arXiv: 2604.24003 · PDF
作者: Han Wang, Xiaodong Yu, Jialian Wu, Jiang Liu, Ximeng Sun, Mohit Bansal, Zicheng Liu
单位: UNC Chapel Hill, Advanced Micro Devices, Inc
主分类: cs.CL · 全部: cs.CL, cs.LG
命中关键词: large language model, llm, rag, reasoning, inference, post-train
TL;DR
在 4K 短上下文 GRPO 后训练中,用基于 token log-prob 的 step 级 confidence 对 rollout 内部做 advantage 零值遮罩,稳住训练并压缩推理长度。
Motivation
现有 efficient reasoning 方法(L1、LAPO、ThinkPrune 等)都把 length-aware reward 和短上下文后训练捆在一起——base 模型在 16K–24K 上下文训练,后训练却硬压到 4K,但没人单独量化"短上下文本身到底贡献了多少压缩"。作者做了一个 ablation:只跑纯 GRPO、不加任何 length reward,在 4K 上下文后训练 DeepScaleR-1.5B,结果 output length 被压到和 LAPO/ThinkPrune 同档甚至更短(Fig 2a),说明上下文窗口本身就是强压缩信号,过去被错误归因给了 length reward 设计。但代价是训练不稳:accuracy 波动、后期退化(Fig 2b),policy entropy 快速塌陷。作者量化了原因:把 base 模型 8K rollout 硬切到 4K 后用同一 verifier 重跑,约 29% 本来正确的 rollout 变成 verifier-failed——多数只是丢了最后的 boxed 答案或收尾推导。标准 GRPO 会把负 advantage 平摊给这些 rollout 里本来正确的中间步骤,造成 credit 误判。这块痛点直接影响所有在短上下文下做 RL-based efficient reasoning 的团队。
核心观点
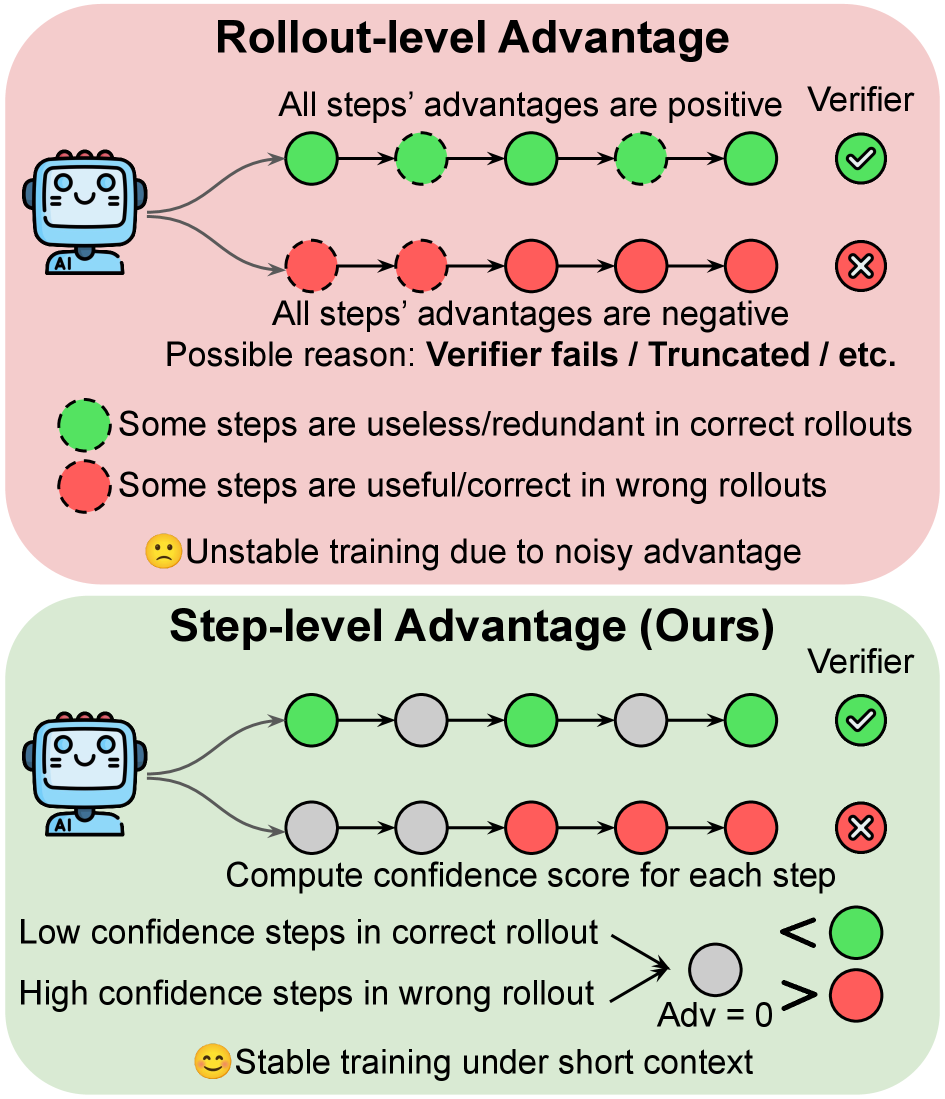
图 1 对比 rollout 级与 step 级 advantage 分配。传统 GRPO 按最终 verifier 结果把 reward 均匀传到所有 token:correct rollout 里所有 step 都拿正 advantage(包括冗余的自我怀疑 / 反复验证),verifier-failed rollout 里所有 step 都拿负 advantage(包括被截断但其实正确的中间推理)。SAS 的做法是把 correct rollout 里低 confidence step 和 failed rollout 里高 confidence step 的 advantage 置零,利用 GRPO 组内归一化的非对称效应——零值在正 advantage 之下(压住不可靠步)、在负 advantage 之上(保护可靠步)。
