arXiv: 2604.24443 · PDF
作者: Sinin Zhang, Yunfei Xie, Yuxuan Cheng, Haoyu Zhang, Tong Zhang
单位: The Chinese University of Hong Kong, Shenzhen, Rice University, City University of Hong Kong, Fudan University
主分类: cs.AI · 全部: cs.AI
命中关键词: agent, agentic, multi-agent, reasoning, inference
TL;DR
PhysNote 让 VLM 通过自生成的 “Knowledge Notes” 外化并演化物理推理知识,结合时空规范化与 InfoAgent 迭代验证,在 PhysBench 测试集上达到 56.68% 准确率。
Motivation
VLM 在教科书式物理题上表现不错,但一旦面对多帧动态场景就常常失手:PhysBench 上 75 个 VLM 的大规模评测显示,多数模型在物理推理任务上只有约 40% 准确率,远低于人类,且这个缺口不会随模型尺寸、训练数据或输入帧数增加而缩小。作者把失败归到两条根因:(1) 时空身份漂移——物体在连续帧之间会"换身份",因果链被幻觉式转场切断,典型如碰撞后的轨迹无法被连贯表征;(2) 推理洞见的易失性——模型偶尔能蹦出正确的物理推理,但推理一结束就随上下文窗口蒸发,下次遇到同类问题还得从零开始,像"金鱼记忆的物理学家"。
今天受这个问题困扰的是 embodied agent / 机器人操作 / 自动导航这些需要精确物理推断的场景,当前的绕路做法是 PhysAgent 这类"reason-act-observe"框架外挂 SAM/Depth Anything 等工具,或 PCBs 通过微调小 VLM 产出辅助描述——要么推理链条用完即弃,要么靠昂贵的参数微调,都缺少自主演化知识的能力。作者认为可以把人类物理学家"记笔记、攒启发式、反思改错"的工作流外化成一个持续更新的结构化知识库,既不碰底模权重,也不依赖专用视觉工具。
核心观点
- 指出动态物理推理失败的两大根因:时空身份漂移与推理洞见的易失性。
- 提出 PhysNote:agentic 框架,让 VLM 自生成、检索、反思 “Knowledge Notes”。
- Spatio-Temporal Canonicalization:给视觉 entity 分配不可变 ID,加上 Triadic Observation Template
⟨ID, Anchor, State⟩,稳定跨帧对象身份。 - 三层 Knowledge Hierarchy:General Tips / Task Descriptions / Task Details,带自动剪枝机制防污染。
- InfoAgent:最多 3 轮 Hypothesis-Evidence-Validation 循环,evidence gap 未闭合时进入 Degenerative Inference Mode。
- 严格的 Update Eligibility 门 Φ(P):四条件合取,只有完全 grounded 的正确 trace 才能回写知识库。
方法
三阶段流水线。时空规范化先把 (Q, V) 变成 (Q̂, V̂):对图像/视频分别打上 [#0image]、[#1videoframe3] 之类不可变 ID,每条 observation 被强制写成 O = (v, e, d)(Visual ID、Visual Anchor、Description),保证任何观察都可追溯到具体帧和实体。
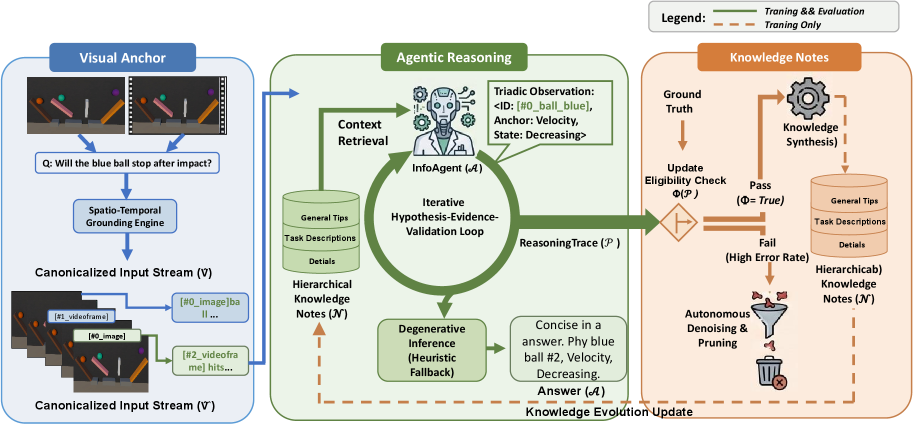
图 1 给出框架的三空间布局:左侧 Visual Anchors 负责 canonicalize 输入流;中间 InfoAgent 从分层 Knowledge Notes 𝒩 里按任务检索相关 Tips/Description/Details,执行 Hypothesis-Evidence-Validation 循环抽出 Triadic Observations;右侧(仅训练期)对推理 trace P 做 Update Eligibility Check Φ(P),合格的 trace 用于同步更新 Notes,错误率过高的任务节点被 Autonomous Denoising and Pruning 清除。这张图直接对应本文三大组件的信息流,支撑"知识可演化"这一核心主张。
