arXiv: 2604.24062 · PDF
Authors: Liangru Xiang, Yuxi Ma, Zhihao Cao, Yixin Zhu, Song-Chun Zhu
Affiliations: Tsinghua University, Peking University, State Key Laboratory of General Artificial Intelligence, Beijing Key Laboratory of Behavior and Mental Health
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, agent, rag, reasoning
TL;DR
Using the OpenLock paradigm, the authors show that four frontier models (GPT-5.2, Claude-4.5-Sonnet, Gemini-3-Flash, DeepSeek-V3.2) can discover causal structures as efficiently as humans in text, but—unlike humans—fail to transfer Common Cause / Common Effect schemas to new environments until after an initial grounding solution, and are hurt rather than helped by visual input.
Motivation
Humans recognise abstract causal structures (e.g. “many causes → one effect” smartphone unlock, “one cause → many effects” power strip) and reuse them in perceptually novel contexts after a single episode. Classical RL agents fail catastrophically on the same transfer task despite orders of magnitude more data ([4] Edmonds et al. 2018). Modern LLMs / VLMs are trained on corpora dense with causal and relational knowledge and ace static reasoning benchmarks, yet their capacity for interactive causal learning — inducing a latent structure through sequential actions and then reusing it — is untested. Static QA or counterfactual benchmarks cannot distinguish genuine structural abstraction from context-bound pattern matching, because they never require the model to enter a new environment and act. That gap matters for anyone deploying agents in sequential, partially-observed settings (robotics, tool-using agents, scientific discovery): if the “schema” a model appears to know only activates after re-solving the problem once, cross-environment deployment is far weaker than benchmark scores suggest. The authors adapt OpenLock to probe exactly this, comparing four frontier models against N=80 humans from prior work on Common Cause (CC) and Common Effect (CE) graphs.
Key Ideas
- Port the OpenLock interactive causal-transfer paradigm from RL to frontier LLMs/VLMs; compare against human data from Edmonds et al. 2018.
- Dissociate local causal discovery (Experiment 1) from cross-environment transfer (Experiment 2).
- Evaluate three input modalities: text-only (T), image-only (I), text-and-image (TI).
- Introduce the notion of environmental grounding: models need post-hoc situational mapping before latent structural knowledge becomes operative — transfer is retrospective, not prospective.
- Document systematic CC/CE asymmetries (GPT/Gemini favour CC; Claude favours CE) absent in humans, indicating heuristic bias rather than direction-neutral schemas.
Method
OpenLock presents seven levers plus a door; each attempt is exactly two lever manipulations followed by a door push, with a 30-attempt budget to find three distinct solutions. CC instantiates L1 → {L2,L3,L4} → Door; CE instantiates {L1,L2,L3} → L4 → Door, with four decoy levers. Across environments, lever positions, colours, and labels change while the CC/CE topology is preserved, so only abstract structure transfers.
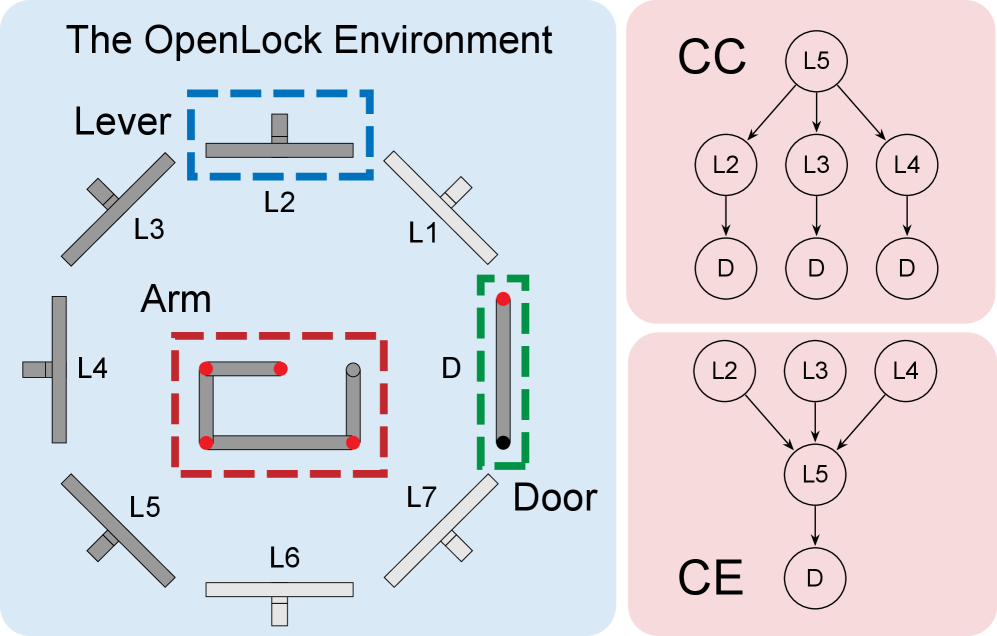
Figure 1 grounds the Method by showing the seven-lever panel that each agent interacts with and the two latent graphs the agent must infer — a one-to-many divergent CC graph gated by L5 versus a many-to-one convergent CE graph funnelling through L5. It makes the “surface vs. structure” dissociation concrete: swap colours, labels, and lever positions, and the underlying graph the authors test transfer over is unchanged.