- 第一次系统隔离"短上下文后训练"本身的压缩效果,与 length reward 解耦。
- 指出短上下文压缩的真正代价:~29% 正确 rollout 被截断后变 verifier-failed,导致 credit 误判和 entropy 塌陷。
- 提出 SAS:reward-conditioned 的 step 级 advantage 置零机制,单一零值操作同时处理 correct / failed rollout。
- 用 policy 自己的 token log-prob 均值做 step confidence,省掉外部 PRM;与 Qwen2.5-Math-PRM-7B 排序的 nDCG@k 相关性 0.9022。
- 开销仅 +17% per-step wall-clock,不改架构 / 采样 / memory footprint。
方法
从 long-context base 模型(DeepScaleR-1.5B-Preview,base 用 8K→16K→24K 三阶段训)开始,在 4K context 下跑纯 GRPO,outcome-only reward(0/1),batch=128,lr=1e-6,每 prompt 采 8 个 rollout,共 500 step。SAS 的核心是在 GRPO 的 group-relative advantage 之上再做一层 step 级选择:先按 \n\n 把每条 rollout 切成离散 step(此分隔符来自 DeepSeek-R1 的 SFT / RL 训练数据约定,见附录 B),再对每个 step 用该 step 内 token log π_θ 的平均值算 confidence c_j(Eq.3)。对 correct rollout(reward=1),按 c_j 升序挑 ratio r 的最低 confidence step,把这些 step 所有 token 的 advantage 设为 0;对 verifier-failed rollout(reward=0),按 c_j 降序挑 ratio r 的最高 confidence step 同样置零。在 GRPO 的组内归一化下,0 天然落在正 advantage 下方(在 correct 组里),落在负 advantage 上方(在 failed 组里),所以一次零值操作就实现了"压不可靠步 + 护被截断步"的双向效果。不加任何 length-aware reward,不改架构、不加 PRM、不加 rollout。默认 r=0.3。
实验
