arXiv: 2604.24013 · PDF
作者: Rezaul Karim, Austin Wen, Wang Zongzuo, Weiwei Zhang, Yang Liu, Walid Ahmed
单位: Toronto Ascend Team, Huawei
主分类: cs.LG · 全部: cs.CV, cs.DC, cs.LG
命中关键词: large language model, llm, inference, distributed training, parallelism, gpu, throughput, latency
自动分析不可用(claude CLI timeout)。展示原始摘要。
摘要
The rapid growth in the size of large language models has necessitated the partitioning of computational workloads across accelerators such as GPUs, TPUs, and NPUs. However, these parallelization strategies incur substantial data communication overhead significantly hindering computational efficiency. While communication-computation overlap presents a promising direction, existing data slicing based solutions suffer from tail latency. To overcome this limitation, this research introduces a novel communication-computation overlap technique to eliminate this tail latency in state of the art overlap methods for distributed LLM training. The aim of this technique is to effectively mitigate communication bottleneck of tensor parallelism and data parallelism for distributed training and inference. In particular, we propose a novel method termed Flash-Overlap that replaces conventional collective operations of reduce-scatter and all-gather with decomposed peer-to-peer (P2P) communication and schedules partitioned computations to enable fine-grained overlap. Our method provides an exact algorithm for reducing communication overhead that eliminates tail latency. Moreover, it presents a versatile solution compatible with data-parallel training and various tensor-level parallelism strategies, including TPSP and UP. Experimental evaluations demonstrate that our technique consistently achieves lower latency, superior Model FLOPS Utilization (MFU), and high throughput.
论文图表
图 1: Figure 2 : All Gather (AG) operation showing initial state and communication pattern on the left and final state on the right.
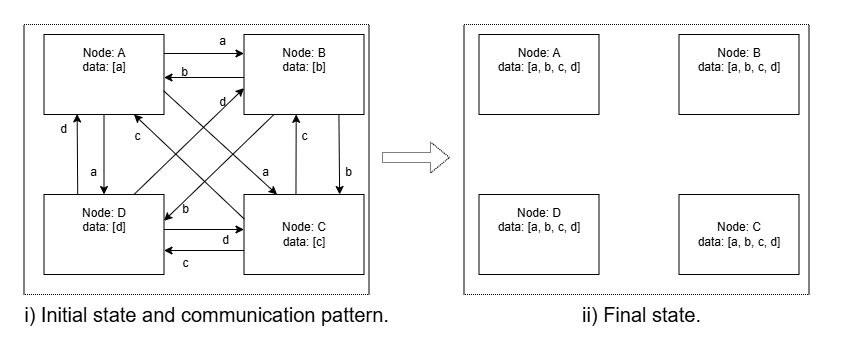
图 2: Figure 3 : Reduce-Scatter (RS) operation showing initial state and communication pattern on the left and final state on the right.
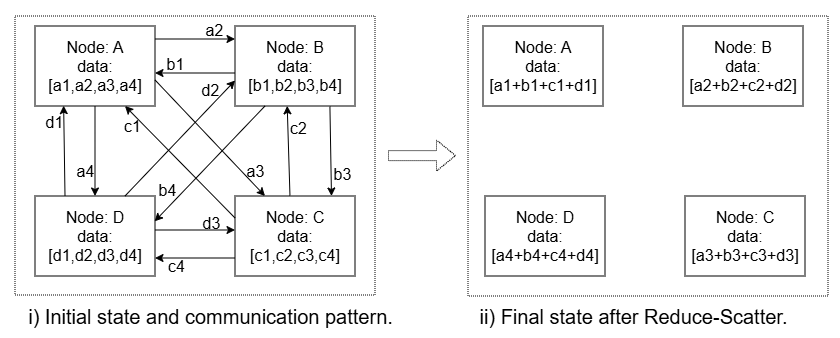
图 3: Figure 4 : Ring implementation of All-Gather operation showing example for four compute ranks.
