arXiv: 2604.24062 · PDF
作者: Liangru Xiang, Yuxi Ma, Zhihao Cao, Yixin Zhu, Song-Chun Zhu
单位: Tsinghua University, Peking University, State Key Laboratory of General Artificial Intelligence, Beijing Key Laboratory of Behavior and Mental Health
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, llm, agent, rag, reasoning
TL;DR
用 OpenLock 范式对比人类与 GPT-5.2/Claude-4.5/Gemini-3-Flash/DeepSeek-V3.2,发现模型在单环境内可匹敌或超越人类,但跨环境的因果结构迁移必须先"环境接地"才生效,呈现延迟迁移。
Motivation
人类能从一次交互中抽取抽象因果结构(Common Cause / Common Effect)并立即迁移到新环境;经典 RL agent 则在 OpenLock 上灾难性失败(Edmonds et al. 2018 [4])。LLM/VLM 虽在静态推理 benchmark 上强势,但其"在交互中主动归纳潜在因果图、再跨上下文迁移"的能力从未被系统刻画过。作者关心的痛点是:现在业界讨论 agent reasoning / VLM 推理时,默认大模型已经具备类人的结构抽象,但没人验证过这在需要主动试错、顺序发现的场景下是否成立。对于要把 LLM/VLM 当作 agent runtime(规划、工具调用、新场景泛化)的团队,如果模型实际只会"先落地再泛化"而非"先泛化再行动",产品层的稳定性假设就会被打破。作者认为现在值得做是因为近一代多模态模型(GPT-5.2、Claude-4.5、Gemini-3、DeepSeek-V3.2)已足够强到在 text-only 条件下打过人类基线,因此能清晰区分"解不出来"与"解得出但抽象方式不同"。
核心观点
- 所有四个模型在跨环境因果结构迁移上都延迟或缺失,而人类从第一次尝试就用上先验结构。
- text-only 下模型的发现效率可与人类持平或更优;加入视觉输入整体让性能下降,暴露模型依赖符号而非真正多模态整合。
- 模型存在显著 CC/CE 非对称(GPT/Gemini 偏 CC,Claude 偏 CE),人类则无,说明是训练语料里的启发式偏置而非方向中性的因果抽象。
- 提出 “grounding-dependent transfer”:模型必须先在新环境里做一次自己的解,才能激活先验结构知识。
- 人类 + Claude 表现出"顿悟式"非线性加速,GPT/Gemini 只有渐进优化,暗示机制层的差异。
方法
