arXiv: 2604.24698 · PDF
作者: Yunze Xiao, Vivienne J. Zhang, Chenghao Yang, Ningshan Ma, Weihao Xuan, Jen-tse Huang
单位: CMU, UChicago, MIT, 2077.ai, UTokyo, RIKEN AIP, JHU
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, llm, agent, multi-agent, rag, reasoning
自动分析不可用(claude CLI timeout)。展示原始摘要。
摘要
Applications based on large language models (LLMs), such as multi-agent simulations, require population diversity among agents. We identify a pervasive failure mode we term \emph{Persona Collapse}: agents each assigned a distinct profile nonetheless converge into a narrow behavioral mode, producing a homogeneous simulated population. To quantify persona collapse, we propose a framework that measures how much of the persona space a population occupies (Coverage), how evenly agents spread across it (Uniformity), and how rich the resulting behavioral patterns are (Complexity). Evaluating ten LLMs on personality simulation (BFI-44), moral reasoning, and self-introduction, we observe persona collapse along two axes: (1) Dimensions: a model can appear diverse on one axis yet structurally degenerate on another, and (2) Domains: the same model may collapse the most in personality yet be the most diverse in moral reasoning. Furthermore, item-level diagnostics reveal that behavioral variation tracks coarse demographic stereotypes rather than the fine-grained individual differences specified in each persona. Counter-intuitively, \textbf{the models achieving the highest per-persona fidelity consistently produce the most stereotyped populations}. We release our toolkit and data to support population-level evaluation of LLMs.
论文图表
图 1: Figure 1: Persona collapse in LLM-based population simulation. Although two personas differ across multiple identity dimensions, Qwen3-32B assigns both the same neutral response on a socially sensitive judgment task. At the population level, the most conservative and most liberal persona pools also concentrate on the same Likert rating.
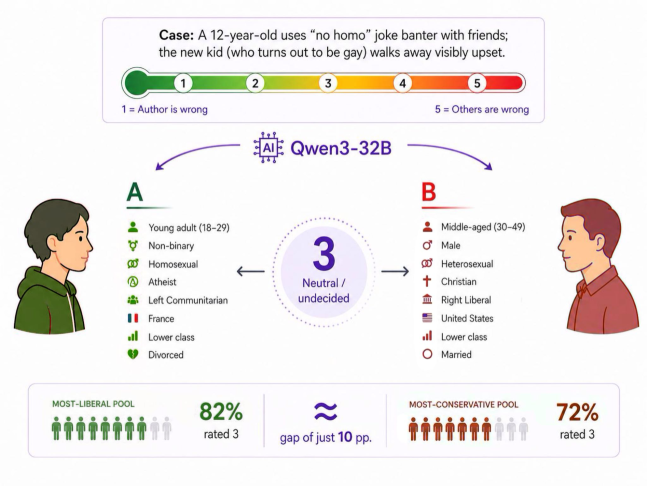
图 2: (a) Coverage.
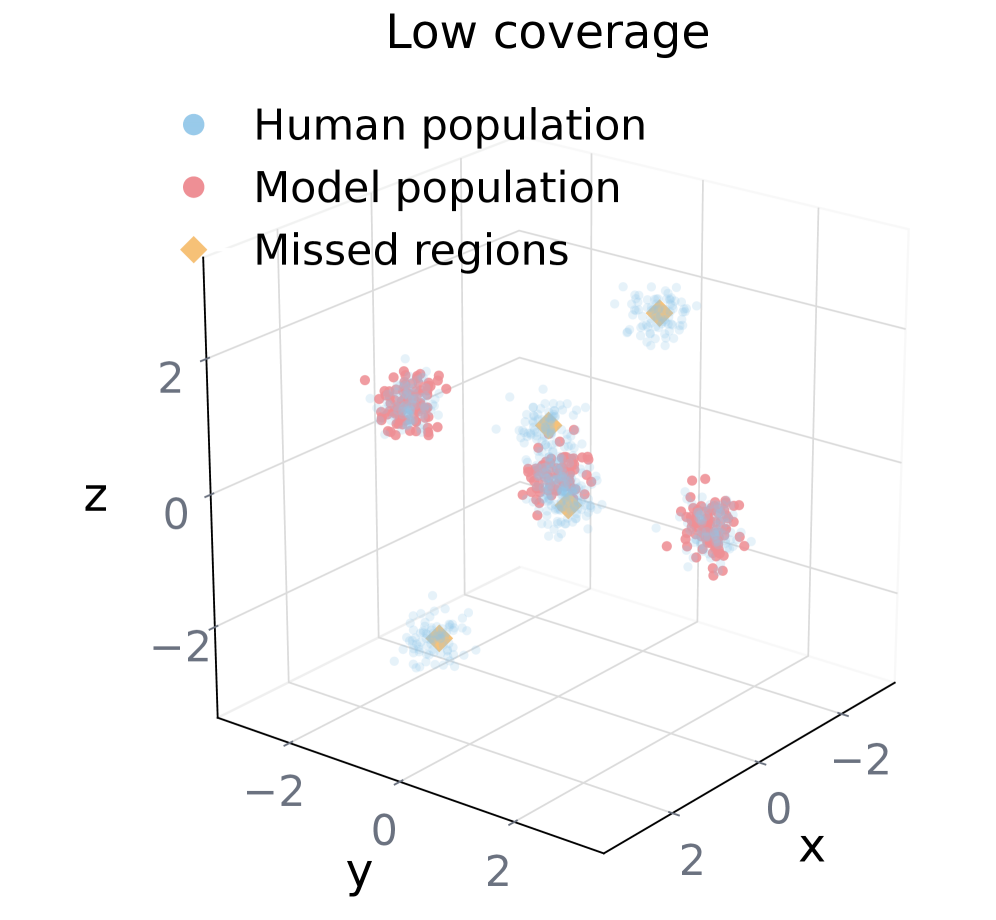
图 3: (b) Uniformity.