Base 模型 DeepScaleR-1.5B-Preview,训练数据 DeepScaleR-Preview-Dataset(~40K 题,AIME/AMC/Omni-MATH/Still),训练框架 VeRL,硬件 8× AMD MI250 64GB。数学 benchmark:AIME24、AIME25、MATH、AMC、OlympiadBench;out-of-domain 通用推理:GPQA-Diamond、LSAT、MMLU。评测每题采 16 个样本(T=0.6、top-p=0.95、max 8K token),报 Pass@1、平均 output token 数、AES。用 AIME24 做 validation 选 checkpoint。Baselines:GRPO-4K、L1-Max、ThinkPrune-4k、LAPO-I,全部在 4K 上下文下从同一 base 后训练。
结果
数学 5 数据集平均(Table 1):SAS 把 Pass@1 从 base DeepScaleR 的 52.37 拉到 54.54(+2.17 点),平均 token 从 5118 降到 3407(–33%),AES=0.46;相较最强 length-aware baseline,SAS 比 LAPO-I(53.29 / 4127)和 ThinkPrune-4k(53.35 / 4004)准确率更高且 token 更少;相较 GRPO-4K(53.61 / 3775)同样是更准更短。对 L1-Max(48.04 / 1828)——压得最狠但精度掉到 48,SAS 在 AES 上领先。通用推理 3 数据集平均(Table 2):SAS 拿到 38.30 / 2729(AES 0.45),优于 GRPO-4K 的 36.55 / 2496(AES 0.32,过压缩掉精度)和 LAPO-I 的 37.77 / 3331。Abstract 里"比最强 length-aware baseline +0.86 Pass@1、–16.3% length"的说法与 Table 1 中相对 LAPO-I 的差距(54.54 vs 53.29=+1.25、3407 vs 4127≈–17.4%)大致匹配,但数字不完全等同,应是 Table 1/2 合并平均口径差异。
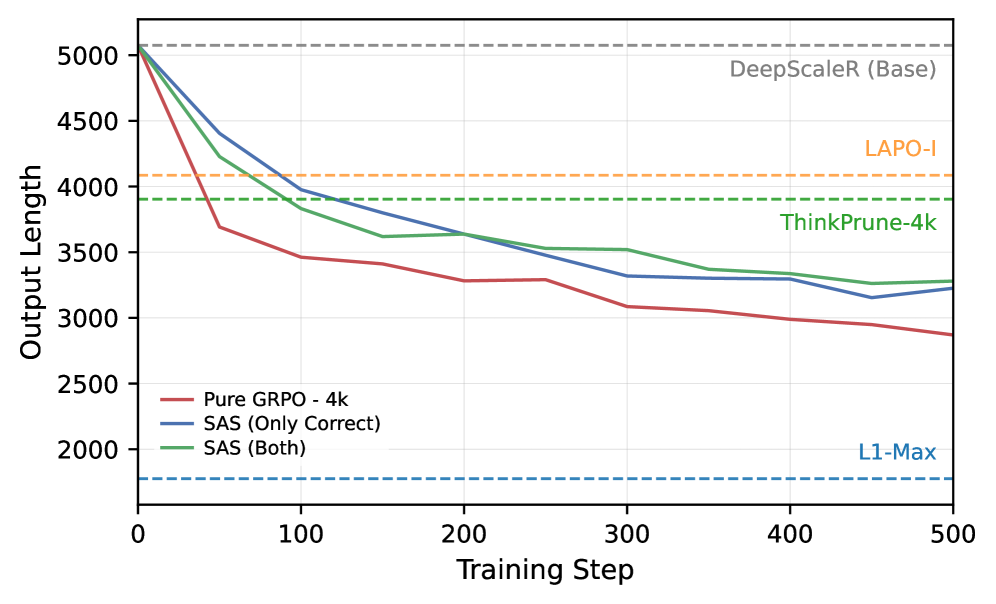 图 2(a) 显示 GRPO-4K / SAS 的 output length 在短上下文训练早期都急速下降并稳定在 LAPO、ThinkPrune 水平之下,支撑"短上下文本身就是强压缩信号"这个核心主张——论文未给出曲线每步具体数值。
图 2(a) 显示 GRPO-4K / SAS 的 output length 在短上下文训练早期都急速下降并稳定在 LAPO、ThinkPrune 水平之下,支撑"短上下文本身就是强压缩信号"这个核心主张——论文未给出曲线每步具体数值。
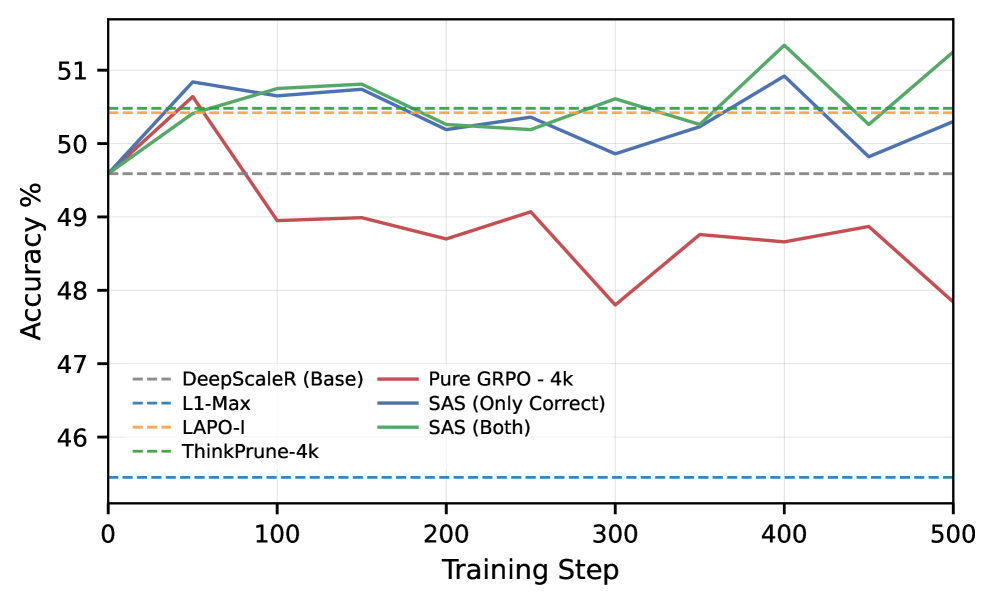 图 2(b) 对应的 accuracy 曲线暴露了 GRPO-4K 的训练不稳:长度持续下降时 accuracy 波动并在后期衰减,这正是作者提出 SAS 的直接动机,也对应 4K 截断后 ~29% 正确 rollout 被误判为 failed 的现象。
