arXiv: 2604.22750 · PDF
Authors: Longju Bai, Zhemin Huang, Xingyao Wang, Jiao Sun, Rada Mihalcea, Erik Brynjolfsson, Alex Pentland, Jiaxin Pei
Affiliations: University of Michigan, Stanford University, All Hands AI, Google DeepMind, Microsoft AI, MIT
Primary category: cs.CL · all: cs.CL, cs.CY, cs.HC, cs.SE
Matched keywords: llm, agent, agentic, rag, reasoning
TL;DR
First systematic study of token consumption in agentic coding tasks on SWE-bench Verified across eight frontier LLMs. Finds agentic runs consume ~1000× more tokens than code chat, usage is highly stochastic (up to 30× variance), models differ sharply in efficiency, and LLMs systematically underestimate their own token costs.
Key Ideas
- Agentic coding is uniquely expensive: ~1000× more tokens than code reasoning/chat, dominated by input tokens.
- Token usage is stochastic — same task varies up to 30× across runs; more tokens ≠ higher accuracy (accuracy peaks at intermediate cost).
- Models vary widely: Kimi-K2 and Claude-Sonnet-4.5 average >1.5M more tokens than GPT-5 on the same tasks.
- Human-rated task difficulty only weakly correlates with actual token expenditure.
- Frontier LLMs predict their own token usage poorly (correlation ≤0.39) and systematically underestimate costs.
Approach
The authors collect and analyze agent trajectories from eight frontier LLMs running SWE-bench Verified, decomposing token consumption into input vs. output components across task phases. They then probe each model’s self-prediction ability by prompting it to estimate its own token cost before execution and comparing against ground-truth usage, measuring calibration and correlation.
Experiments
- Benchmark: SWE-bench Verified (agentic coding).
- Models: eight frontier LLMs including GPT-5, Claude-Sonnet-4.5, Kimi-K2, GPT-5.2.
