arXiv: 2604.24698 · PDF
Authors: Yunze Xiao, Vivienne J. Zhang, Chenghao Yang, Ningshan Ma, Weihao Xuan, Jen-tse Huang
Affiliations: CMU, UChicago, MIT, 2077.ai, UTokyo, RIKEN AIP, JHU
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, llm, agent, multi-agent, rag, reasoning
TL;DR
Ten LLMs asked to role-play 1,144 richly specified personas collapse into a narrow behavioral mode — agents converge despite distinct profiles. A geometric framework (Coverage, Uniformity, Complexity on a Behavioral Trait Matrix) plus item-level diagnostics shows collapse is multi-axis and task-contingent, and that the highest-fidelity models produce the most stereotyped populations.
Motivation
LLM-based social simulations, synthetic survey panels, and multi-agent studies (Park et al., 2023; Zhou et al., 2025) assume that a detailed persona — age, gender, nationality, political leaning, occupation — makes the model behave like a distinct individual. Existing evaluations measure “shallow fidelity”: can the agent mimic a single low-dimensional label, e.g. “sixty-year-old black woman”? Nobody has asked whether a population of 1,000 such agents actually spans human behavioral diversity, or silently converges. The authors show it converges hard: Qwen3-32B gives the most conservative and most liberal persona pool the same neutral rating on a sensitive judgment, and BFI-44 responses fragment into a few dense clusters instead of filling the space real humans occupy. The people hurt are teams running agent-based simulation, synthetic polling, or RL environments populated by “diverse” LLM agents; they currently trust per-agent fidelity metrics that are blind to population-level collapse. The gap is that prior work measures single-agent mimicry with embedding similarity or psychometric consistency, not whether the population as a distribution matches humans. The framing is honest — the authors explicitly scope to three instruments (BFI-44, moral reasoning, self-introduction) on ten models.
Key Ideas
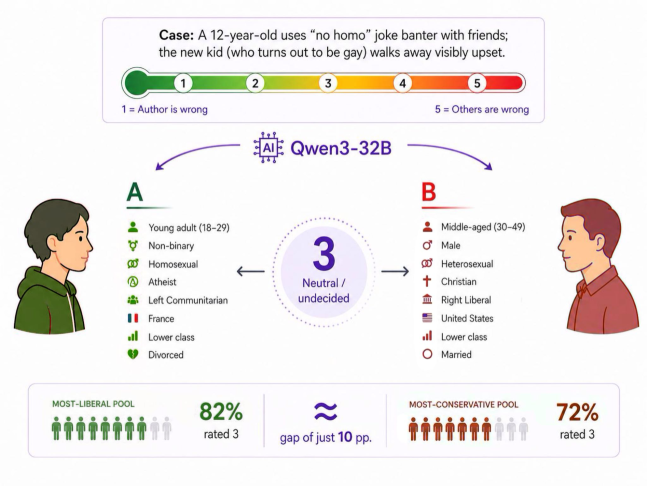
Figure 1 illustrates the phenomenon the paper names Persona Collapse: two personas differing across multiple identity dimensions (demographics, ideology) are both assigned the same neutral Likert rating by Qwen3-32B on a socially sensitive moral judgment, and at the population level the most conservative and most liberal persona pools concentrate on the same response. This motivates moving from per-persona fidelity to population-level geometric diagnostics.
- Population diversity ≠ per-agent fidelity; collapse is invisible to InCharacter-style probes.
- Three geometric axes on a Behavioral Trait Matrix 𝐁∈ℝ^{N×D}: Coverage (Naeem et al., 2020), Uniformity (Hopkins statistic; hyperspherical loss), Complexity (Local Intrinsic Dimensionality).
- Item-level diagnostics: inverse-Simpson effective Likert, variance decomposition, η² demographic clustering, incremental R² for attribute truncation.
- Collapse has two axes: Dimensions (diverse on coverage, flat on complexity) and Domains (same model collapses on personality but is diverse on moral reasoning).
- Fidelity Trap: high Spearman ρ per persona correlates with caricatured Cohen’s d between target groups.
- Attribute truncation hierarchy: Gender/Country survive, Social Class/Age get discarded.
