arXiv: 2604.22312 · PDF
作者: Long Cheng, Ritchie Zhao, Timmy Liu, Mindy Li, Xianjie Qiao, Kefeng Duan, Yu-Jung Chen, Xiaoming Chen, Bita Darvish Rouhani, June Yang
单位: NVIDIA
主分类: cs.DC · 全部: cs.AR, cs.DC, cs.PF
命中关键词: llm, rag, serving, speculative decoding, attention, latency
TL;DR
GVR 利用相邻 decode 步骤之间 Top-K 的时间相关性,在 Blackwell 上实现数据感知的精确 Top-K,平均单算子加速 1.88×,DeepSeek-V3.2 在 100K 上下文下端到端 TPOT 提升最多 7.52%。
核心观点
- 长上下文 LLM serving 中,稀疏注意力 decode 阶段的精确 Top-K 是显著延迟瓶颈。
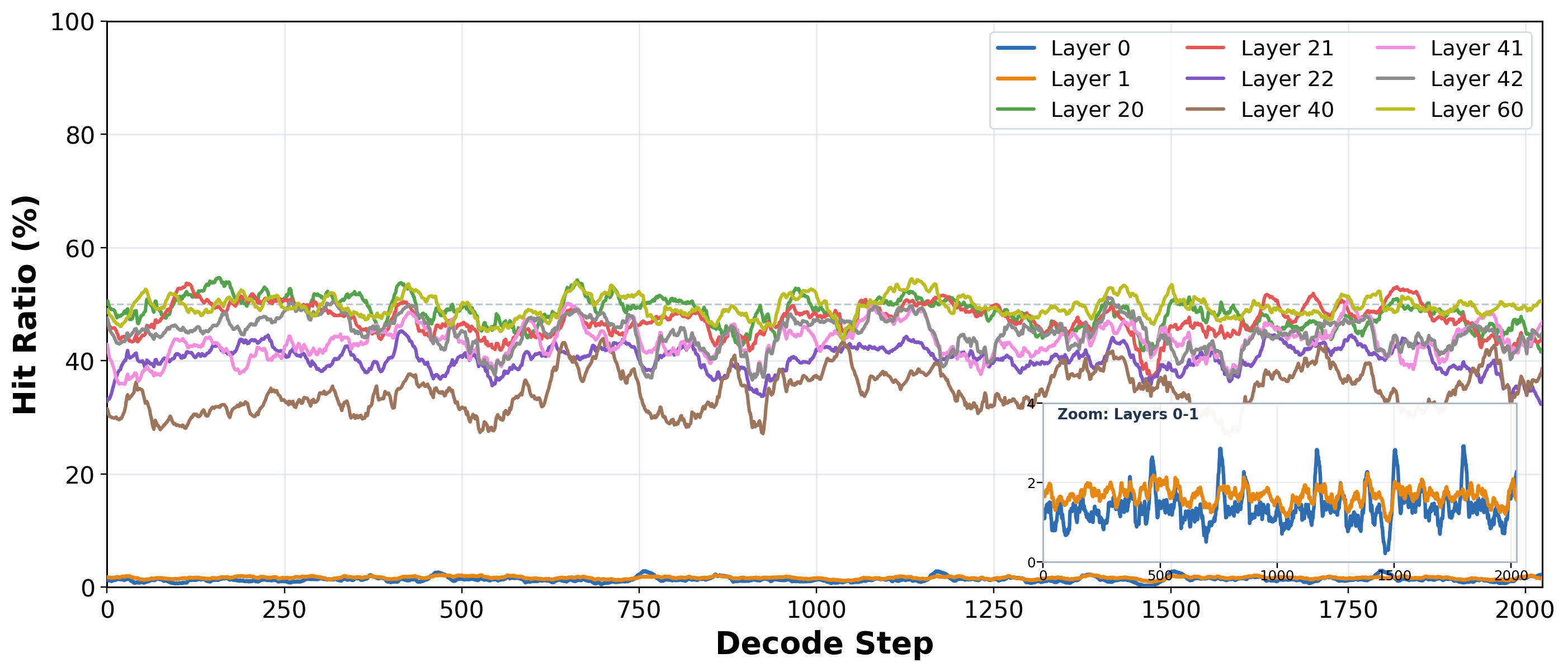
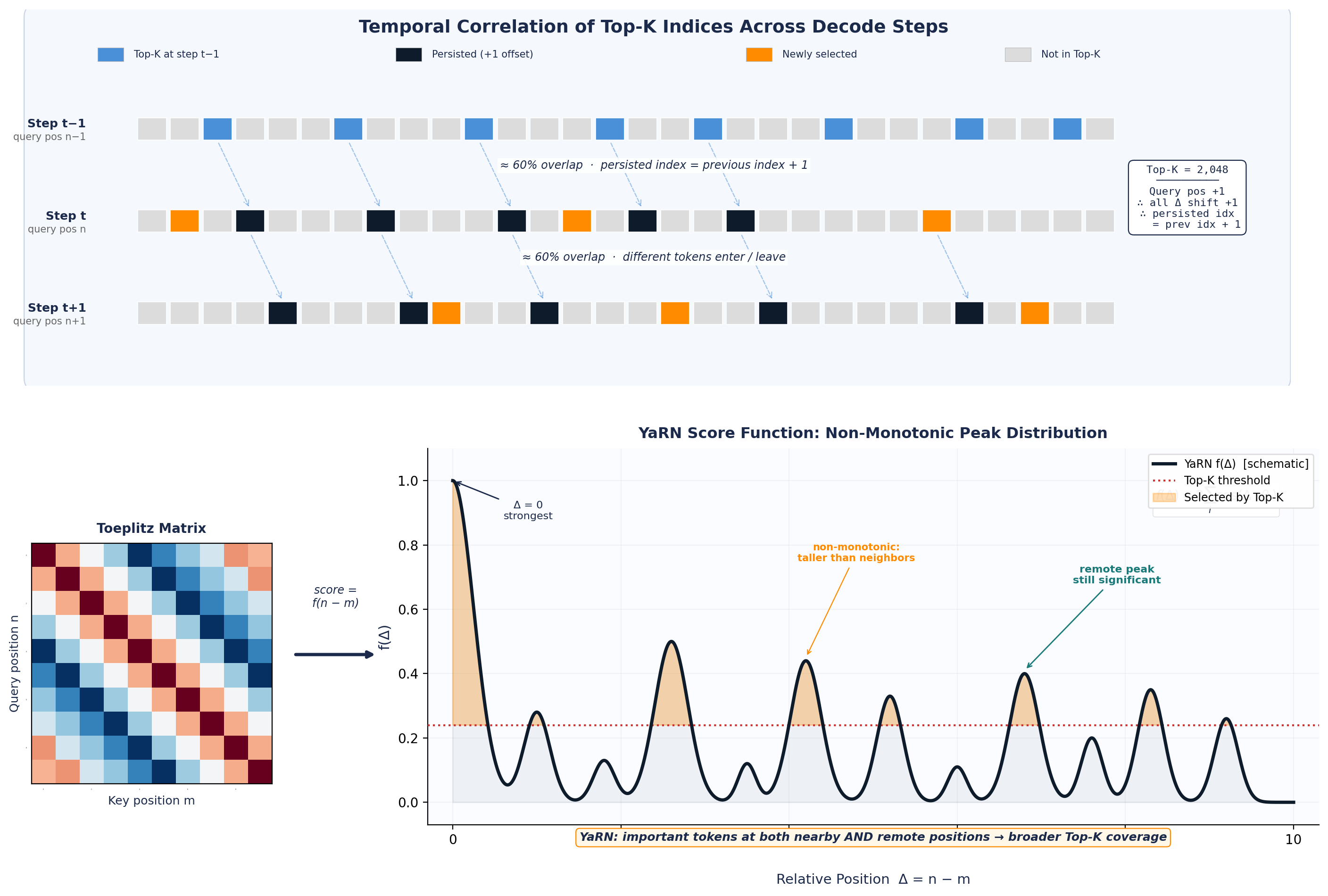
- DeepSeek Sparse Attention (DSA) indexer 分数具有 Toeplitz / RoPE 结构,使相邻 decode 步的 Top-K 高度相关(约 60% token 持留,40% 变化)。
- 提出 Guess-Verify-Refine (GVR):以上一步 Top-K 作为预测信号,做数据感知的精确 Top-K。
- 在 TensorRT-LLM DSA 栈上实现并验证,保持 bit-exact 输出。
方法
- Guess:使用上一 decode 步的 Top-K 作为预测。
- Verify:基于预索引统计,用 secant-style 计数在 1–2 次 global pass 内收敛到有效阈值。
- Refine:采用 ballot-free collector 收集候选,并在 shared memory 内完成精确选择。
