE-bench Verified 上的 agent 评测传统,但关注点从 accuracy 转向 cost;补充了 LLM calibration / self-knowledge 研究在 agent 场景的证据;与 scaling law、inference-time compute 的讨论形成对照——更多算力并不单调换来更高准确率。
尚未回答的问题
- 如何构建可靠的外部 token 预算预测器?
- 高方差的根因是 planning 策略、工具调用循环还是随机采样?
- 能否通过训练或架构改动降低 input token 主导的成本?
- 结论在非 coding agent(浏览、科研、多模态)上是否成立?
原始摘要(中文翻译)
AI agent 在复杂人类工作流中的广泛采用,正推动 LLM token 消耗快速增长。当 agent 被部署到需要大量 token 的任务上时,自然出现三个问题:(1) AI agent 把 token 花在哪里?(2) 哪些模型更 token 高效?(3) agent 能否在任务执行前预测其 token 用量?本文首次系统研究 agentic coding 任务中的 token 消耗模式。我们在 SWE-bench Verified 上分析来自八个前沿 LLM 的 trajectories,并评估模型在任务执行前预测自身 token 成本的能力。我们发现:(1) agentic 任务代价独特地高昂,其 token 消耗比 code reasoning 与 code chat 高 1000 倍,且驱动整体成本的是 input token 而非 output token;(2) token 使用高度可变且本质上随机:对同一任务的运行在总 token 上最多可相差 30 倍,更高的 token 使用并不转化为更高的准确率;相反,准确率常在中等成本处达到峰值并在更高成本下饱和;(3) 模型间 token 效率差异显著:在相同任务上,Kimi-K2 与 Claude-Sonnet-4.5 平均比 GPT-5 多消耗超过 150 万 token;(4) 由人类专家评定的任务难度与实际 token 成本仅弱相关,揭示出人类感知复杂度与 agent 实际消耗的计算量之间存在根本性差距;(5) 前沿模型无法准确预测自身 token 用量(相关性弱到中等,最高 0.39),并系统性地低估真实 token 成本。本研究为 AI agent 的经济学提供了新的洞见,并可启发该方向的未来研究。