Method
Each of 1,144 filtered personas (from 2,000 sampled across 26 dimensions) is serialized into a prompt prefix and run through three instruments: BFI-44 (44 5-point Likert items, 5 factors), Moral Reasoning (131 dilemmas, 5-point A-vs-B; Liu et al., 2025), and three free-form self-introductions. Responses form 𝐁_{BFI}∈ℝ^{N×44} and 𝐁_{Moral}∈ℝ^{N×131} per model. Coverage is the fraction of human BFI-44 archetype k-NN balls (Twin-2K-500, n=2,058) hit by ≥1 LLM persona. Uniformity is Hopkins H on random probes vs. data nearest neighbors (0.5 ideal; →1 clumped, →0 lattice). Complexity is median LID via Levina–Bickel MLE over k-NN distances. Item-level: inverse-Simpson effective Likert per column, Cohen’s d between High/Low target groups, η² across demographic variables, incremental R² adding political→gender→country→class with Dom% as share of strongest attribute (25% = balanced). Free-text is analyzed through four layers: keyword attribute detection, sentence-BERT embedding geometry, template-skeleton / opening-diversity, and ICC of linguistic features across the three samples.
Experiments
Ten models: Llama-3.1-8B-Instruct, Qwen3-4B, Qwen3-30B-A3B, Qwen3-32B, Claude-Haiku-4.5, MiniMax-M2, plus role-play set CoSER-Llama-8B, CoSER-Qwen-32B, HER-32B, MiniMax-M2-Her. Controlled comparisons: CoSER-Llama-8B vs. Llama-3.1-8B isolates PSFT; Qwen3-32B → CoSER-Qwen-32B → HER-32B traces base → SFT → SFT+RL; MiniMax-M2 vs. MiniMax-M2-Her isolates RL roleplay tuning. Thinking vs. non-thinking mode tested on Qwen3-32B. Reference distribution: Twin-2K-500 (n=2,058 humans) for BFI-44 only; no human reference exists for moral reasoning or self-introduction, so those rely on cross-model and item-level diagnostics. API calls via OpenRouter at default decoding except self-introduction (T=0.9, 1,024 tokens, 3 samples/persona).
Results
Full text available — Table 1, Table 2, Table 3, Figure 4 back the headline findings.
No model reaches the human BFI-44 reference (Cov=1.0, LID=14.4, Hop=0.57). Mode collapse: CoSER-Llama-8B compresses the Likert scale — 83.7% of responses at midpoint, EffL=1.36, Cov=0.16, Hop=0.91 (Table 1). Shallow coverage: Qwen3-4B hits Cov=0.80 but LID=7.3, ~half human (14.4); Claude-Haiku-4.5 similar (Cov=0.71, LID=5.4). Deep but misaligned: MiniMax-M2-Her has LID=22.3 and Hop=0.50 (only model near uniform) yet Cov=0.06 and ρ=0.41 — rich geometry disconnected from humans.
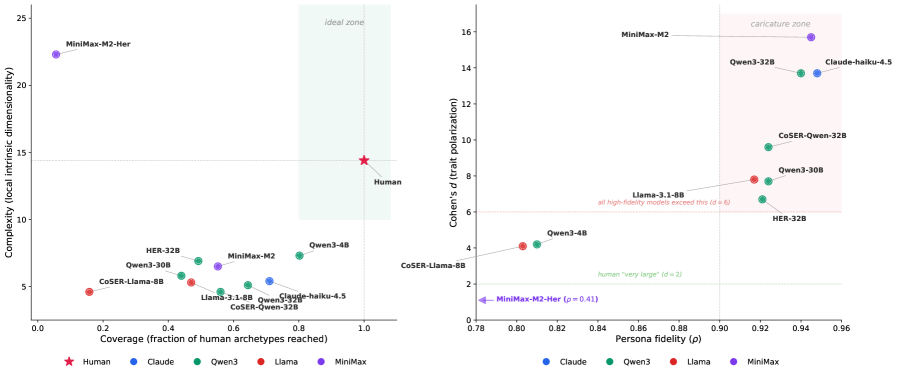
Figure 4 (the paper’s own summary plot) shows the two-axis result. Left panel: Coverage vs. LID — the human reference sits in the upper-right (Cov=1.0, LID=14.4) and no model occupies that region; Qwen3-4B is high-Cov/low-LID, CoSER-Llama-8B is low-Cov/low-LID, MiniMax-M2-Her is low-Cov/high-LID. Right panel: persona fidelity ρ vs. Cohen’s d — every model with ρ>0.9 also produces d>6, far beyond the d=2 “very large” threshold in human personality research. MiniMax-M2 sits at the extreme (ρ=0.95, d=15.7). This directly supports the Fidelity Trap claim: high per-persona rank fidelity is purchased by pushing High/Low personas to opposite caricatured extremes.
