arXiv: 2604.24013 · PDF
Authors: Rezaul Karim, Austin Wen, Wang Zongzuo, Weiwei Zhang, Yang Liu, Walid Ahmed
Affiliations: Toronto Ascend Team, Huawei
Primary category: cs.LG · all: cs.CV, cs.DC, cs.LG
Matched keywords: large language model, llm, inference, distributed training, parallelism, gpu, throughput, latency
TL;DR
FlashOverlap 将 Reduce-Scatter 与 All-Gather 分解为异步 P2P 通信,并按 rank 自适应调度分片计算,使最后一块数据的计算不再依赖通信,从而消除数据切分类方案的 tail latency,在 TP=4、(b,s,d)=(32,4096,4096) 的 MLP 上把通信开销从 43.8 ms 降至 0.1 ms(99.8% 削减)。
Motivation
分布式 LLM 训练/推理依赖 TP、TPSP、DP、Ulysses 等并行,但 all-reduce / reduce-scatter / all-gather / all-to-all 会带来严重通信瓶颈,尤其在需要跨节点时限制了 intra-layer 并行的可扩展性。主流框架 Megatron、MindSpeed (Ascend MC2)、Ascend CoC 采用"数据切分 + 异步通信"来把中间块通信藏在计算后面——当通信比计算短时大部分可以重叠,但最后一个 chunk 的通信必然暴露,形成 tail overhead;把切片做得更细又会让 GEMM 变成 memory-bound,反而更慢。另一类"算法分解"路线(如 Google Decompose on TPU)把集合通信拆成一串非阻塞步骤,但在中间步骤仍有强同步,且总通信量上升。作者因此想要一个"exact"、无 tail、且兼容 TPSP/UP/DP 的统一方案——面向同时运行 Transformer、Mamba、Hybrid 模型的 vLLM/Megatron 型部署者,把 TP/TPSP 从"单节点内才划算"扩展到跨节点。
Key Ideas
- 用 decomposed P2P 替代 ring collective,消除中间同步;
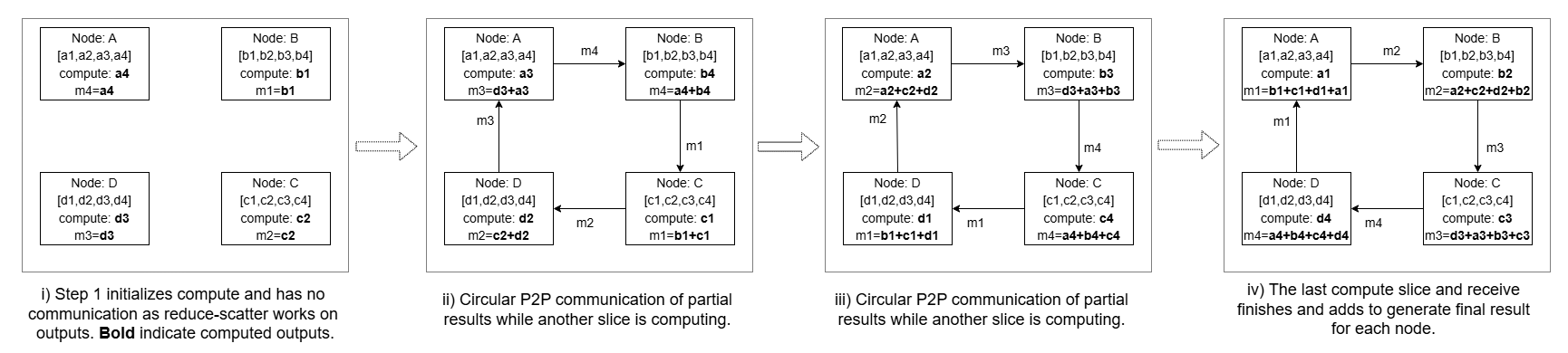