沿用 OpenLock 范式(七杆一门,3 动作序列,30 次尝试预算,需找齐 3 个解)。两种潜在因果拓扑:CC(L1 → {L2,L3,L4} → Door,发散一对多)与 CE({L1,L2,L3} → L4 → Door,汇聚多对一)。实验 1 是单环境因果发现,三种输入条件:Text-only(T,纯符号)、Image-only(I,纯视觉反馈)、Text-and-Image(TI,两者兼有)。实验 2 在 prompt 里显式给出另一同结构环境已完成的三条解(动作序列文本描述),考察跨环境迁移;杆位和颜色会变,结构不变,所以收益只能来自结构抽象。每模型每结构 30 个 agent,DeepSeek 仅跑 T。人类数据来自 Edmonds et al. 2018(N=80)。
实验
被测模型:GPT-5.2、Claude-4.5-Sonnet、Gemini-3-Flash、DeepSeek-V3.2。基线:Edmonds et al. 2018 报告的人类行为数据(N=80,同样 30 次尝试预算)。指标:成功率(30 次内找齐 3 解的比例)、平均尝试次数、每条解的边际发现成本(marginal discovery cost)、以及迁移改善率 (Attempts_base − Attempts_trans)/Attempts_base。每个条件 30 agent,总 240 trial 用于实验 2。
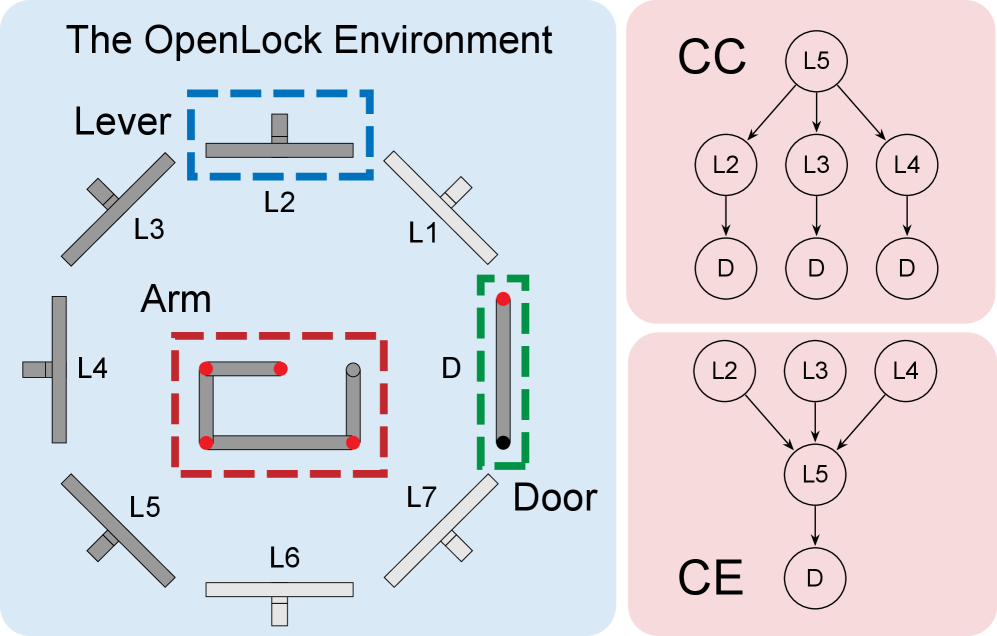
图 1 展示了 OpenLock 环境和两种潜在因果图,是整篇实验设计的基石:左边是七杆一门的视觉布局,杆的位置、颜色、标签在不同环境间会随机变,但右边 CC(L5 发散出多条路径)和 CE(多条路径汇聚到 L5)两种拓扑保持不变。作者正是靠这种"表面变、结构不变"的分离,来定义什么叫真正的结构迁移——只有抽掉感知细节才能拿到收益。
结果
实验 1(T 条件,Tab. 1):人类成功率 65.0% / 平均 20.66 次尝试(SD=9.09)。Gemini-3-Flash 100% 成功,9.08 次(t(138)=9.54, p<.001),显著快于人类;GPT-5.2 平均 15.77(t(138)=3.33, p=.001),Claude-4.5 15.74(t(139)=3.12, p=.002),都优于人类;DeepSeek-V3.2 19.35 次,与人类无显著差(p=.346)。CC/CE 非对称:GPT-5.2 在 CC 100% / 11.8 次 vs CE 66.7% / 19.7 次(t(58)=−4.38, p<.001);Claude 反向,CE 86.7% 高于 CC 67.7%。模态消融:GPT-5.2 TI 24.10 vs T 15.77(t(118)=−6.11, p<.001),I 进一步劣化到 27.55;Claude 的 I 条件也从 TI 14.05 退到 21.37(t(120)=−4.70, p<.001);Gemini 三条件都 100% 成功但 TI 比 T 略慢(10.41 vs 9.08, p=.020)。
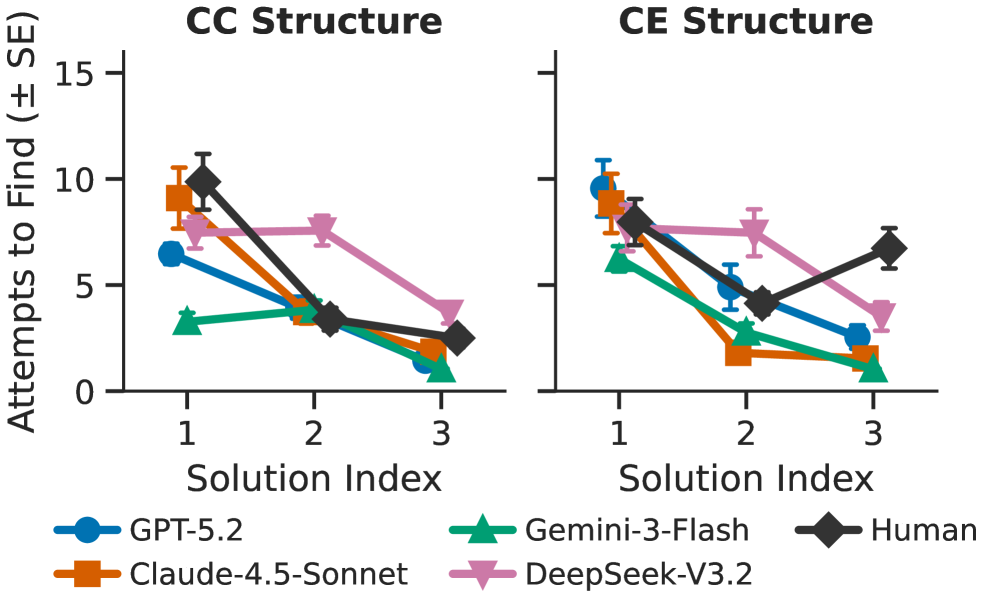