Training-pipeline traces (Table 1): Qwen3-32B → CoSER-Qwen-32B → HER-32B shows Cov 0.64→0.56→0.49 monotonically down, d̄ 13.7→9.6→6.7 (less caricature with more training), LID dips then recovers 5.1→4.6→6.9. MiniMax-M2 → MiniMax-M2-Her: RL explodes LID 6.5→22.3 and fixes Hop 0.64→0.50 but devastates Cov 0.55→0.06 and ρ 0.95→0.41. Attribute truncation (Table 2): Gender 89% > Country 86% > Political 60% > Age 33% > Social Class 25% — every model under-represents socioeconomic status. Stereotyping (Table 3): Claude-Haiku-4.5 concentrates 57% of moral-judgment demographic R² on gender, Qwen3-4B 59% on class; MiniMax-M2 is uniform (25%) but with the highest total R² (0.021). Thinking mode on Qwen3-32B leaves all metrics unchanged (Table 9) — collapse is in the weights.
Conclusion
The core practitioner takeaway: if you staff a simulation with LLM agents and evaluate per-agent fidelity, you will be systematically misled — the model best at following persona prompts (MiniMax-M2, ρ=0.95) is also the most caricatured (d=15.7) and the Qwen3 base→SFT→RL pipeline shows Coverage dropping monotonically (0.64→0.49) while instruction-following improves. Expect socioeconomic class and age to vanish from open-ended output regardless of prompt. Scope of these findings is narrow: 1,144 English personas, one human BFI-44 reference (Twin-2K-500), moral and self-introduction results lack a human baseline, all from single-turn probes. The title suggests a general diagnosis but only three instruments are tested; no multi-turn agentic simulation is evaluated. Base-model-only (pre-alignment) comparison is not run — authors flag this themselves.
Novelty Check
The paper’s own Related Work positions the delta clearly: prior persona evaluations (Wang et al., 2024 — InCharacter; Abdulhai et al., 2025; Huang et al., 2024a,b) score per-agent fidelity in isolation. Prior collapse studies (Baltaji et al., 2024 on conformity; Wang et al., 2026b on persona drift; Huang et al., 2026 on convergent morality) document convergence qualitatively but not geometrically. The geometric tools (Density & Coverage from Naeem et al., 2020; Hyperspherical Uniformity from Wang & Isola, 2020; LID from Tulchinskii et al., 2023) are imported from generative-model evaluation. The genuinely new step is applying them jointly to a Behavioral Trait Matrix for persona populations and identifying the fidelity↔caricature coupling and attribute-truncation hierarchy. This is a real contribution, not a relabel — no prior work I can confidently name combines these three axes on psychometric response matrices. Lu et al. (2026)’s “Assistant Axis” and Paglieri et al. (2026)’s persona generator are adjacent but operate on different substrates. Uncertain whether a concurrent workshop paper has scooped the specific “fidelity trap” framing.