知识层级分 General Tips / Task Descriptions / Task Details 三层,由 Context Selection Agent 在全局视野下匹配任务节点 T,缺匹配则触发 Note Discovery。节点错误率 E(T) = n₋/(n₊+n₋) > τ(正文 τ=0.7,最小激活 8 次)则整节点剪除。
InfoAgent 循环最多 3 轮:每轮生成假设 H_i + 候选答 A_cand + <info>/<attention> 查询,返回 micro-facts Facts_i,validator 判定是否足以支撑 A_cand;3 轮仍未闭合 gap 就进入 Degenerative Inference Mode 用启发式补齐。
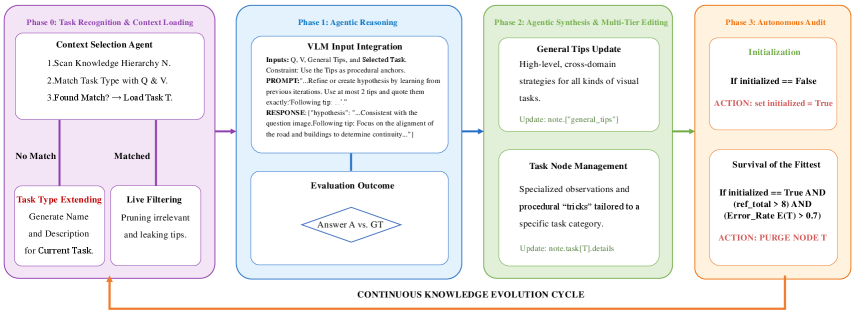
图 2 专门展开 Knowledge Note 的"使用 + 演化"两条路径:推理时根据 canonicalized 输入 (Q̂, V̂) 检索任务相关笔记喂给 InfoAgent 的 Hypothesis-Evidence-Validation 循环;训练时对 reasoning trace P 过 Eligibility Check,合格则合成新笔记、持续高错节点则剪枝。这张图直接支撑 “Notes 能跨批次自演化” 的主张。更新门 Φ(P) = c(P) ∧ ¬f(P) ∧ ¬a(P) ∧ d(P)——答案对、未退化、无启发式假设、micro-facts 含显式物理算子(trajectory/collision/contact)——四条件全真才允许写回。
实验
底模:Qwen2.5-VL-72B-Instruct。视频均匀采样 4 帧、分辨率 512 px。知识库用分层 JSON + all-MiniLM-L6-v2 embedding 检索。剪枝阈值 τ=0.7,最小激活 8 次;InfoAgent 上限 3 轮;Φ(P) 用 15 个物理原语关键词过滤。数据集:PhysBench,训练 500 条用于知识演化,测试集 10,000 条,验证集 200 条,覆盖四大域 S1 动力学 / S2 物体关系 / S3 场景理解 / S4 物体属性。Baseline:开源 VLM(LLaVA 系列、InternVL1.5、Mantis、PLLaVA、LLaVA-interleave-dpo)、闭源 VLM(GPT-4o、Gemini-1.5 pro/flash、Claude-3.5-sonnet)、Multi-agent 的 PhysAgent,全部 zero-shot。
结果
主表(Table 1):PhysNote 测试集总平均 56.68%,比最强 multi-agent baseline PhysAgent 的 51.72% 绝对提升 +4.96;四域全胜(S1 62.45 vs 58.20、S2 72.10 vs 65.40、S3 42.33 vs 38.10、S4 49.85 vs 45.20)。闭源里最强的 GPT-4o 平均只有 49.49%,Gemini-1.5-pro 49.11%。人类上界 95.87%,缺口仍显著。
消融(Table 2,验证集):Full Model 总分 72.86%,比 Qwen2.5-VL-72B 裸底模 69.85% 提升 +3.01;有意思的是 Baseline+InfoAgent 单独上反而降到 64.32%(作者解释为无结构引导时 agent “stochastic parrot”),Baseline+Note 单独为 66.83%,两者协同才达到 72.86%,验证 InfoAgent 与 Notes 必须一起用。

图 3 是相机运动推理的定性对比,支撑"canonicalization 防身份漂移"。问题要求判断相机是否做了垂直位移(GT=D)。Baseline 觉得相对位置稳定就错选 C(横向平行移动);PhysNote 通过 Triadic Observation 跟踪 peg 尖与酒杯口的持续对齐、物体相对尺寸不变,逐项排除 B(距离变远)和 C,再通过灰色钟形物体到画面边缘距离的减小识别出垂直位移,正确选 D。