图 2 支撑"顿悟 vs 渐进优化"的论点:横轴是第 1/2/3 条解,纵轴是找这条解所需的尝试次数(边际发现成本)。人类从第 1 解的 M=7.37 骤降到第 2 解的 M=3.65(t(51)=4.31, p<.001),Claude 几乎复刻这一曲线(7.19→2.62, t(46)=4.80, p<.001),都呈非线性加速;GPT-5.2、Gemini-3-Flash、DeepSeek 则只有平缓下降(如 Gemini 4.75→3.30, p=.026),说明它们更像是在迭代收窄概率分布而非发生表征重构。
实验 2(Tab. 2):人类平均尝试从 20.66 降到 13.85(+33.0%,t(158)=4.51, p<.001, d=0.71)。模型中只有 Gemini-3-Flash 取得统计显著迁移:9.08 → 7.33(+19.3%,t(118)=2.99, p=.003, d=0.55)。Claude(+17.9%,p=.090)和 DeepSeek(+10.5%,p=.089)方向正确但不显著;GPT-5.2 反而恶化 −10.5%(15.77 → 17.43),与标题"能迁移"形成反差。
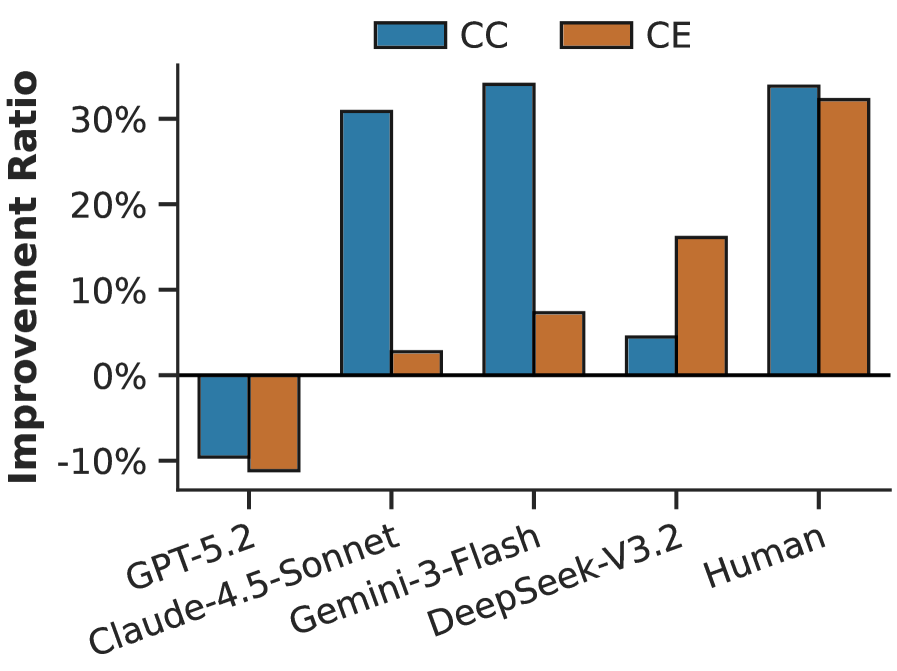
图 3 把 Tab. 2 的改善比画成 CC / CE 两条柱,让迁移效应的方向一目了然:人类在两种结构上都稳定正迁移,Gemini/Claude/DeepSeek 的柱子是正值但高度明显低于人类,而 GPT-5.2 的柱子是负值。这直接支撑"即便整体平均有正迁移,模型也离人类量级有距离,而 GPT 甚至被先验示例拖累"的结论。

图 4 是"延迟迁移"最关键的证据:同样画第 1/2/3 条解的成本,灰色为 baseline、红色为 transfer。人类第 1 解就显著下降(8.97 → 4.99, t(145)=3.82, p<.001, d=0.63);四个模型在第 1 解上没有任何显著差异,Gemini 的巨大收益集中在第 2 解(3.30 → 1.13, t(118)=6.88, p<.001, d=1.26),DeepSeek 也一样(7.52 → 5.57, p=.016)。这说明模型要先在新环境里自己蒙出第一解、完成"环境接地",先验的结构知识才开始起作用。
结论
对要把 LLM/VLM 当作 agent runtime 的实践者,最该带走的一句是:即使告诉模型另一个同结构环境的完整解法,当前前沿模型也无法用它指导新环境的首次探索——唯一有统计显著迁移的是 Gemini-3-Flash(+19.3%),而且收益集中在第二解而非第一解(图 4)。边界要诚实:所有结论都建立在 OpenLock 单一任务、4 个商用闭源模型、3-动作序列的小规模决策空间上;标题说"AI",实测只是当下几家主流模型当前版本。abstract 说"multimodal 整体降性能"也只在 GPT 和 Claude 上明显成立,Gemini 在 I 条件仍保持 100% 成功;关于"缺少顿悟式重构"的论断没有控制 prompt 工程 / CoT 深度 / 采样温度的 ablation。
是否新瓶装旧酒
