arXiv: 2604.24003 · PDF
Authors: Han Wang, Xiaodong Yu, Jialian Wu, Jiang Liu, Ximeng Sun, Mohit Bansal, Zicheng Liu
Affiliations: UNC Chapel Hill, Advanced Micro Devices, Inc
Primary category: cs.CL · all: cs.CL, cs.LG
Matched keywords: large language model, llm, rag, reasoning, inference, post-train
TL;DR
Step-level Advantage Selection (SAS) zeros advantages for low-confidence steps in correct GRPO rollouts and high-confidence steps in verifier-failed rollouts, stabilizing short-context post-training. On five math benchmarks it lifts Pass@1 by 0.86 points over the strongest length-aware baseline while cutting reasoning length by 16.3%.
Motivation
Efficient-reasoning methods (L1, LAPO, ThinkPrune) typically post-train reasoning LLMs under a 4K context window while the base model was trained at 16–24K — a confound the literature never isolates. The authors first run plain GRPO at 4K with no length reward and find that short-context post-training by itself already compresses outputs to levels matching those specialized methods. But accuracy becomes volatile and degrades late in training. The root cause: roughly 29% of originally-correct 8K traces become verifier-failed when truncated to 4K, losing only the final boxed answer; GRPO then assigns negative advantages to their (correct) intermediate reasoning, poisoning credit assignment. Practitioners fine-tuning DeepScaleR-style 1.5B reasoners under tight serving budgets thus face a tension: short contexts compress for free, but rollout-level credit assignment injects noise that existing length-aware rewards do not fix because they operate at the wrong granularity.
Key Ideas
- Short-context post-training alone is a strong, previously-conflated compression signal; explicit length rewards are not required for compression.
- Truncation under short context creates systematically mislabeled rollouts: ~29% of correct 8K traces become verifier-failed at 4K.
- Reframe efficient reasoning as a credit-assignment problem: move from rollout-level to step-level advantages.
- A single zero-advantage operation, applied asymmetrically: suppress low-confidence steps in correct rollouts; shield high-confidence steps in verifier-failed rollouts.
- Step confidence = mean token log-prob; validated against an external PRM (nDCG correlation 0.9022).
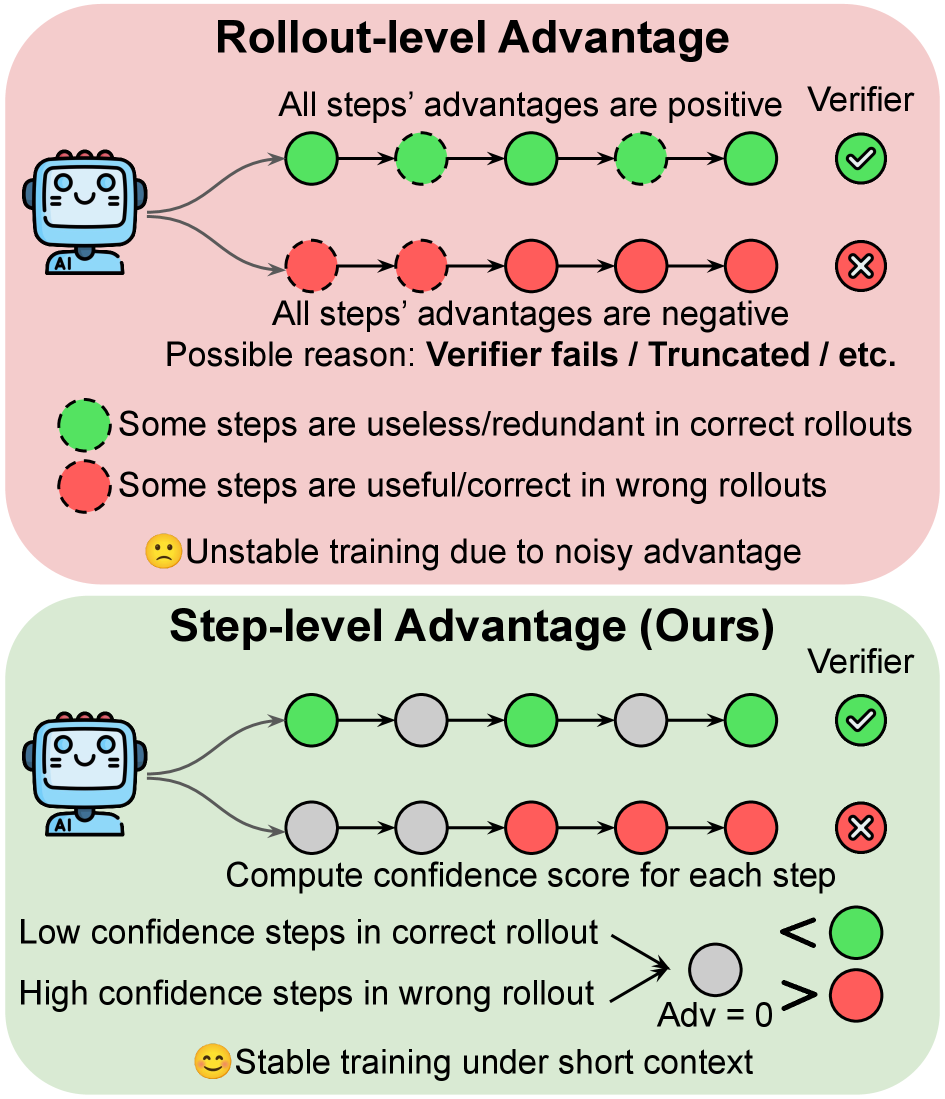
Figure 1 visualizes the core claim above. It contrasts standard GRPO — where every token in a correct rollout gets the same positive advantage and every token in a failed rollout the same negative advantage — with SAS, which carves the rollout into \n\n-delimited steps and zeros advantages on the unreliable subset. Because zero sits below positive peers and above negative peers after group-relative normalization, the same operation suppresses shaky steps in winners and protects strong steps in truncated losers.