- Rank-adaptive 调度:AG 先算本地已有 slice、RS 把留在本 rank 的 slice 放到最后算,使最后一步计算不依赖通信,彻底消除 tail;
- 当 T_comm ≤ T_comp 时通信 100% 被隐藏,否则也达到"最大可能"的重叠;
- 统一框架覆盖 DP / TP / TPSP / UP,含 Row-Parallel、Column-Parallel、Query-Split Attention、Flash-All-to-All 四种实例化;
- 与 FlashAttention、batch 大小、序列长度正交,batch-size agnostic。
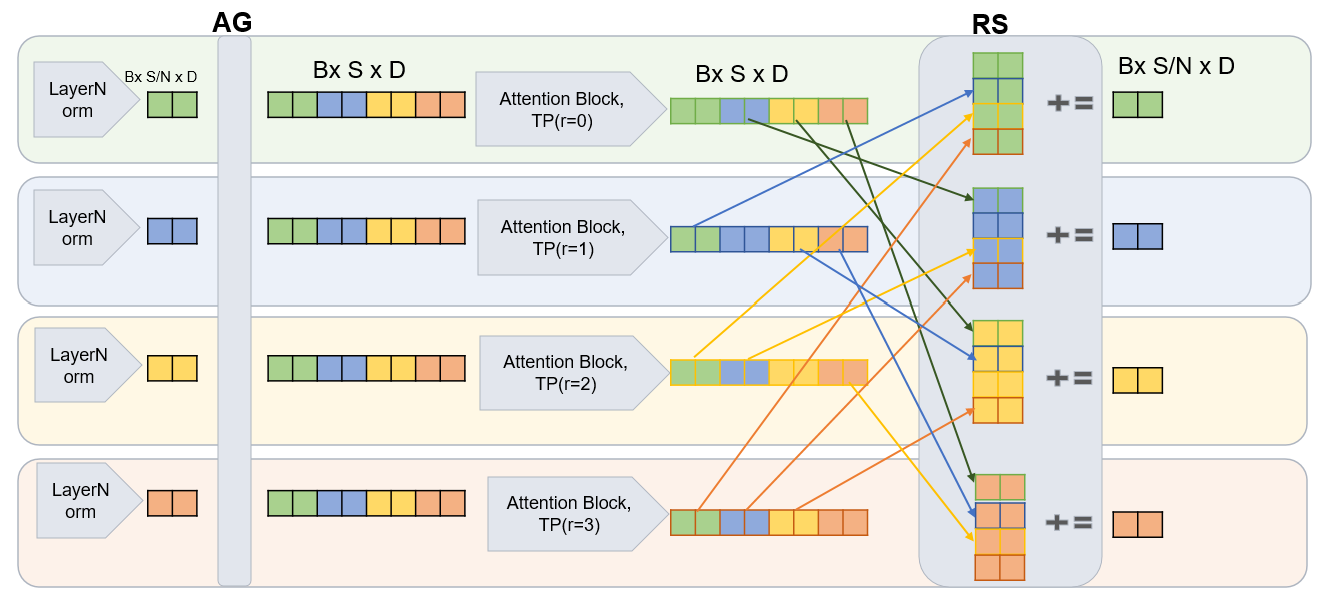 上图支撑 “Key Ideas” 中 tail 消除机制:四 rank 执行 Flash-Reduce-Scatter 时,collective 被分成 N-1 步 P2P 发送/接收,每步之间塞入一个 partial-output 计算;本 rank 最后要保留的 slice 放到循环最末一步计算,此时已不再需要通信,所以"尾巴"被吃掉。论文用这一点解释为什么 Flash-RS 能做到接近 100% overlap,读者即便跳过图也能从该调度顺序理解 tail-free 的来源。
上图支撑 “Key Ideas” 中 tail 消除机制:四 rank 执行 Flash-Reduce-Scatter 时,collective 被分成 N-1 步 P2P 发送/接收,每步之间塞入一个 partial-output 计算;本 rank 最后要保留的 slice 放到循环最末一步计算,此时已不再需要通信,所以"尾巴"被吃掉。论文用这一点解释为什么 Flash-RS 能做到接近 100% overlap,读者即便跳过图也能从该调度顺序理解 tail-free 的来源。
Method
Flash-Overlap 的两条原语是 Flash-AG(Algorithm 1)和 Flash-RS(Algorithm 2)。核心循环都是:ring 方向向 (r+1) mod N 异步 p2p_send,从 (r-1+N) mod N 异步 p2p_recv,在通信进行时调用 compute_partial_output 算当前 slice;差异在顺序——AG 先算本地 slice 再依次算收到的 slice,RS 则反过来把本 rank 最终保留的 slice 安排在最后一步(此时 i=N-1 跳过通信)。序列长 S 被切成 m·N 份(默认 m=1,N=TP 世界大小)。