Open Questions
- Does collapse persist in multi-turn agentic simulations (Sotopia, generative-agents) where personas interact, or do interactions re-diversify behavior?
- Is the fidelity/caricature coupling breakable by a training objective that rewards within-group variance (authors mention as future work)?
- How much of the attribute-truncation hierarchy (class, age discarded) is inherited from pretraining data vs. RLHF? Pre-alignment base-model runs are conspicuously absent.
- Do findings hold on non-English personas and non-Western moral scenarios?
- Would higher sampling temperature or best-of-k decoding recover Coverage, or only amplify noise as MiniMax-M2-Her suggests (I/E=0.75)?
Figures
Figure 1: (a) Coverage.
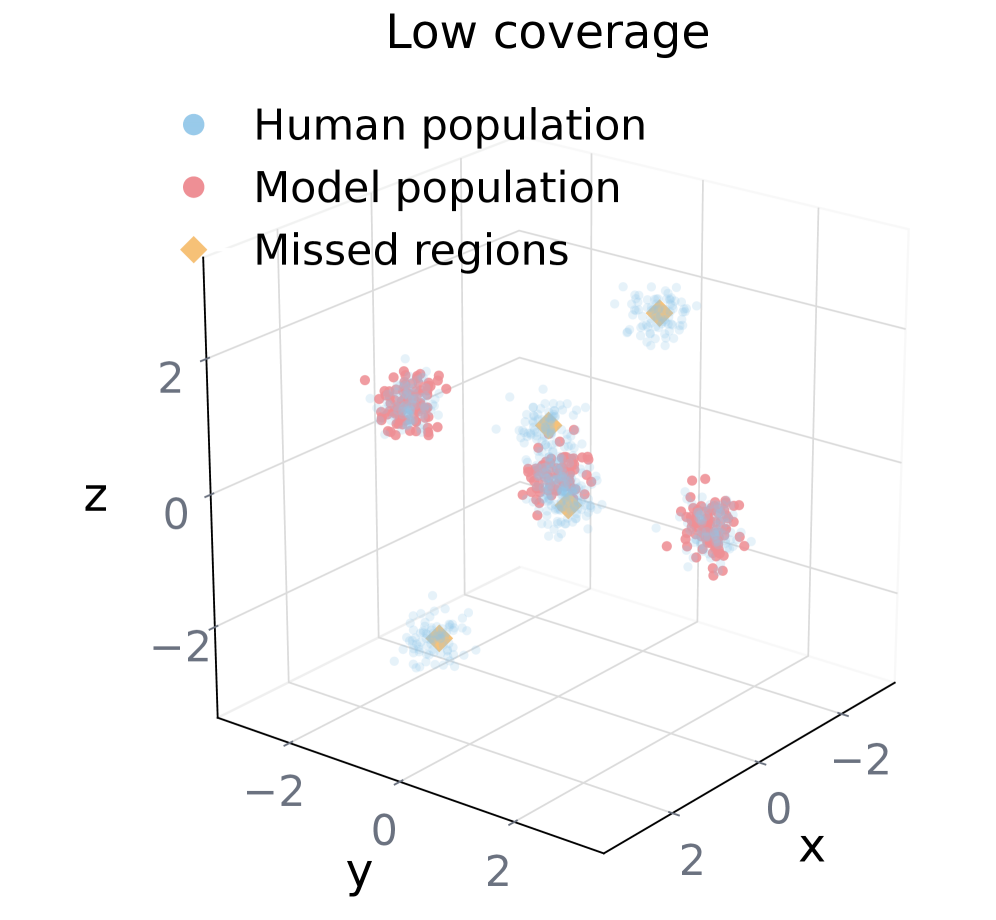
Figure 2: (b) Uniformity.
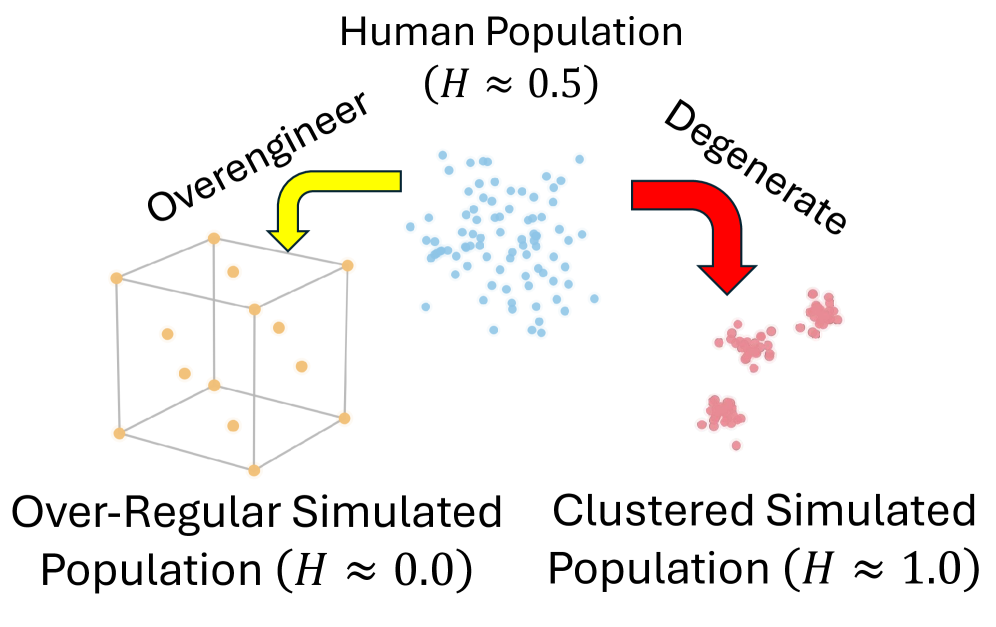
Figure 3: (c) Complexity.
Original abstract
Applications based on large language models (LLMs), such as multi-agent simulations, require population diversity among agents. We identify a pervasive failure mode we term \emph{Persona Collapse}: agents each assigned a distinct profile nonetheless converge into a narrow behavioral mode, producing a homogeneous simulated population. To quantify persona collapse, we propose a framework that measures how much of the persona space a population occupies (Coverage), how evenly agents spread across it (Uniformity), and how rich the resulting behavioral patterns are (Complexity). Evaluating ten LLMs on personality simulation (BFI-44), moral reasoning, and self-introduction, we observe persona collapse along two axes: (1) Dimensions: a model can appear diverse on one axis yet structurally degenerate on another, and (2) Domains: the same model may collapse the most in personality yet be the most diverse in moral reasoning. Furthermore, item-level diagnostics reveal that behavioral variation tracks coarse demographic stereotypes rather than the fine-grained individual differences specified in each persona. Counter-intuitively, \textbf{the models achieving the highest per-persona fidelity consistently produce the most stereotyped populations}. We release our toolkit and data to support population-level evaluation of LLMs.