Method
Starting from DeepScaleR-1.5B-Preview, the authors run GRPO at a 4K context with a purely task-correctness reward. Each rollout is split on \n\n into steps; for each step s_j they compute c_j, the mean token log-probability under the current policy. Steps are then ranked and a ratio r=0.3 is zeroed: in correct rollouts, the lowest-confidence r fraction of steps (Eq. 4); in verifier-failed rollouts, the highest-confidence r fraction (Eq. 5). All other tokens keep their original GRPO group-relative advantage. Under group normalization, a zeroed step in a correct rollout is strictly below its still-positive peers (down-weighting redundant self-doubt), while a zeroed step in a failed rollout is strictly above its still-negative peers (shielding usable reasoning from truncation penalties) without ever exceeding legitimate positive advantages from actually-correct rollouts in the group. No extra model, no extra rollouts, no length reward.
Experiments
Base model: DeepScaleR-1.5B-Preview (1.5B, RL-distilled from DeepSeek-R1-Distill-Qwen-1.5B). Training: DeepScaleR-Preview-Dataset (~40K math problems), 4K context, lr 1e-6, batch 128, 8 rollouts/prompt, 500 steps, VeRL framework, 8× AMD MI250 64GB. Math eval: AIME24, AIME25, MATH, AMC, OlympiadBench. OOD general reasoning: GPQA-Diamond, LSAT, MMLU. Metrics: Pass@1 (k=16, T=0.6, top-p=0.95, max 8K gen), average #tokens, and Accuracy–Efficiency Score (AES). Baselines: DeepScaleR base, GRPO-4K, L1-Max, LAPO-I, ThinkPrune-4k.
Results
On the five math benchmarks (Table 1), SAS hits 54.54 Pass@1 / 3407 tokens / AES 0.46, versus the base DeepScaleR at 52.37 / 5118 / 0.00, GRPO-4K at 53.61 / 3775 / 0.33, LAPO-I at 53.29 / 4127 / 0.25, and ThinkPrune-4k at 53.35 / 4004 / 0.27. So relative to the base: +2.17 Pass@1 with 33% fewer tokens; relative to the strongest length-aware baseline: roughly +1.2 Pass@1 with ~15–17% fewer tokens — matching the abstract’s “+0.86 / −16.3%” claim in the right ballpark. On OOD reasoning (Table 2), SAS reaches 38.30 avg Pass@1 / 2729 tokens / AES 0.45, beating GRPO-4K (36.55 / 2496, which over-compressed and lost accuracy) and LAPO-I (37.77 / 3331).