Per model, 30 independent agents were run per structure per condition. Prompts in T convey levers, states, and feedback textually; I provides only images of state and dynamic visual feedback; TI combines both. Experiment 2 augments the prompt with three worked solutions from a prior environment sharing the same CC/CE structure but different surface features.
Experiments
Four models: GPT-5.2, Claude-4.5-Sonnet, Gemini-3-Flash, DeepSeek-V3.2 (text-only, no vision). Humans: N=80 from Edmonds et al. 2018. Conditions: CC × CE crossed with T / I / TI. Metrics: success rate (%) in 30 attempts, mean attempts, and marginal discovery cost per successive solution. Experiment 2 reports attempt-count improvement ratio (baseline − transfer)/baseline.
Results
Discovery (Table 1, T condition). Humans: 65.0% success, 20.66 attempts. Gemini-3-Flash: 100% on CC and CE, 9.08 attempts (t(138)=9.54, p<.001 vs. humans). GPT-5.2: 100% CC / 66.7% CE, mean 15.77 (p=.001). Claude-4.5-Sonnet: 67.7% CC / 86.7% CE, mean 15.74 (p=.002). DeepSeek-V3.2: 96.7% CC / 86.2% CE, 19.35 attempts (n.s. vs. humans).
CC/CE asymmetry. GPT CC 11.8 vs. CE 19.7 attempts (t(58)=−4.38, p<.001); Gemini CC 8.13 vs. CE 10.03 (p=.0067); Claude shows the opposite CE bias in success rate. Humans show no such asymmetry (t(78)=−1.27, p=.207).
Modality. Adding images hurts GPT (T 15.77 → TI 24.10, p<.001) and Gemini (9.08 → 10.41, p=.020); Claude is indifferent (15.74 vs. 14.05). Image-only is worst: GPT 27.55, Claude 21.37.