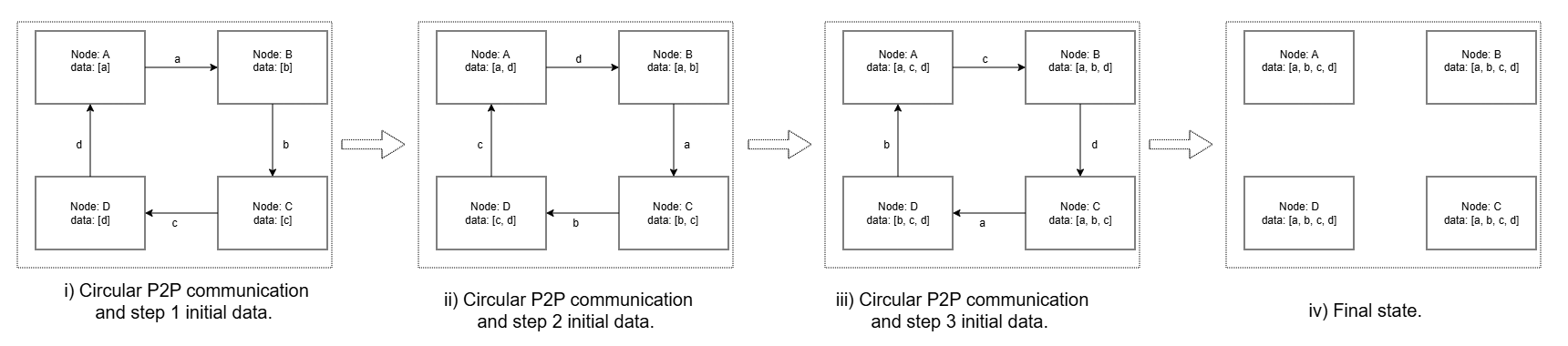
图 4: Figure 5 : Ring implementation of Reduce-Scatter operation showing example for four compute ranks.
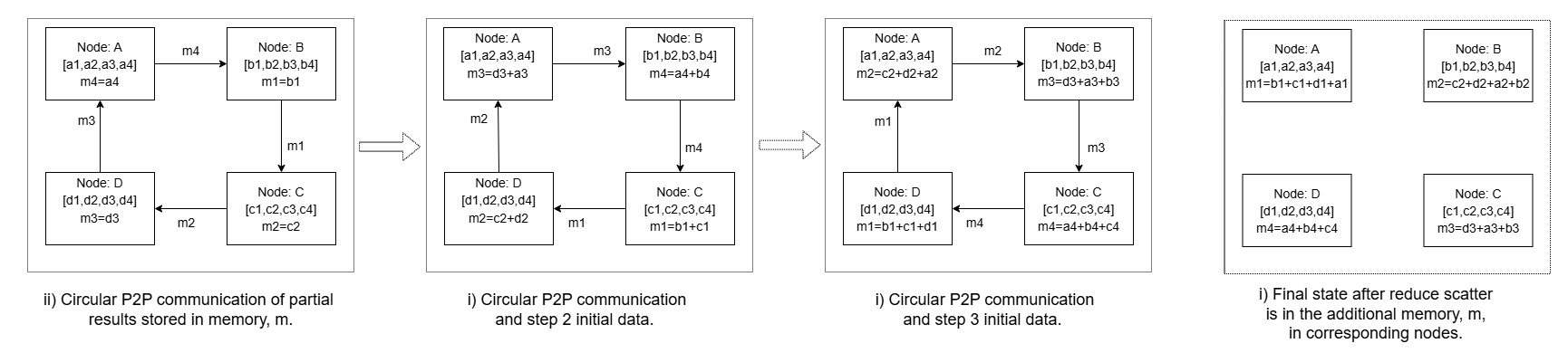
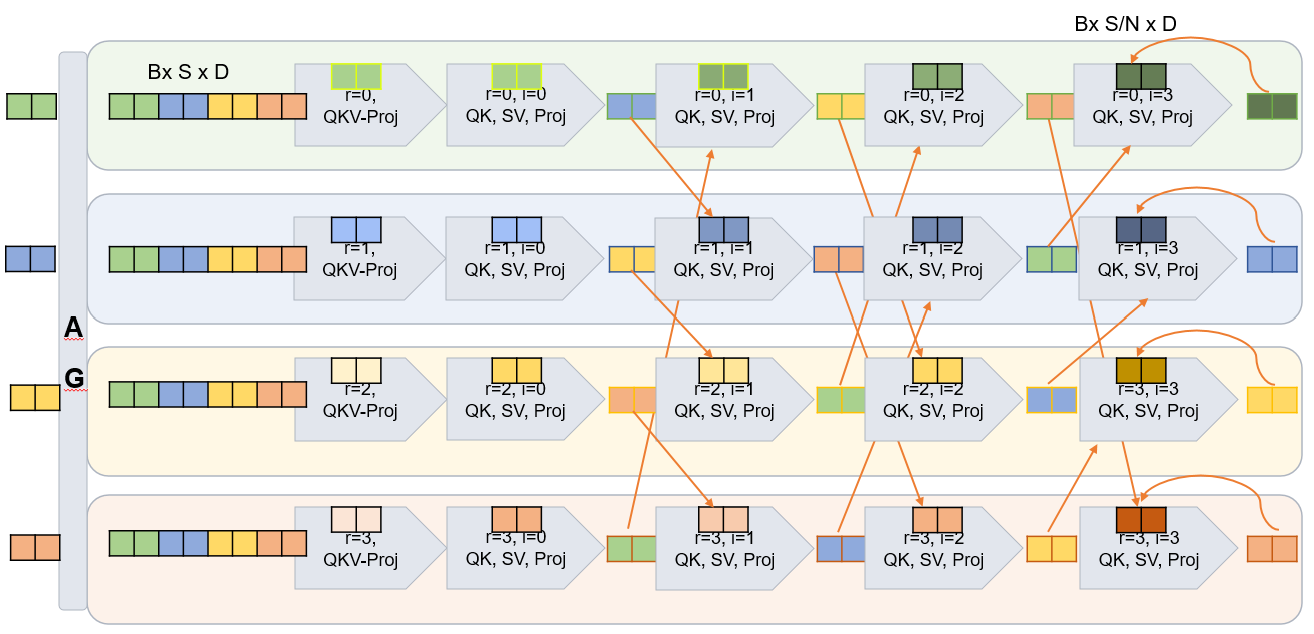
图 5: Figure 6 : Four-rank example of Flash All Gather , showing the ring-ordered breakdown of the collective into peer-to-peer communication steps