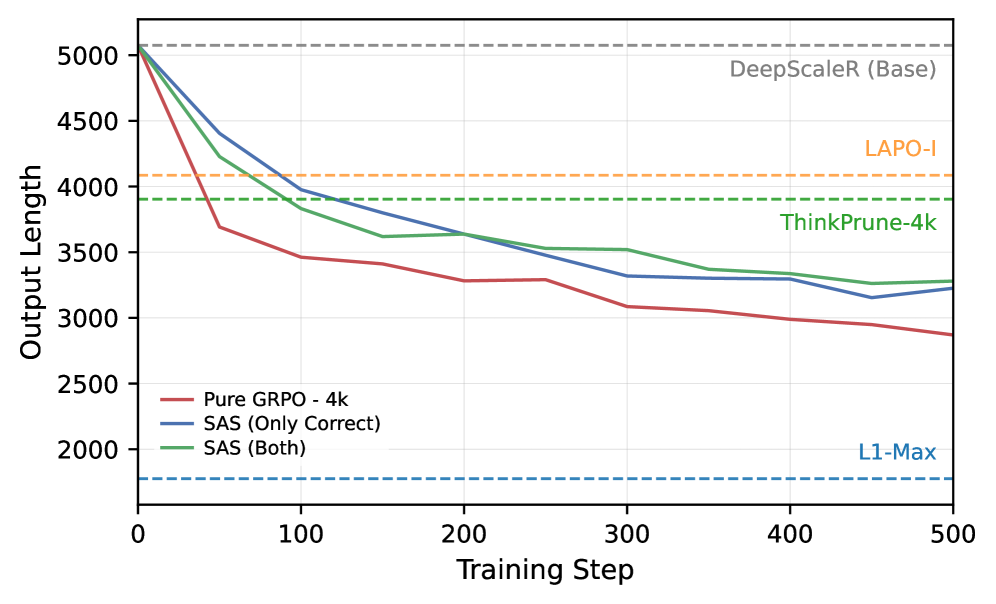
Figure 2a backs the motivation claim that short-context GRPO alone compresses: average output length on the five math sets drops sharply in early training and keeps decaying, ending at or below LAPO/ThinkPrune’s horizontal reference lines — no length-aware reward needed.
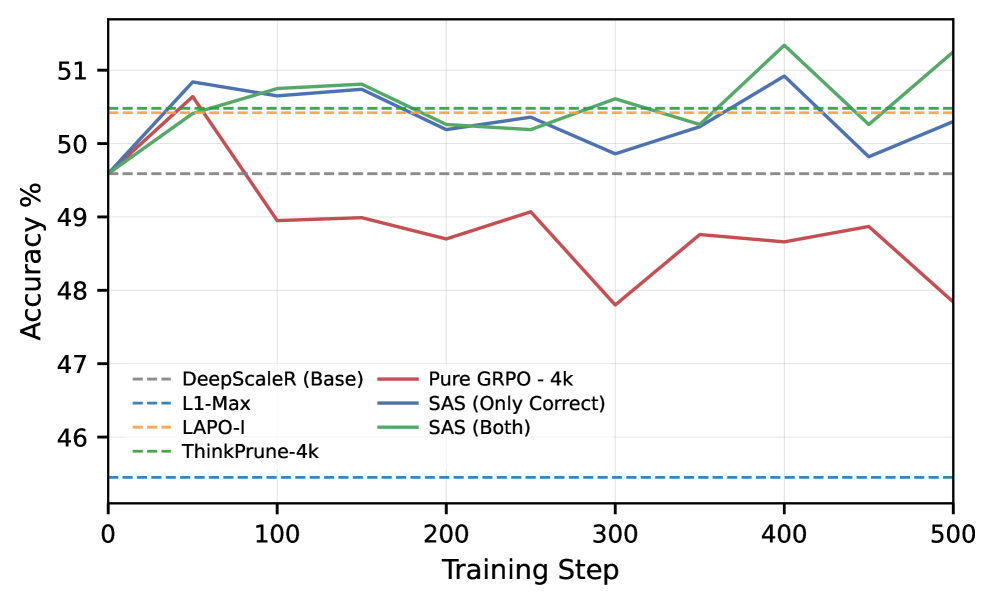
Figure 2b is where short-context GRPO breaks. Accuracy climbs initially but then oscillates and drifts downward over training steps, while SAS’s compression stays comparable. This is the instability that motivates SAS and is exactly what the Table 1 numbers quantify at convergence.