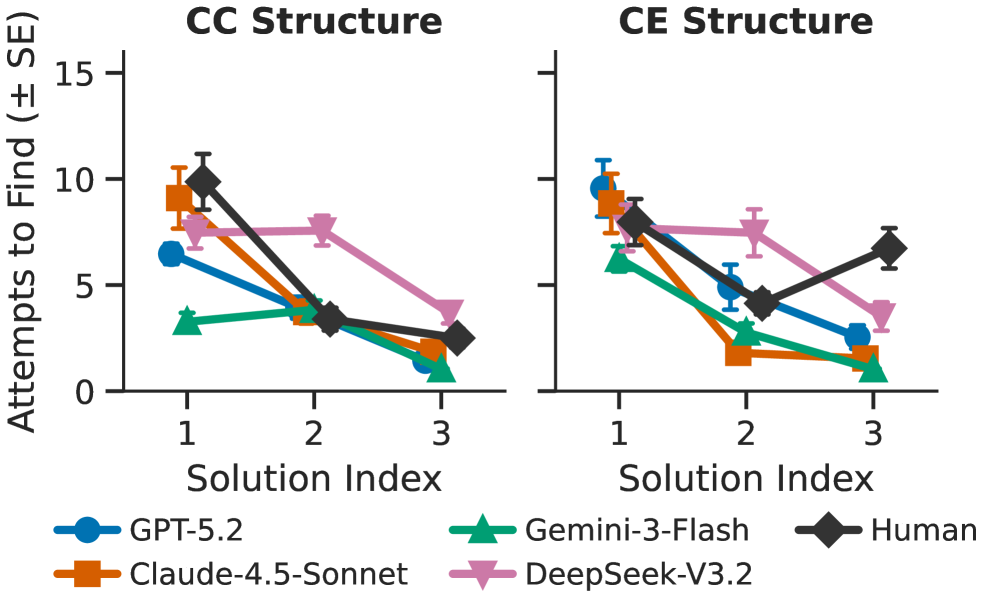
Figure 2 supports the “insight vs. gradual optimisation” finding in Sequential Discovery Patterns. The y-axis is attempts needed to find the next solution within a single environment, plotted per successive solution for CC (left) and CE (right). Humans drop from 7.37 to 3.65 attempts between the 1st and 2nd solution (t(51)=4.31, p<.001); Claude mirrors this (7.19 → 2.62, p<.001); Gemini barely bends (4.75 → 3.30, p=.026); GPT and DeepSeek are similarly flat. Non-linear acceleration = insight; flat curves = statistical refinement.
Transfer (Table 2). Humans: 20.66 → 13.85 attempts, +33.0% (p<.001, d=0.71). Only Gemini is reliably better (9.08 → 7.33, +19.3%, p=.003, d=0.55). Claude +17.9% (p=.090) and DeepSeek +10.5% (p=.089) are trends, not significant. GPT is numerically worse: −10.5% (15.77 → 17.43).
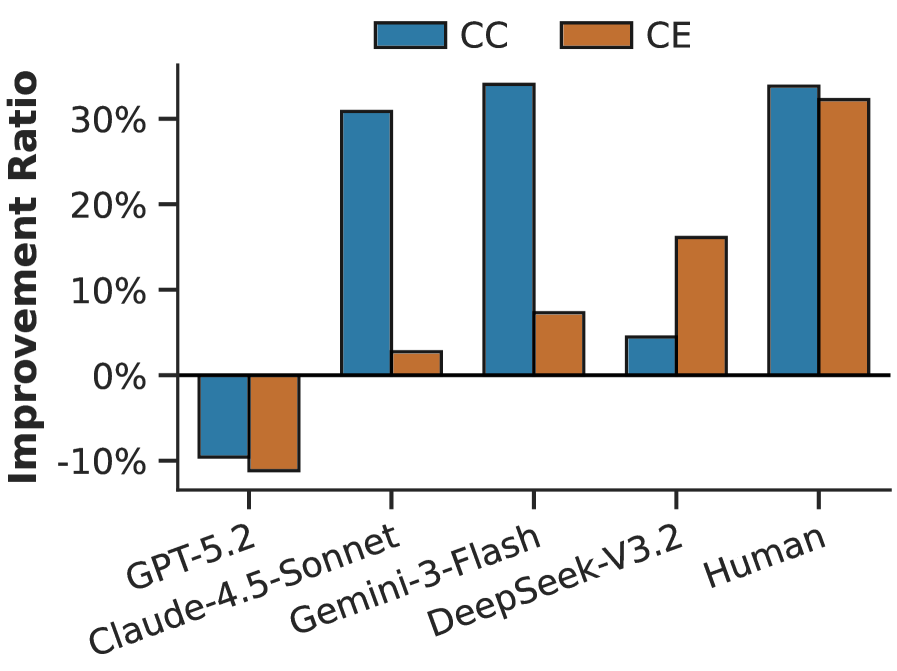
Figure 3 makes the headline transfer-gap claim concrete by plotting percentage improvement from baseline to transfer per model × CC/CE. Humans tower over all models on both structures at roughly +33%, Gemini is the only model with a reliable positive bar, Claude and DeepSeek sit near +10–18% without significance, and GPT crosses into negative territory — directly visualising Table 2.