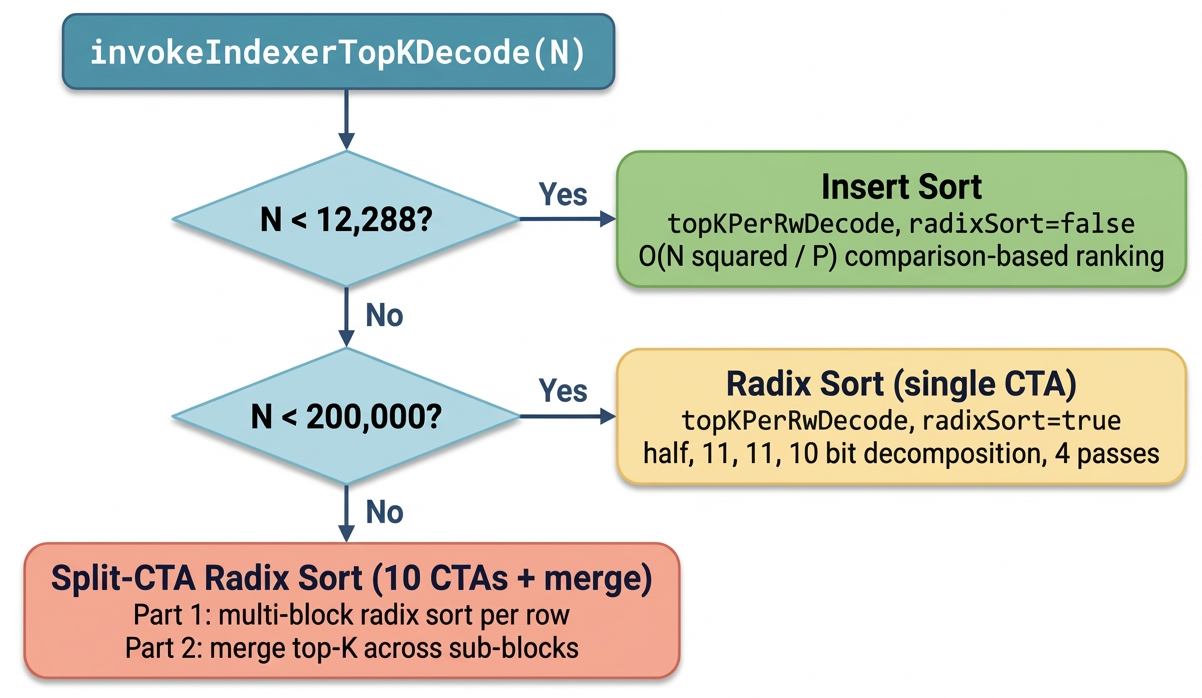
- 原生 decode-stage Top-K dispatch 根据序列长度选择 insert sort / radix sort / multi-CTA split,GVR 替换此路径。
- 将算法行为连接到 DSA indexer 分数的 Toeplitz/RoPE 结构以解释时间稳定性。
实验
- 工作负载:DeepSeek-V3.2,集成在 TensorRT-LLM。
- 基线:生产级 radix-select kernel。
- 部署场景:TEP8 min-latency,含 100K 上下文以及 speculative decoding 设置。
- 基准数据:SWE-bench 衍生 LongSeqTasks(如 swe_bench_64k.jsonl,2025 生成 token)。
- 指标:单算子加速比、端到端 TPOT、bit-exact 正确性。
结果
- 单算子平均加速 1.88×,per layer per step 峰值 2.42×。
- 100K 上下文下端到端 TPOT 最多改善 7.52%,上下文更长时收益更大。
- speculative decoding 下收益更小但仍为正。
- Top-K 输出与基线 bit-exact 一致。
为什么重要
为 Blackwell 上的稀疏注意力 serving 提供了一个可直接落地的数据感知 Top-K kernel,解决长上下文推理中的隐性瓶颈,对 LLM 推理基础设施构建者尤其有价值;思路可推广到其他具时间稳定性的稀疏注意力 decoder。
与已有工作的关系
- 建立在 DeepSeek Sparse Attention (DSA) 与 DeepSeek-V3.2 之上。
- 优化对象是 TensorRT-LLM 中的 radix-select Top-K kernel。
- 与 RoPE、Toeplitz 结构分析相关;与一般稀疏/Top-K attention (如 Quest 等) 思路互补。
尚未回答的问题