在此基础上做四种 instantiation:Row-Parallel Projection(Algorithm 3,compute_partial_output=W_o^r·X_s[j],适用 MLP/Attention/Mamba 的 RS 端);Column-Parallel Projection(MLP/QKV/in-proj 的 AG 端);Query-Split Attention(Algorithm 4,按 Q 切片,先算 scores/softmax/V/out-proj 再发 P2P,提高被重叠的计算量,适合高 FLOPS 低带宽硬件,且与 FlashAttention 正交);Flash-All-to-All for Ulysses(Algorithm 5,用每步 per-query-slice 的 attention 掩盖 all-to-all)。
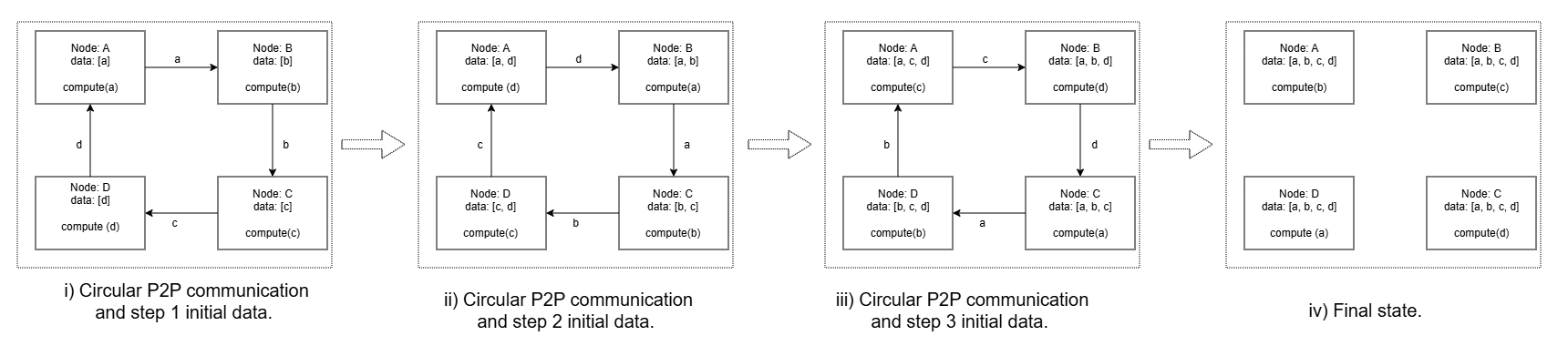 图展示的是传统 Ring Reduce-Scatter 基线:四 rank 绕环走 N-1 轮,每轮全员都必须完成后才能进入下一轮;这种强同步正是论文在 Motivation/Related Work 指控的"算法分解"方案的瓶颈。作者把它作为对照——Flash-RS (Figure 7) 去掉了这种 round barrier,用异步 P2P + partial-output 交错替换。
图展示的是传统 Ring Reduce-Scatter 基线:四 rank 绕环走 N-1 轮,每轮全员都必须完成后才能进入下一轮;这种强同步正是论文在 Motivation/Related Work 指控的"算法分解"方案的瓶颈。作者把它作为对照——Flash-RS (Figure 7) 去掉了这种 round barrier,用异步 P2P + partial-output 交错替换。
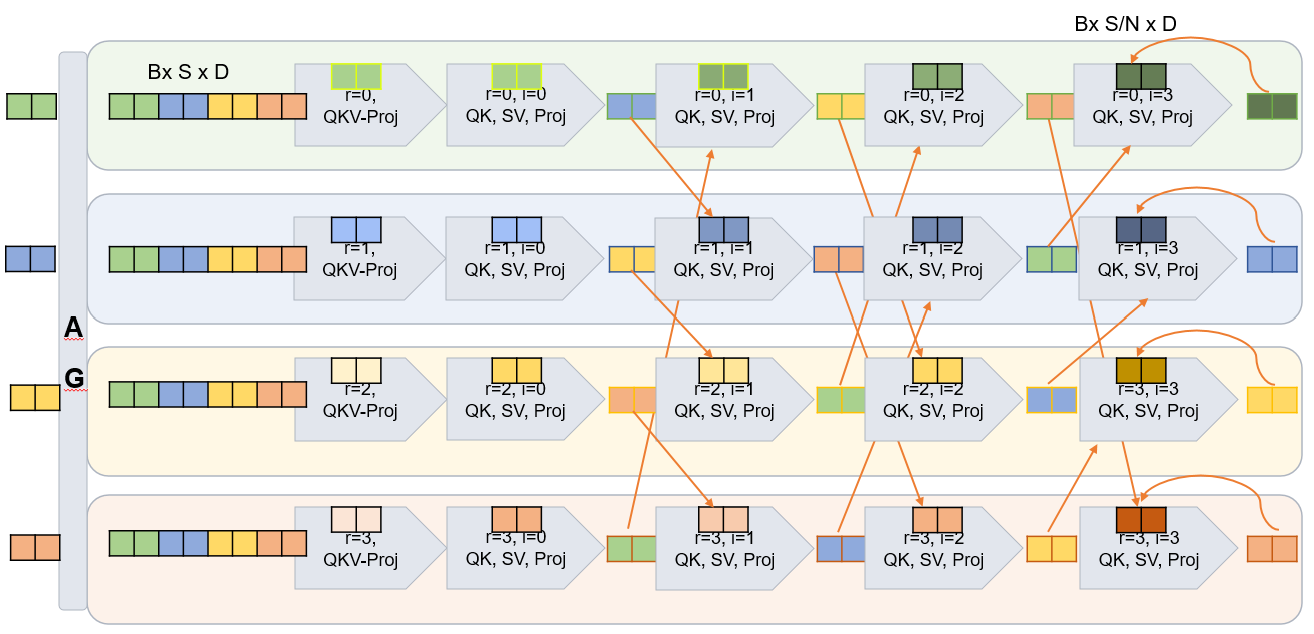 该图配合 Query-Split Attention(Algorithm 4)使用:(a) 非重叠 TP attention 的 reduce-scatter 在 attention 算完之后才发生,形成通信 bubble;(b) Query-Split Flash-RS 把 Q 切成 N 片,每算完一片就异步 P2P 发送其 out-proj 结果,让通信藏在下一片 Q 的 scores/softmax/V 计算后面。论文未给该图本身的数字,但对应 Table 4 的 “Query Split” 列就是这条路径的端到端延迟。