- Comparisons: agentic vs. code-reasoning vs. code-chat token footprints; per-task variance across repeated runs; human-expert difficulty ratings vs. measured tokens.
- Self-prediction evaluated with and without in-context demonstrations, reported via calibration plots and correlation.
Results
Agentic tasks cost ~1000× more tokens than non-agentic baselines, with input tokens dominating. Run-to-run variance reaches 30×; accuracy saturates or declines past intermediate spend. Kimi-K2 and Sonnet-4.5 burn >1.5M more tokens than GPT-5 per task on average. Self-prediction correlations top out at 0.39 and skew low.
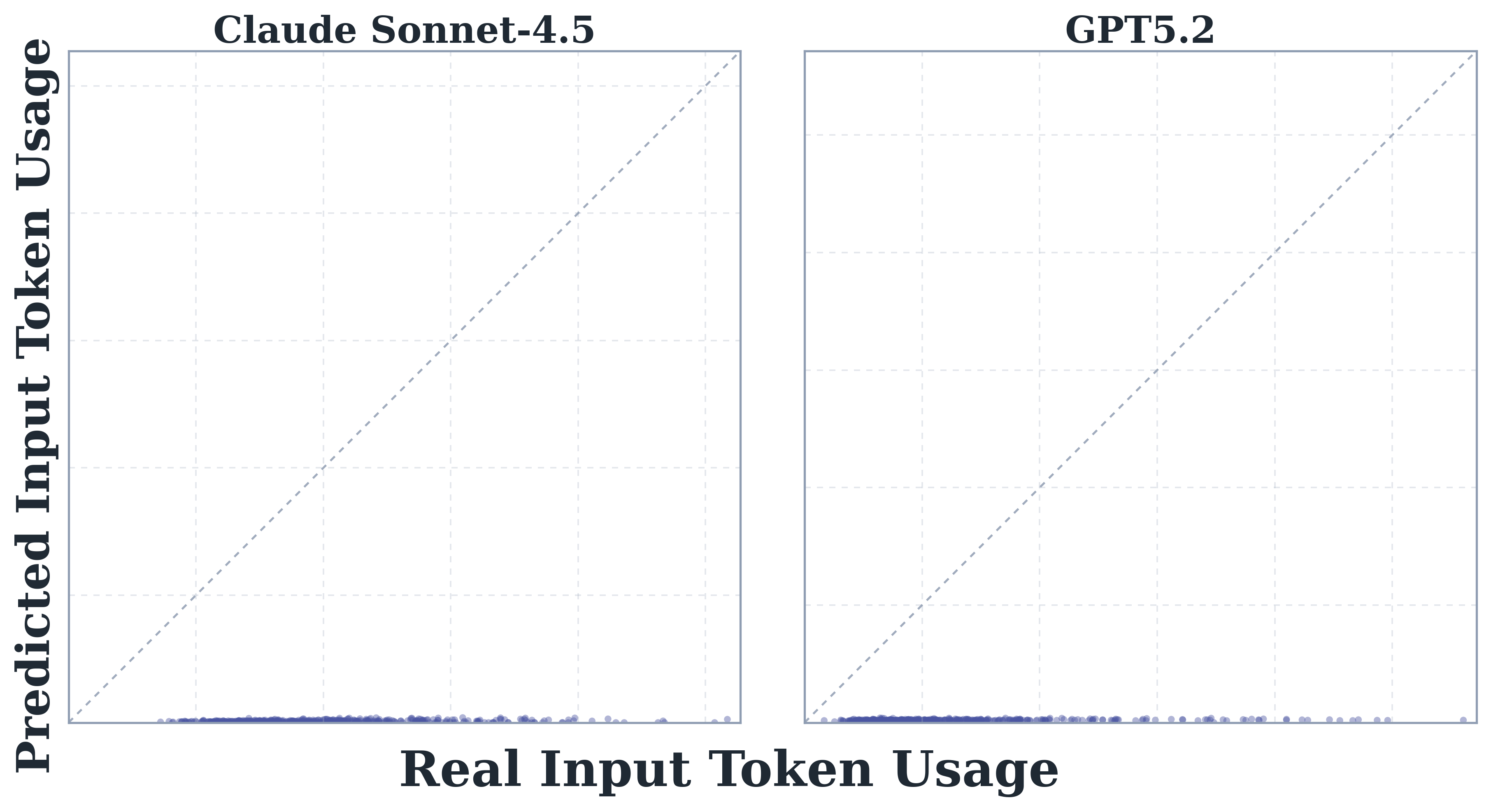
Without in-context demonstrations, underestimation persists and worsens, especially on input tokens, for both Sonnet 4.5 and GPT-5.2.
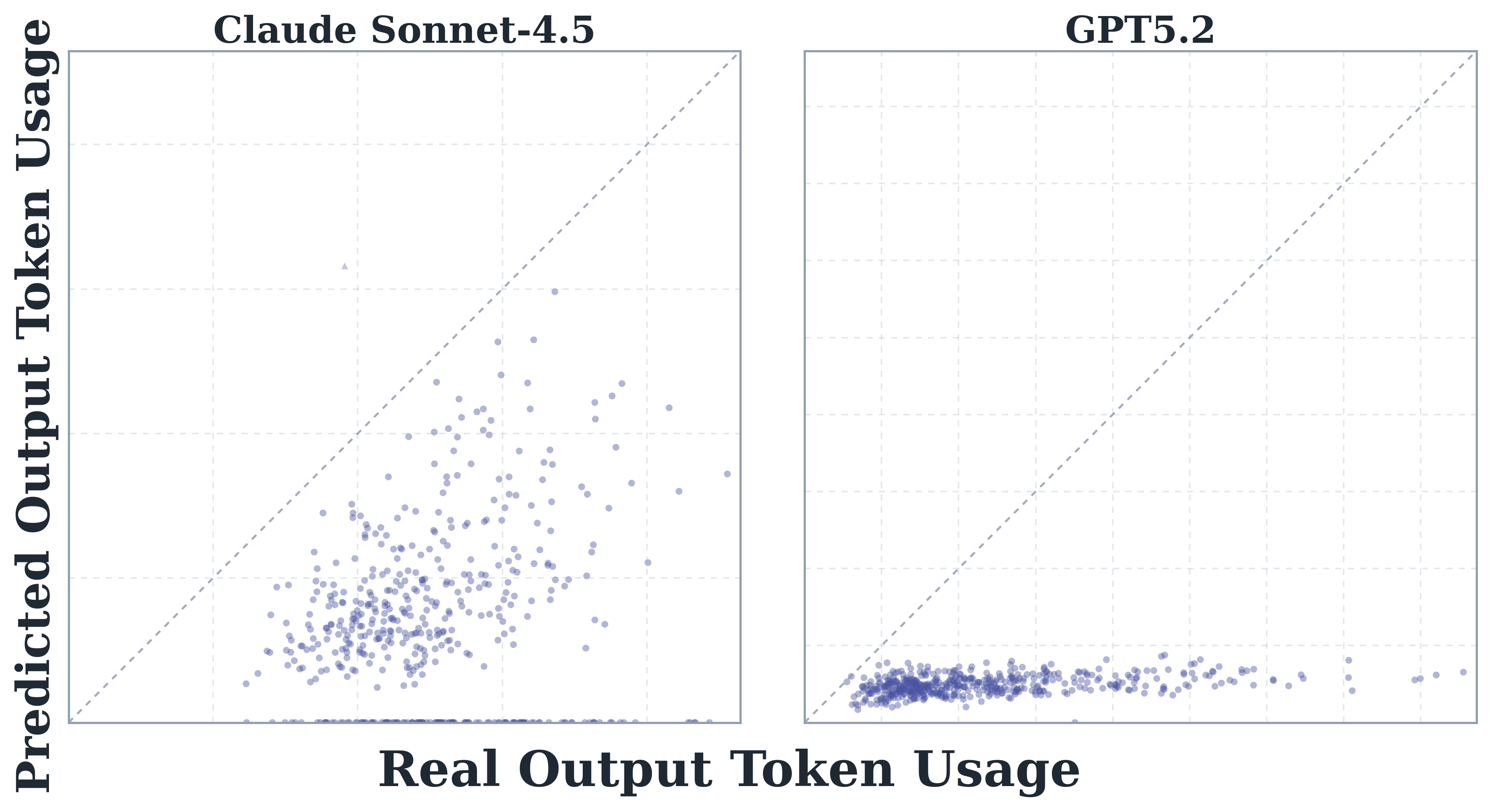
The calibration plot above tracks Sonnet 4.5’s predicted vs. actual tokens against the diagonal; points sit well below the line, confirming pronounced underestimation.
The companion plot for GPT-5.2 tells the same story — predictions cluster beneath perfect calibration, with the input-token gap widening when no demonstration is provided.
Why It Matters
Gives agent-infra practitioners empirical grounding for budgeting, autoscaling, and model selection: input-token cost dominates, cost≠quality, and self-reported estimates cannot be trusted for quota planning. Motivates external cost predictors and adaptive stopping.
Connections to Prior Work
Extends SWE-bench and agentic-coding evaluations (Devin, OpenHands, SWE-agent), LLM cost/efficiency studies, and calibration/self-knowledge work on frontier models.
Open Questions
What drives the 30× variance — tool loops, retrieval, or context bloat? Can lightweight predictors outperform self-estimation? How do these patterns extend beyond coding to general agent workflows, and can training explicitly improve cost calibration?