图 2(b) 对应的 accuracy 曲线暴露了 GRPO-4K 的训练不稳:长度持续下降时 accuracy 波动并在后期衰减,这正是作者提出 SAS 的直接动机,也对应 4K 截断后 ~29% 正确 rollout 被误判为 failed 的现象。
Ablation(Table 3):去掉 failed rollout 分支(“Only Correct”)AES 从 0.46 降到 0.43、Pass@1 54.54→53.90;Random Steps 降到 AES 0.38;Token-level 降到 0.39。Selection ratio(Table 4):r=0.3 最优(AES 0.46),r 在 0.1–0.9 间 AES 都 ≥0.36,对超参鲁棒。Step confidence 合理性:在 MATH500 上 16 样本 × 8000 response,用 Qwen2.5-Math-PRM-7B 打分做 nDCG@k 排序相关性=0.9022。计算开销:GRPO 每 step 279.08s,SAS 327.15s,+17%。
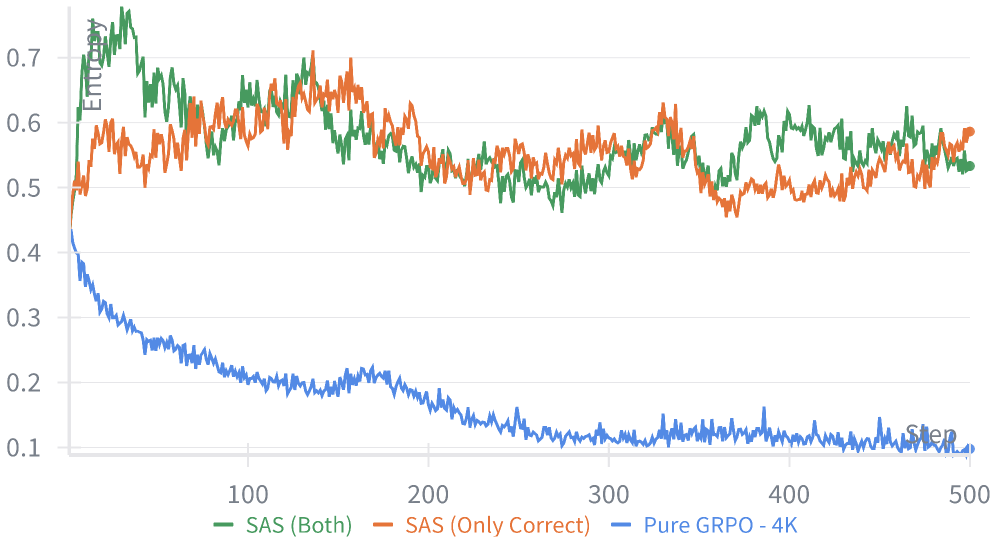 图 3 policy entropy 曲线显示 GRPO-4K 训练中 entropy 快速塌陷(探索坍缩、推理模式僵化),而 SAS(包括 Only Correct 变体)全程保持更高更稳的 entropy——这量化解释了为什么 SAS 能避免"短上下文 + rollout 级 credit"组合下的 brittle policy。
图 3 policy entropy 曲线显示 GRPO-4K 训练中 entropy 快速塌陷(探索坍缩、推理模式僵化),而 SAS(包括 Only Correct 变体)全程保持更高更稳的 entropy——这量化解释了为什么 SAS 能避免"短上下文 + rollout 级 credit"组合下的 brittle policy。
结论
Practitioner 读完该带走的 single takeaway:如果你在 4K 短上下文下做 RL-based efficient reasoning,真正的精度杀手不是 length reward 设计,而是短上下文截断引发的 ~29% false-negative rollout 向中间正确推理倒灌的负 credit;用 step 级 log-prob confidence 做一次 advantage 置零就够了(AES 0.46 vs 最强 length-aware baseline ≤0.33,Table 1)。边界:所有实验只在 DeepScaleR-1.5B-Preview(1.5B、Qwen 系)这一个 base、固定 4K 后训练 context 上验证,尚未跨模型规模 / 家族 / 后训练范式做扫描;\n\n 分步依赖 Qwen-R1 数据格式;没做不同训练 context(8K/16K)下的对比。
是否新瓶装旧酒