该图配合 Query-Split Attention(Algorithm 4)使用:(a) 非重叠 TP attention 的 reduce-scatter 在 attention 算完之后才发生,形成通信 bubble;(b) Query-Split Flash-RS 把 Q 切成 N 片,每算完一片就异步 P2P 发送其 out-proj 结果,让通信藏在下一片 Q 的 scores/softmax/V 计算后面。论文未给该图本身的数字,但对应 Table 4 的 “Query Split” 列就是这条路径的端到端延迟。
Experiments
实现 Flash-RS,应用到 TPSP 的 MLP(row-parallel linear)和 Attention(row-parallel + query-split)两类层;对比 Vanilla(无重叠)基线与 Data Slicing(Megatron/MindSpeed 风格)。配置 d_model=4096、TP=4,MLP 扫序列 1K→16K(batch 相应从 128 降到 8 保持内存),Attention 扫 (B,S) = (64,1024)/(32,2048)/(16,4096)/(4,8192),embedding=4096,forward 延迟取 10 次平均。硬件与加速器型号论文未指明。
Results
- MLP, (b,s,d)=(32,4096,4096), TP=4 (Table 1): Vanilla 通信开销 43.8 ms、E2E 122.3 ms;Data Slicing 通信 7.1 ms (−83.9%)、E2E 83.9 ms (−31.4%);本文 0.1 ms (−99.8%)、E2E 77.1 ms (−36.9%),相对 Data Slicing 再快 8.1%。
- Scaling (Table 3): Flash-RS 在 1K–16K 序列上通信缩减稳定在 99.7–99.8%,Data Slicing 只有 77.9–85.2%;E2E 改善 35.0–40.2% vs 29.5–35.0%。
- Attention forward latency (Table 4): 在 16×4096 下,Baseline 270.1 ms → Slicing 246.1 → Row-Parallel 230.9 → Query-Split 215.8 ms;在 4×8192 下 Data Slicing 反而恶化到 279.7 ms(高于 195.6 ms 的 Baseline),而 Query-Split 降到 145.1 ms,是全文最鲜明的差距。