Original abstract
The wide adoption of AI agents in complex human workflows is driving rapid growth in LLM token consumption. When agents are deployed on tasks that require a significant amount of tokens, three questions naturally arise: (1) Where do AI agents spend the tokens? (2) Which models are more token-efficient? and (3) Can agents predict their token usage before task execution? In this paper, we present the first systematic study of token consumption patterns in agentic coding tasks. We analyze trajectories from eight frontier LLMs on SWE-bench Verified and evaluate models’ ability to predict their own token costs before task execution. We find that: (1) agentic tasks are uniquely expensive, consuming 1000x more tokens than code reasoning and code chat, with input tokens rather than output tokens driving the overall cost; (2) token usage is highly variable and inherently stochastic: runs on the same task can differ by up to 30x in total tokens, and higher token usage does not translate into higher accuracy; instead, accuracy often peaks at intermediate cost and saturates at higher costs; (3) models vary substantially in token efficiency: on the same tasks, Kimi-K2 and Claude-Sonnet-4.5, on average, consume over 1.5 million more tokens than GPT-5; (4) task difficulty rated by human experts only weakly aligns with actual token costs, revealing a fundamental gap between human-perceived complexity and the computational effort agents actually expend; and (5) frontier models fail to accurately predict their own token usage (with weak-to-moderate correlations, up to 0.39) and systematically underestimate real token costs. Our study offers new insights into the economics of AI agents and can inspire future research in this direction.