作者自述的最近邻:(1)Wang et al. 2025b(80/20 rule)——只更新高 entropy token,SAS 方向相反:过滤低 confidence step 而非放大高 entropy token,且粒度是 step 不是 token;(2)Prabhudesai et al. 2025——用 negative-entropy reward 替换 verifier reward,SAS 不改 reward,只用 confidence 做选择;(3)length-aware 方向 L1、LAPO、ThinkPrune——SAS 明确不加 length reward。我的独立判断:Ablation 里的 token-level 变体(AES 0.39)本质和 Wang 2025b 思路接近,SAS 相对它的 delta 主要来自"step 边界按 \n\n 切"+“对称处理 failed rollout"这两点;“对 failed rollout 里高 confidence step 做 shielding"这个具体 operational 设计在作者引用的先例里没见到直接对应,算本文的核心增量。
尚未回答的问题
- 跨规模验证:7B / 32B 或 non-Qwen 家族能否复现?作者明确承认只在 1.5B 一个 base 跑过。
- 训练 context 扫描:8K、16K 后训练时 truncation false-negative 比例会变低,SAS 的增益是否随之收缩、以及和 length-aware reward 的相对优势是否反转?
\n\n依赖:若模型家族不用\n\n分步(如 Llama-Instruct),step 切分策略本身会不会决定全部收益?- Ratio r 的鲁棒性在 out-of-domain 任务上未做扫描(只扫了数学)。
- 和 length-aware reward 叠加会不会进一步提升,或两者冲突?
原始摘要(中文翻译)
大语言模型(LLM)通过在推理时分配大量计算来取得强推理性能,常常生成冗长啰嗦的推理轨迹。近期 efficient reasoning 方向的工作通过基于长度的 reward 或剪枝来降低这一开销,但其中许多方法是在远短于 base 模型训练上下文窗口的条件下做后训练的,这一因素的作用此前未被系统性地隔离。我们首先表明:仅仅在短上下文下用标准 GRPO(不带任何 length-aware 目标)做后训练,就已经能够引发明显的推理压缩——但代价是训练动力学越发不稳定以及准确率退化。为此,我们提出 Step-level Advantage Selection (SAS),它在推理步骤的粒度上操作:对正确 rollout 中低 confidence 的 step、以及 verifier-failed rollout 中高 confidence 的 step 赋予零 advantage,因为后者的失败往往源自截断或 verifier 问题而非推理错误。在多样的数学与通用推理 benchmark 上,SAS 相对最强的 length-aware baseline 平均 Pass@1 提升 0.86 分,同时把平均推理长度降低 16.3%,得到更好的 accuracy–efficiency 权衡。