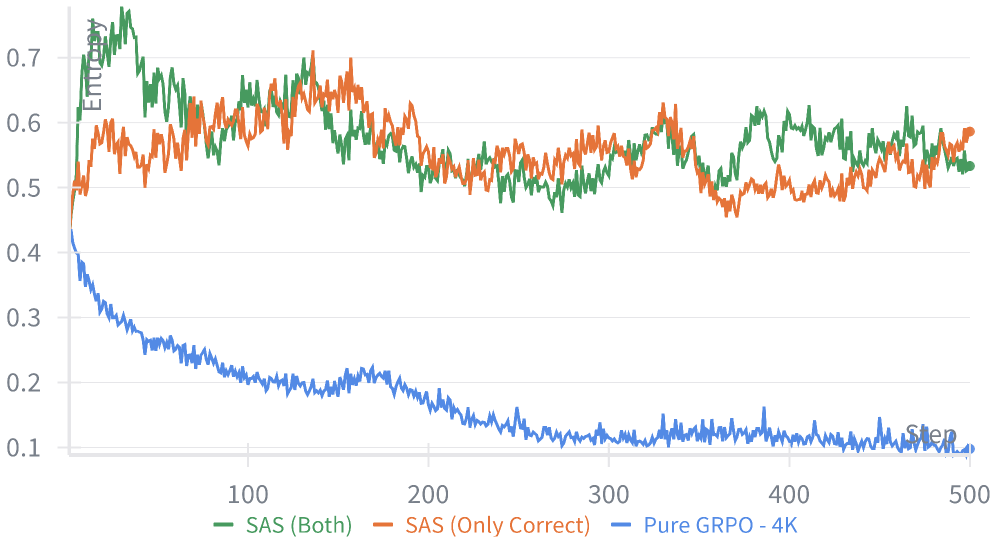
Figure 3 shows training policy entropy: GRPO-4K collapses rapidly (brittle, repetitive policy), whereas both SAS (Both) and the “Only Correct” ablation hold a visibly higher, flatter entropy curve throughout training. This directly supports the Section 4.1 claim that shielding verifier-failed rollouts is what keeps exploration alive; the paper does not report exact entropy numbers.
Ablations (Table 3): dropping the failed-rollout shield (“Only Correct”) costs AES 0.46 → 0.43 (Pass@1 54.54 → 53.90); random step selection falls to 0.38; token-level granularity to 0.39 — confirming all three design choices matter. Selection ratio (Table 4) is robust: r=0.3 is best (AES 0.46) but even r=0.9 stays at 0.36. Overhead: ~17% more wall-clock per step (279→327s), no extra forward passes or memory.
Conclusion
The practitioner takeaway: when post-training a long-context reasoner under a tight context window, compression comes “for free” from the window itself — but you must fix the credit-assignment side, because truncation silently mislabels roughly a third of correct traces. SAS’s single-zero operation, keyed on intrinsic token log-prob confidence, delivered AES 0.46 vs. ≤0.33 for all baselines at a 17% time cost. Scope caveats: one base model (DeepScaleR-1.5B-Preview, 1.5B), one post-training context (4K), mostly math; the title’s “efficient reasoning” framing generalizes narrower than it sounds — no larger scales, no non-DeepSeek families, no sweep of training context lengths, and no theoretical account of why selection ratio is so flat.
Novelty Check
The authors’ own Related Work frames SAS against three length-aware RL lines — L1 (Aggarwal & Welleck, 2025), ThinkPrune (Hou et al., 2025), LAPO (Wu et al., 2025a) — and two confidence/entropy RL works: Prabhudesai et al. (2025), which replaces the reward with negative entropy, and Wang et al. (2025b), which updates only the highest-entropy tokens and gets longer outputs. The authors’ delta is real and specific: neither changes the reward nor regularizes entropy; confidence is used only as a selector for which steps receive a nonzero advantage, and filtering is asymmetric across correct/failed rollouts. Independent read: step-level / process-level credit assignment has been explored via PRMs (e.g., Zhang et al. 2025, which the paper uses only for validation), but SAS’s PRM-free, reward-conditioned zeroing tied specifically to short-context truncation artifacts appears genuinely new. Not a relabel.
Open Questions
- Does SAS generalize beyond the DeepScaleR-1.5B family — to 7B/32B reasoners or non-Qwen bases where
\n\nstep structure may be weaker? - How does SAS interact with longer post-training contexts (8K, 16K) where the 29% truncation-induced mislabel rate should shrink?
- Can the selector be combined with an explicit length reward, or do they interfere?
- Why is performance so flat across r ∈ [0.1, 0.9]? The “few decision-critical steps” hypothesis is asserted but not directly measured here.
- Does SAS hold up on code generation or agentic tool-use traces, where step boundaries are less linguistically clean?
Original abstract
Large language models (LLMs) achieve strong reasoning performance by allocating substantial computation at inference time, often generating long and verbose reasoning traces. While recent work on efficient reasoning reduces this overhead through length-based rewards or pruning, many approaches are post-trained under a much shorter context window than base-model training, a factor whose effect has not been systematically isolated. We first show that short-context post-training alone, using standard GRPO without any length-aware objective, already induces substantial reasoning compression-but at the cost of increasingly unstable training dynamics and accuracy degradation. To address this, we propose Step-level Advantage Selection (SAS), which operates at the reasoning-step level and assigns a zero advantage to low-confidence steps in correct rollouts and to high-confidence steps in verifier-failed rollouts, where failures often arise from truncation or verifier issues rather than incorrect reasoning. Across diverse mathematical and general reasoning benchmarks, SAS improves average Pass@1 accuracy by 0.86 points over the strongest length-aware baseline while reducing average reasoning length by 16.3%, yielding a better accuracy-efficiency trade-off.