with interleaved partial-output computation to achieve compute–communication overlap.
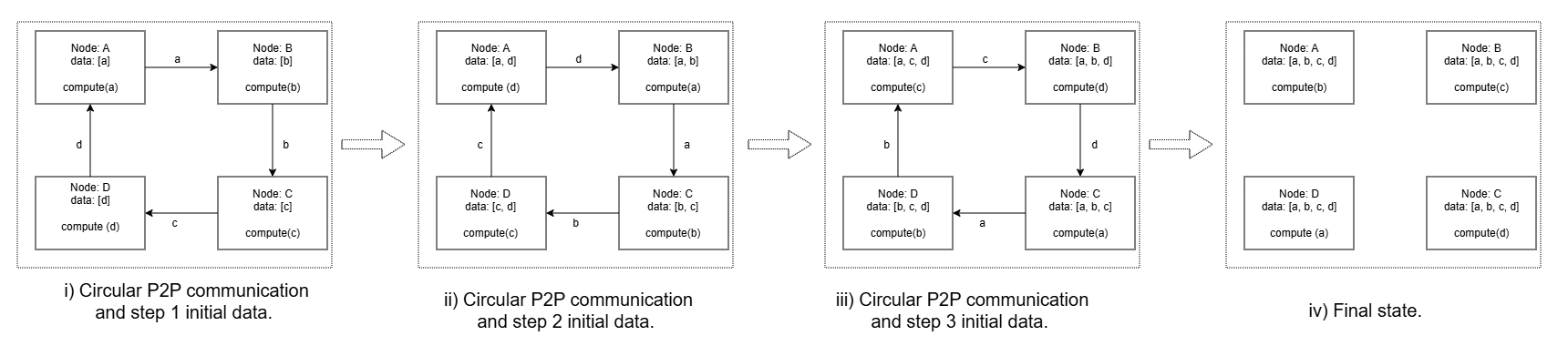
图 6: Figure 7 : Four-rank example of Flash Reduce Scatter , showing the ring-ordered breakdown of the Reduce Scatter collective into peer-to-peer communication steps with interleaved partial-output computation to achieve compute–communication overlap.