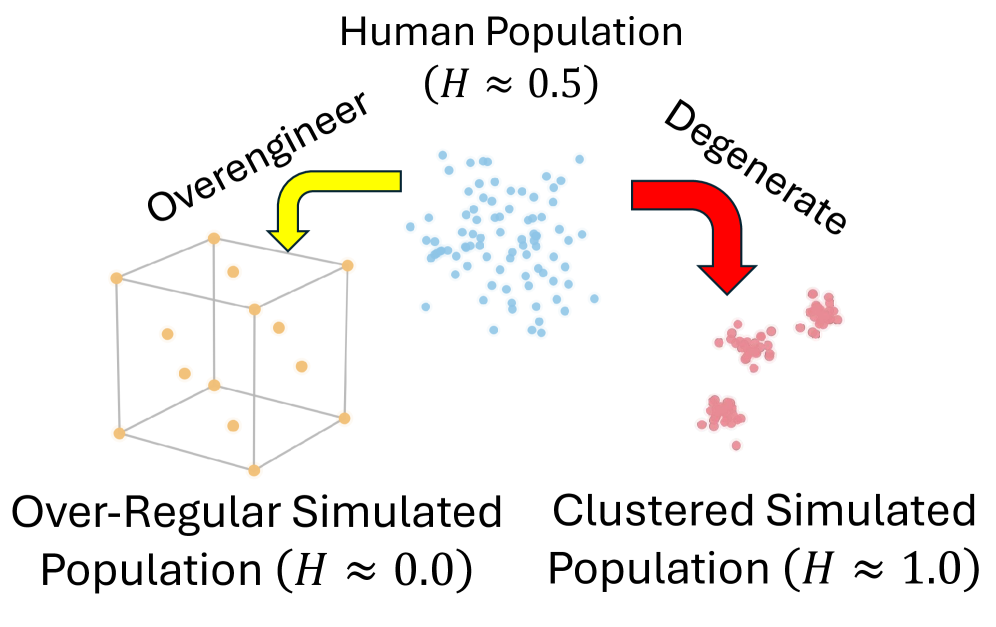
图 4: (c) Complexity.
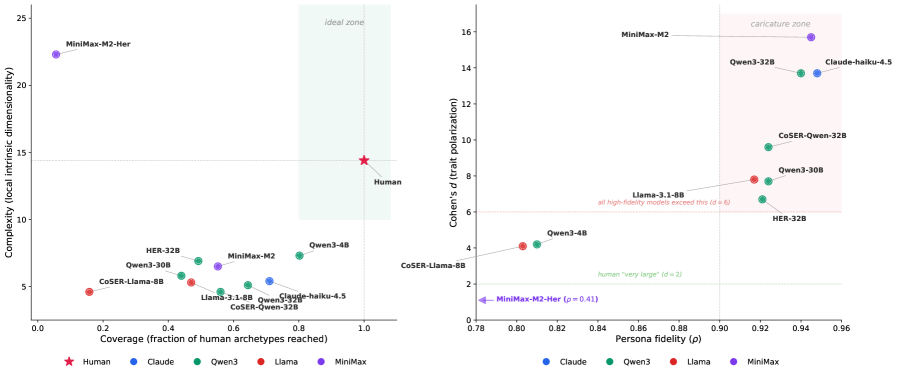
图 5: Figure 4: Population-level diagnostics on BFI-44 (10 models, 1,144 personas each). Left : Coverage vs. Complexity (LID). The human reference occupies the upper-right; no model simultaneously achieves high coverage and high complexity. Right : Persona fidelity ( ρ \rho ) vs. trait polarization (Cohen’s d d ). Every model with ρ > 0.9 \rho>0.9 produces d > 6 d>6 , far exceeding the d = 2