- Sanity check: TPSP 配置输出与非 TPSP 一致。
摘要所说的 “lower latency, superior MFU, high throughput” 中,MFU 与 throughput 的具体数字未在正文中给出。
Conclusion
实用者要记住的一点是:只要能把本 rank 最终要保留的那块计算排到 ring 的最后一步,就可以把 Data Slicing 里永远存在的"尾巴"完全吃掉——在 TP=4 MLP 上表现为通信开销 7.1 ms → 0.1 ms。但实验只有 TP=4 的单节点尺度,没有多节点、没有具体 GPU/NPU 型号、没有端到端模型训练曲线,也没有 MFU/throughput 数字(尽管摘要声称),Mamba 和 UP 只有算法描述没有测量。Query-Split 在 4×8192 的配置下相对 Data Slicing 提速最大,但也正是该配置下 Data Slicing 出现反常恶化,读者应谨慎看待该对比。
Novelty Check
作者自称最接近的是 Google 的 Decompose (Wang et al. 2022 [23]),把 collective 分解为异步非阻塞步骤;以及数据切分流派 Megatron、MindSpeed、Flux (Chang 2024)、Centauri (Chen 2024)、TileLink (Zheng 2025)。作者的"delta"是:tail-free 的 rank-adaptive 调度——让 RS 中本 rank 保留的 slice 最后计算、AG 中本地 slice 最先计算。独立看,这一思路在 ring-based RS 调度中并非完全新颖——Wang 2022 及部分 NCCL 调度工作都已意识到通过 slice 排序减少暴露步骤;真正新的是把它系统化到 TPSP、UP、DP 的统一 framework 并给出 Query-Split Attention 变体。ISO (Xiao 2024) 在 prefill 阶段做 sequence-level overlap,与 Query-Split 精神相近,论文有引用但未定量对比。总体属于"已有方向上的精细化工程化工作 + 合理的新变体",并非范式转变。
Open Questions
- 为何 Data Slicing 在 (B,S)=(4,8192) 下反常退化到 279.7 ms?是否 Flash-RS 的 99.8% 也受同样因素放大?
- 跨节点 TP/TPSP 场景的实际数字(摘要的卖点之一)并未给出;InfiniBand/NVLink 差异下 Flash-RS 是否仍 tail-free?