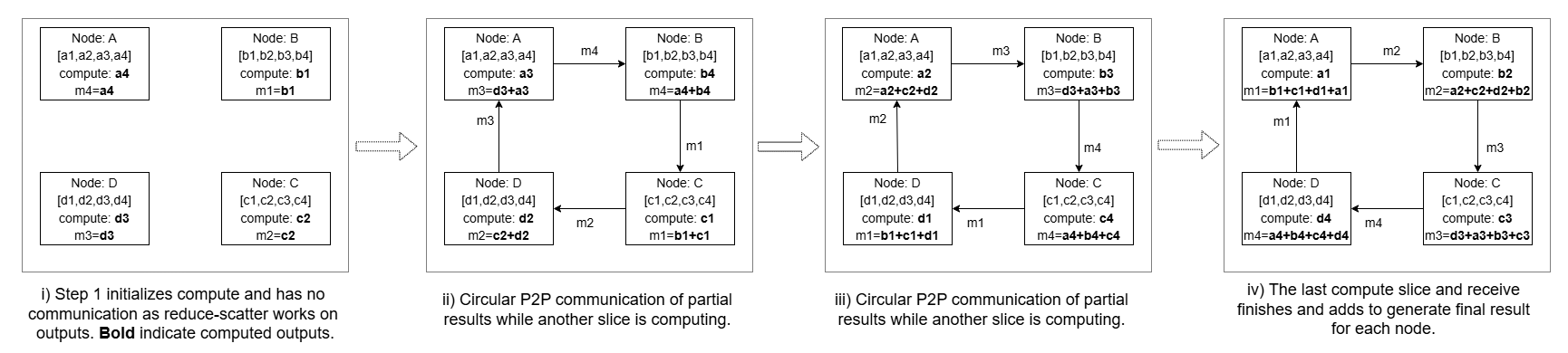
图 7: (a) Attention with tensor parallelism (TP) using non overlapped reduce-scatter resulting in communication overhead.
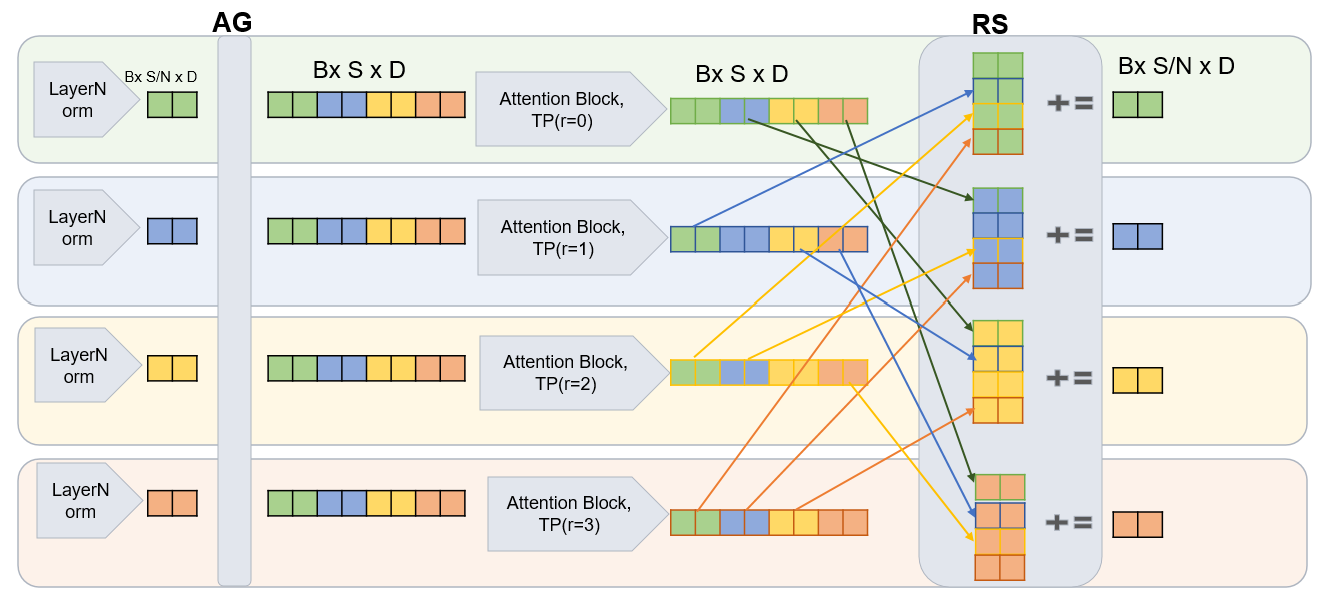
图 8: (b) Computation of the Query-Split Flash-RS Attention with TP using asynchronous P2P decomposed communication overlapping with computations.