Figure 4 backs the core “delayed transfer” claim: per-solution marginal cost for baseline (gray) vs. transfer (red). Humans cut first-solution cost from 8.97 → 4.99 attempts (t(145)=3.82, p<.001, d=0.63). No model significantly reduces first-solution cost; gains appear only at solution 2 — Gemini 3.30 → 1.13 (p<.001, d=1.26), DeepSeek 7.52 → 5.57 (p=.016). Visually, the human red curve drops from the start; all four model red curves overlap gray at solution 1 and diverge only afterward, operationalising “environmental grounding precedes transfer”.
Conclusion
The practitioner takeaway: frontier LLMs/VLMs can match or beat humans at within-environment causal discovery in text (Gemini 9.08 vs. human 20.66 attempts) yet show grounding-dependent transfer — structural priors lie dormant until the model re-solves the problem once in the new environment, and even then only Gemini reaches statistical significance (+19.3%, d=0.55). Limits: only four proprietary models; a single paradigm (OpenLock) with a 3-action, 7-lever structure; CC/CE graphs of depth 2; no mechanistic probes distinguishing “grounding” from vanilla in-context learning — a caveat the authors themselves flag. The title promises a general claim about AI-vs-human causal transfer; experiments establish it only for this specific interactive lever task.
Novelty Check
The authors’ closest-cited prior art is Edmonds et al. 2018 ([4], OpenLock humans vs. RL) plus extensions in 2019–2020 ([5,6]); their delta is porting the paradigm to modern LLMs/VLMs and adding vision/modality contrasts plus the “environmental grounding” framing. Structure-mapping roots are acknowledged via Gentner 1983 and Holyoak & Cheng 2011. Independently, recent LLM causal-reasoning work (Kiciman et al. 2023 [17], Jin et al. CLadder [15] / correlation-to-causation [16]) is cited but targets static textual causal queries, so the interactive/transfer angle is a genuine extension, not a relabel. The specific contribution — showing retrospective rather than prospective transfer in current frontier models — I have not seen documented elsewhere; it is a modest but real empirical advance.
Open Questions
- Does the delayed-transfer pattern hold for deeper graphs or >2-stage action sequences, or is it an artefact of OpenLock’s narrow 3-action budget?
- Would chain-of-thought, tool use, or explicit scratchpad-based schema extraction close the prospective-transfer gap, or is the limitation deeper?
- Is Claude’s human-like non-linear acceleration a training-data artefact (e.g. more scientific-reasoning data) or an architectural property? A controlled ablation across checkpoints would disambiguate.
- Can fine-tuning with the authors’ proposed “structure-mapping curricula” actually induce first-attempt transfer, and does it generalise beyond CC/CE?
- How would open-weight models (Llama-family, Qwen) and reasoning-tuned variants (o-series style) compare — is the effect tied to frontier scale or to specific post-training?
Original abstract
Extracting abstract causal structures and applying them to novel situations is a hallmark of human intelligence. While Large Language Models (LLMs) and Vision Language Models (VLMs) have shown strong performance on a wide range of reasoning tasks, their capacity for interactive causal learning – inducing latent structures through sequential exploration and transferring them across contexts – remains uncharacterized. Human learners accomplish such transfer after minimal exposure, whereas classical Reinforcement Learning (RL) agents fail catastrophically. Whether state-of-the-art Artificial Intelligence (AI) models possess human-like mechanisms for abstract causal structure transfer is an open question. Using the OpenLock paradigm requiring sequential discovery of Common Cause (CC) and Common Effect (CE) structures, here we show that models exhibit fundamentally delayed or absent transfer: even successful models require initial environmental-specific mapping – what we term environmental grounding – before efficiency gains emerge, whereas humans leverage prior structural knowledge from the very first solution attempt. In the text-only condition, models matched or exceeded human discovery efficiency. In contrast, visual information – in both the image-only and text-and-image conditions – overall degraded rather than enhanced performance, revealing a broad reliance on symbolic processing rather than integrated multimodal reasoning. Models further exhibited systematic CC/CE asymmetries absent in humans, suggesting heuristic biases rather than direction-neutral causal abstraction. These findings reveal that large-scale statistical learning does not produce the decontextualized causal schemas underpinning human analogical reasoning, establishing grounding-dependent transfer as a fundamental limitation of current LLMs and VLMs.