作者自述 delta 明确:OpenLock 最早由 Edmonds et al. 2018 [4] 提出,用来对比人类和 RL;本文把被测对象换成当代 LLM/VLM,并加了 modality 维度和结构迁移实验,把"抽象迁移缺陷"从 RL 一般化到大模型。作者也引了 Edmonds 2019/2020 [5,6]、Gentner 1983 结构映射 [8]、Gick & Holyoak 1983 问题图式 [9] 作为认知科学侧参照。独立判断:把 OpenLock 换成新模型不算新方法,但"grounding-dependent transfer"这一概念框架 + CC/CE 非对称发现 + 模态干扰结果,是此前在大模型评测文献中未明确提过的组合,不算换皮。作者将 delayed transfer 部分效应归因于 in-context learning [20] 的可能性,也是诚实的边界声明。
尚未回答的问题
- 没做 prompt 工程 / chain-of-thought / 多轮反思的 ablation,无法区分"架构缺陷"和"交互协议缺陷"。
- 只有 4 个闭源模型、单一任务,缺少开源模型(Llama、Qwen、Mistral)和多任务对照。
- DeepSeek-V3.2 只跑了 T 条件,无法评估其 multimodal 干扰模式。
- Claude 类人的非线性加速究竟来自架构、RLHF 目标还是训练语料差异,没有 controlled 实验。
- 是否存在规模/训练数据量的 scaling law 能消除 delayed transfer,论文没有给不同尺寸模型对比。
- 若给模型多个同结构先验样例(few-shot 而非 one-shot),迁移是否会由"延迟"变"即时"?
原始摘要(中文翻译)
提取抽象因果结构并将其应用于新情境是人类智能的标志。尽管大语言模型(LLMs)和视觉语言模型(VLMs)在广泛的推理任务上表现强劲,它们在交互式因果学习——通过顺序探索归纳潜在结构并跨上下文迁移——方面的能力仍未被刻画。人类学习者在极少暴露后就能完成这种迁移,而经典的强化学习(RL)智能体则彻底失败。当前最先进的人工智能(AI)模型是否拥有类人的抽象因果结构迁移机制,仍是一个开放问题。我们使用 OpenLock 范式,要求顺序发现 Common Cause(CC)与 Common Effect(CE)结构,结果显示:模型表现出根本性的延迟或缺失迁移——即便是表现成功的模型,也需要先进行环境特定的映射——我们称之为 environmental grounding——之后效率增益才会出现;而人类则从第一次解题尝试起就能利用先验结构知识。在仅文本条件下,模型的发现效率与人类持平甚至更优。相反,视觉信息——无论是仅图像还是文本加图像条件——整体上反而削弱了性能,揭示了对符号处理的广泛依赖,而非整合式的多模态推理。模型还表现出人类所没有的系统性 CC/CE 非对称,这暗示了启发式偏置,而非方向中性的因果抽象。这些发现表明,大规模统计学习并不会产生支撑人类类比推理的去情境化因果图式,从而确立 grounding 依赖型迁移是当前 LLM 与 VLM 的一项根本局限。