- 能否推广到非 DSA 的稀疏注意力 decoder?
- 对 prefill 阶段或多 token 并行 decode 是否同样有效?
- 在 Hopper 等非 Blackwell 架构上的收益与可移植性?
- 极端时间相关性失效(突变上下文)时的最坏情况表现?
原始摘要(中文翻译)
稀疏注意力解码器依赖精确的 Top-K 选择来为每个 query token 挑选最重要的 key-value 条目。在长上下文 LLM serving 中,这一 Top-K 阶段在每次 decode query 时都会运行一次,即使 indexer 和 attention kernel 已经高度优化,它仍会成为显著的延迟瓶颈。我们提出 Guess-Verify-Refine (GVR),一种在 NVIDIA Blackwell 上针对稀疏注意力解码的数据感知精确 Top-K 算法。GVR 利用相邻 decode 步之间的时间相关性:使用上一步的 Top-K 作为预测信号,计算预索引统计,通过 secant 风格的计数在 1–2 次全局 pass 内收敛到一个有效阈值,再用 ballot-free collector 验证候选,最后在 shared memory 中完成精确选择。我们将该行为连接到 DeepSeek Sparse Attention (DSA) indexer 分数的 Toeplitz / RoPE 结构,并在集成于 TensorRT-LLM 的真实 DeepSeek-V3.2 工作负载上验证该设计。GVR 相对于生产级 radix-select kernel 实现了平均 1.88× 的单算子加速,每层每步最高可达 2.42×,同时保持 bit-exact 的 Top-K 输出。在受控的 TEP8 最小延迟部署中,它在 100K 上下文下将端到端 TPOT 最多提升 7.52%,上下文越长收益越大,在 speculative decoding 下收益较小但仍为正。尽管目前在 Blackwell 上的 TensorRT-LLM DSA 栈中实现并验证,但同样原则可能推广到 decode 阶段 Top-K 表现出时间稳定性的其他稀疏注意力解码器。