- Query-Split Attention 与 FlashAttention 的融合开销、在变长序列下的表现缺失。
- UP 的 Flash-All-to-All(Algorithm 5)无任何测量。
- 没有 MFU、throughput、训练端到端 loss 曲线的实测支持。
- m>1 时的收益 / 敏感性分析缺失。
Figures
Figure 1: Figure 2 : All Gather (AG) operation showing initial state and communication pattern on the left and final state on the right.
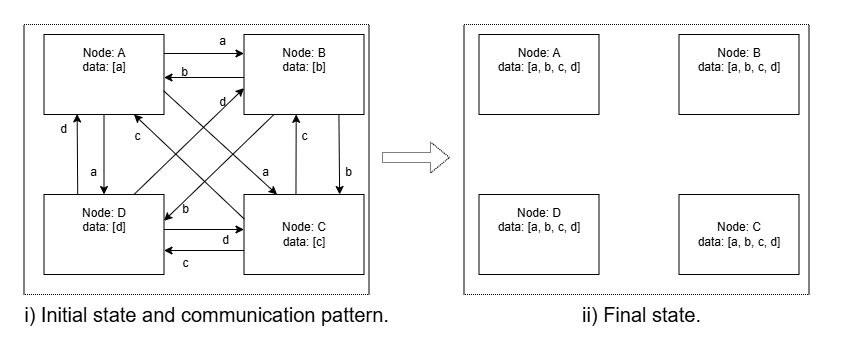
Figure 2: Figure 3 : Reduce-Scatter (RS) operation showing initial state and communication pattern on the left and final state on the right.
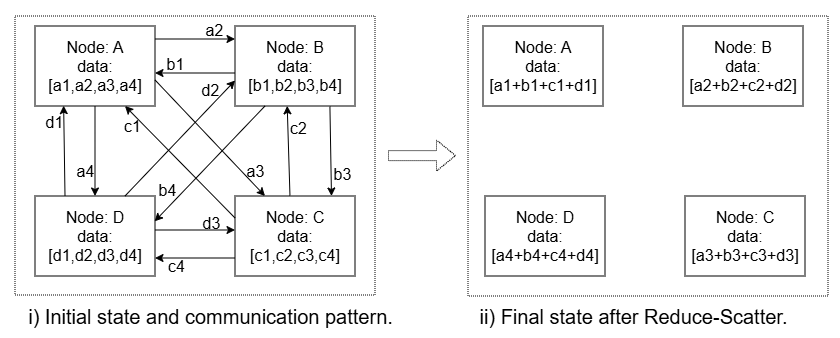
Figure 3: Figure 4 : Ring implementation of All-Gather operation showing example for four compute ranks.
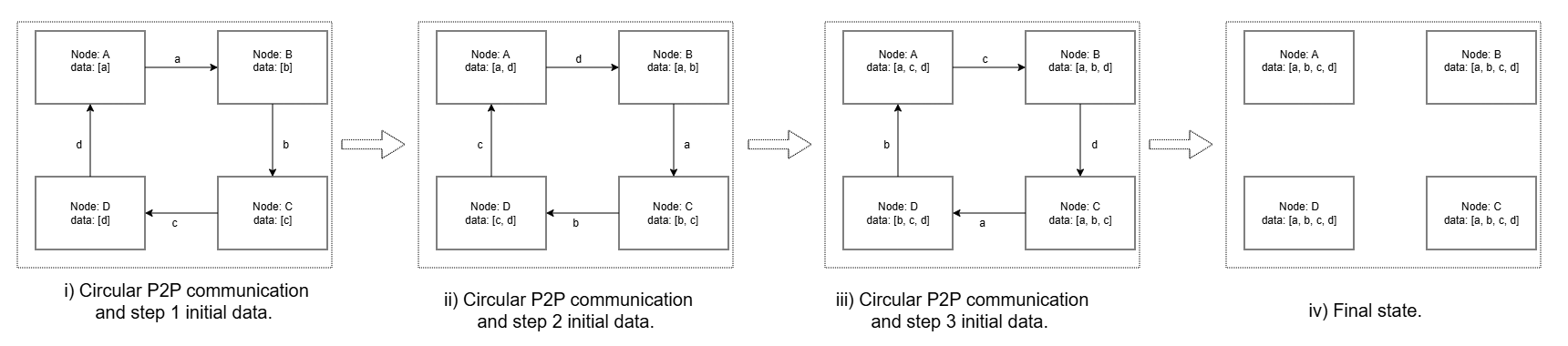
Figure 4: Figure 5 : Ring implementation of Reduce-Scatter operation showing example for four compute ranks.