图 4 展示 Knowledge Notes 如何引导细粒度属性辨别:任务是比较绿球与青球的可塑性(GT=A,绿球 much less)。Baseline 只看宏观运动觉得两球都没明显形变,判 C(差不多);PhysNote 从 Notes 里调出"影子清晰度+球形保持度"这条材料先验,量化出绿球形变比青球少约 15%,正确选 A。支撑"externalized tips 让模型看到平时忽略的信号"这一结论。
结论
实践者该带走的结论:把 VLM 物理推理的失败拆成"感知漂移"+“洞见易失"两件事,再用"笔记化 + agentic 循环"同时治,能在不动底模参数的前提下拿到 PhysBench 测试集 +4.96% 绝对提升(56.68% vs PhysAgent 51.72%),四域均衡受益。边界也很清楚:(1) 所有主表和消融都只在 Qwen2.5-VL-72B-Instruct + PhysBench 上跑,没有换底模验证可迁移性;(2) 知识演化只用了 500 条训练样本,长期演化下知识库是否仍保稳定、会不会污染,论文未给曲线;(3) 视频只用 4 帧均匀采样 + 3 轮 InfoAgent 上限,很多真实动态场景需要更高时序分辨率,未给帧数/迭代数的敏感性分析;(4) 标题说"evolvable"但论文没展示跨 batch 的知识库质量随时间变化曲线。
是否新瓶装旧酒
作者自陈的最近邻工作:PhysAgent(Chow et al., PhysBench)——reason-act-observe 循环 + SAM/Depth Anything 外部工具;Physics Context Builders, PCBs(Balazadeh et al., 2025)——微调小 VLM 产出场景描述。作者框出的 delta:前者推理 trace 用完即弃,后者需要参数微调,PhysNote 两样都不做,强调"持久化外化知识 + 自主剪枝演化 + 零工具零微调”。
独立看:用外部记忆 / 自生成笔记增强 LLM/agent 并非首创(Generative Agents 的记忆流、Reflexion 的 verbal RL、Voyager 的技能库都沿这条线),但把"时空规范化(不可变 ID + Triadic Template)+ 严格 Φ(P) 四条件更新门 + 错误率剪枝"这套组合装配在 VLM 物理推理上确实是一个较具体的新组合。不算换名,但"Knowledge Notes" 的核心思想可视为 LLM agent 长期记忆范式在视觉物理场景的迁移,真正的原创在时空锚定机制与更新门设计。
尚未回答的问题
- 500 训练样本下的知识库增长/剪枝曲线如何?多 batch 下 error rate 是否单调收敛?
- 更换底模(GPT-4o、Gemini-1.5-pro、InternVL 等)后框架是否仍有 +5% 量级收益?
- 采样帧数(4→16→32)和 InfoAgent 迭代上限(3→5→10)的敏感性?
- 非 PhysBench 的 embodied 任务(真机操作、CARLA、RoboTHOR)上是否 transfer?
- Φ(P) 四个条件各自对知识质量的贡献未做消融。
- 剪枝阈值 τ=0.7、最小激活 8 次是怎么选出来的,是否敏感?
原始摘要(中文翻译)
视觉语言模型(VLMs)在教科书式的物理题上已展现出不错的表现,但在面对需要跨帧时序一致性与因果推理的动态真实场景时,它们往往失败。我们识别出两个根本挑战:(1) 时空身份漂移——物体在连续帧间丢失其物理身份,从而打断因果链;(2) 推理时洞见的易失性——模型偶尔能给出正确的物理推理,但从未将其固化以便未来复用。为应对这两个挑战,我们提出 PhysNote,一个让 VLM 能通过自生成的 “Knowledge Notes” 外化并精炼物理知识的 agentic 框架。PhysNote 通过时空规范化稳定动态感知,将自生成洞见组织进一个分层知识库,并驱动一个迭代推理循环——先把假设锚定到视觉证据上,再把验证过的知识固化。PhysBench 上的实验表明 PhysNote 取得 56.68% 的整体准确率,比最强的 multi-agent baseline 高出 4.96%,并在全部四个物理推理子域上都有一致提升。