arXiv: 2604.24443 · PDF
Authors: Sinin Zhang, Yunfei Xie, Yuxuan Cheng, Haoyu Zhang, Tong Zhang
Affiliations: The Chinese University of Hong Kong, Shenzhen, Rice University, City University of Hong Kong, Fudan University
Primary category: cs.AI · all: cs.AI
Matched keywords: agent, agentic, multi-agent, reasoning, inference
Automated analysis unavailable (claude CLI timeout). Showing raw abstract.
Abstract
Vision-Language Models (VLMs) have demonstrated strong performance on textbook-style physics problems, yet they frequently fail when confronted with dynamic real-world scenarios that require temporal consistency and causal reasoning across frames. We identify two fundamental challenges underlying these failures: (1) spatio-temporal identity drift, where objects lose their physical identity across successive frames and break causal chains, and (2) volatility of inference-time insights, where a model may occasionally produce correct physical reasoning but never consolidates it for future reuse. To address these challenges, we propose PhysNote, an agentic framework that enables VLMs to externalize and refine physical knowledge through self-generated “Knowledge Notes.” PhysNote stabilizes dynamic perception through spatio-temporal canonicalization, organizes self-generated insights into a hierarchical knowledge repository, and drives an iterative reasoning loop that grounds hypotheses in visual evidence before consolidating verified knowledge. Experiments on PhysBench demonstrate that PhysNote achieves 56.68% overall accuracy, a 4.96% improvement over the best multi-agent baseline, with consistent gains across all four physical reasoning domains.
Figures
Figure 1: Figure 1: Overview of the PhysNote framework, which operates across three interconnected spaces to enable evolvable physical reasoning. Visual Anchors (left): Given a question Q Q and visual inputs V V (images or video), a Spatio-Temporal Grounding Engine assigns each visual entity an immutable identifier (e.g., [#0_ball_blue] ) to produce a canonicalized input stream V ^ \hat{V} , establishing ob
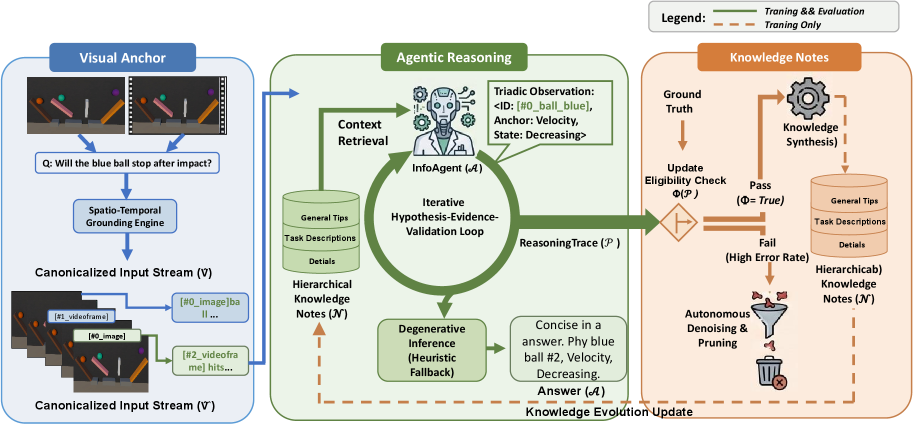
Figure 2: Figure 2: The Knowledge Note pipeline: usage and evolution. During inference, the system retrieves task-relevant notes from the Hierarchical Knowledge Notes 𝒩 \mathcal{N} based on the canonicalized inputs ( Q ^ , V ^ ) (\hat{Q},\hat{V}) , and feeds them into the InfoAgent’s iterative Hypothesis-Evidence-Validation loop to produce a grounded answer. During training, the resulting reasoning trace 𝒫
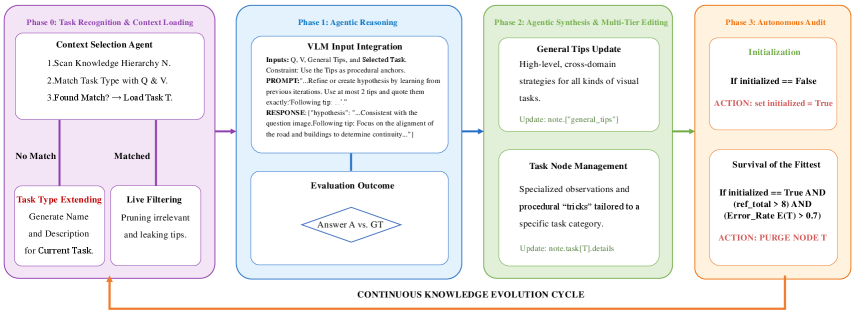
Figure 3: Figure 3: Qualitative comparison on camera motion reasoning. Given a video sequence and a multiple-choice question about camera adjustments, the baseline (left) fails to detect the vertical shift and relies on perceived stability to select a lateral motion (C). Our method (right) iteratively verifies geometric constraints, including object alignment and relative scale, across successive frames. By

Figure 4: Figure 4: Qualitative comparison on physical property reasoning. The baseline (left) observes no obvious deformation in either ball and concludes that their plasticity is equal (C). Our method (right), guided by retrieved Knowledge Notes on material cues, leverages shadow sharpness and post-interaction shape retention as observable proxies for plasticity. By quantifying the difference in deformati

Original abstract
Vision-Language Models (VLMs) have demonstrated strong performance on textbook-style physics problems, yet they frequently fail when confronted with dynamic real-world scenarios that require temporal consistency and causal reasoning across frames. We identify two fundamental challenges underlying these failures: (1) spatio-temporal identity drift, where objects lose their physical identity across successive frames and break causal chains, and (2) volatility of inference-time insights, where a model may occasionally produce correct physical reasoning but never consolidates it for future reuse. To address these challenges, we propose PhysNote, an agentic framework that enables VLMs to externalize and refine physical knowledge through self-generated “Knowledge Notes.” PhysNote stabilizes dynamic perception through spatio-temporal canonicalization, organizes self-generated insights into a hierarchical knowledge repository, and drives an iterative reasoning loop that grounds hypotheses in visual evidence before consolidating verified knowledge. Experiments on PhysBench demonstrate that PhysNote achieves 56.68% overall accuracy, a 4.96% improvement over the best multi-agent baseline, with consistent gains across all four physical reasoning domains.