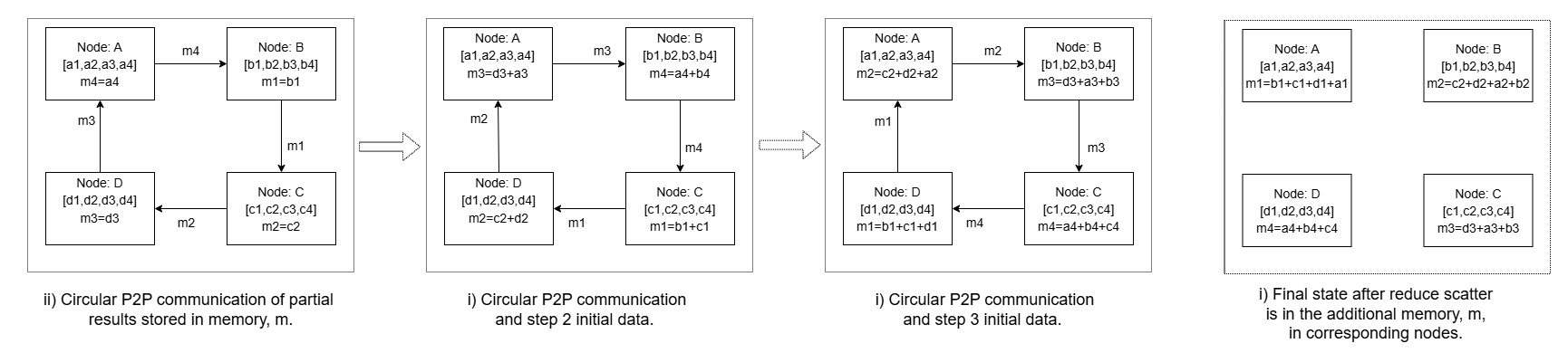
Figure 5: Figure 7 : Four-rank example of Flash Reduce Scatter , showing the ring-ordered breakdown of the Reduce Scatter collective into peer-to-peer communication steps with interleaved partial-output computation to achieve compute–communication overlap.
Original abstract
The rapid growth in the size of large language models has necessitated the partitioning of computational workloads across accelerators such as GPUs, TPUs, and NPUs. However, these parallelization strategies incur substantial data communication overhead significantly hindering computational efficiency. While communication-computation overlap presents a promising direction, existing data slicing based solutions suffer from tail latency. To overcome this limitation, this research introduces a novel communication-computation overlap technique to eliminate this tail latency in state of the art overlap methods for distributed LLM training. The aim of this technique is to effectively mitigate communication bottleneck of tensor parallelism and data parallelism for distributed training and inference. In particular, we propose a novel method termed Flash-Overlap that replaces conventional collective operations of reduce-scatter and all-gather with decomposed peer-to-peer (P2P) communication and schedules partitioned computations to enable fine-grained overlap. Our method provides an exact algorithm for reducing communication overhead that eliminates tail latency. Moreover, it presents a versatile solution compatible with data-parallel training and various tensor-level parallelism strategies, including TPSP and UP. Experimental evaluations demonstrate that our technique consistently achieves lower latency, superior Model FLOPS Utilization (MFU), and high throughput.