arXiv: 2604.24647 · PDF
作者: Zahra Dehghanighobadi, Asja Fischer
单位: Ruhr University Bochum, UAR Research Center for Trustworthy Data Science and Security
主分类: cs.CL · 全部: cs.AI, cs.CL
命中关键词: large language model, llm, reasoning, inference, kv cache, attention
TL;DR
DepthKV 指出 Transformer 各层对 KV cache 剪枝敏感度差异显著,按 InfoNCE 等表征指标在固定全局预算下做层级非均匀分配,在摘要/QA/数学推理任务上一致优于 uniform 剪枝。
Motivation
长上下文 LLM 推理的瓶颈已从算力转向显存:KV cache 随序列长度线性增长,prefill 阶段对超长文档(本文测 3K–10K token)的 serving 吃满 GPU HBM。现有 post-training KV pruning(H2O、StreamingLLM、SnapKV、FastGen)几乎都默认所有 Transformer 层同等重要,按同一比例剪各层——这在工程上简单但作者认为是错的。Skean et al. (2025) 已指出中间层表征更关键,但没人验证这是否延伸到 KV 剪枝。今天需要长文档摘要 / 多跳 QA / 长链路数学推理的团队,在固定显存预算下只能凑合用 uniform 剪枝,或者退回 full KV 把 batch 压小。作者主张:只要能识别"哪些层剪了会塌",就能在同一全局预算内重新分配预算,拿到免费的质量提升,无需改架构、无需重训。
核心观点
- Transformer 各层对 KV 剪枝的敏感度差异显著,通过 permutation test(p < 0.05,N_perm=10000)统计性地拒绝"均匀重要性"假设。
- 存在"content amplification layers":剪掉它们会压制生成内容本身(YapScore 下降),且与下游 ROUGE-1 强相关(GEM7 在 LegalCase 上 r=0.9902,Table 1)。
- 表征指标(尤其 post-attention InfoNCE)可作为层重要性的预测器——InfoNCE 越低的层越敏感,是最稳定的 predictor。
- 提出 DepthKV 框架:在固定全局预算下按层重要性非均匀分配 KV budget,提供 MLP(保中间层)、MGA(按 InfoNCE 分配)、MLMA(两者混合)三种策略。
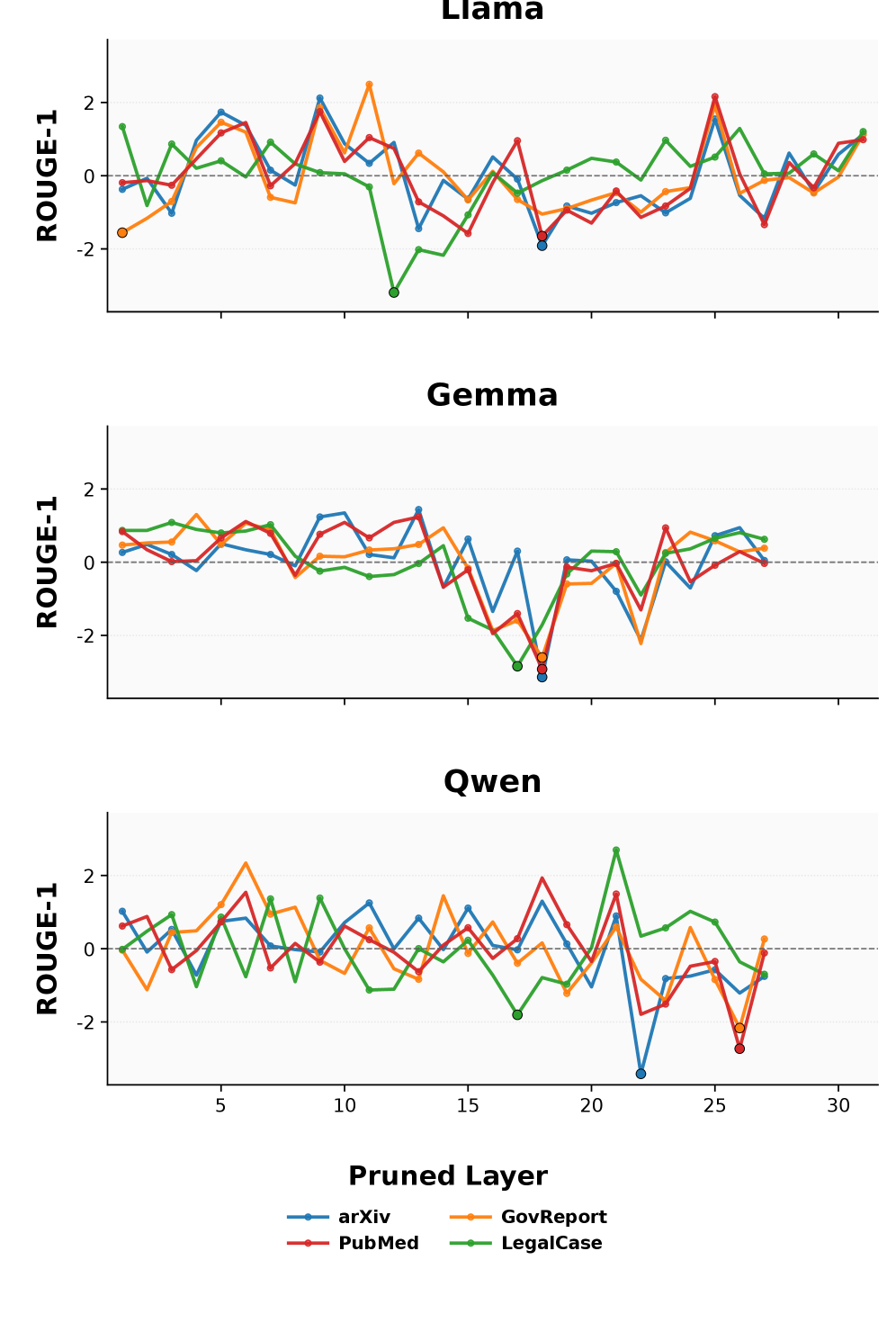
图 2 是核心观点一的实证支撑:对每层单独做 H2O w/o V 剪枝,记录 ROUGE-1 标准化后的 z-score。不同数据集/模型的敏感峰位置不一致(markers 标出每个数据集最大下降层),说明关键层既存在、又不对齐,uniform 分配无法应对。
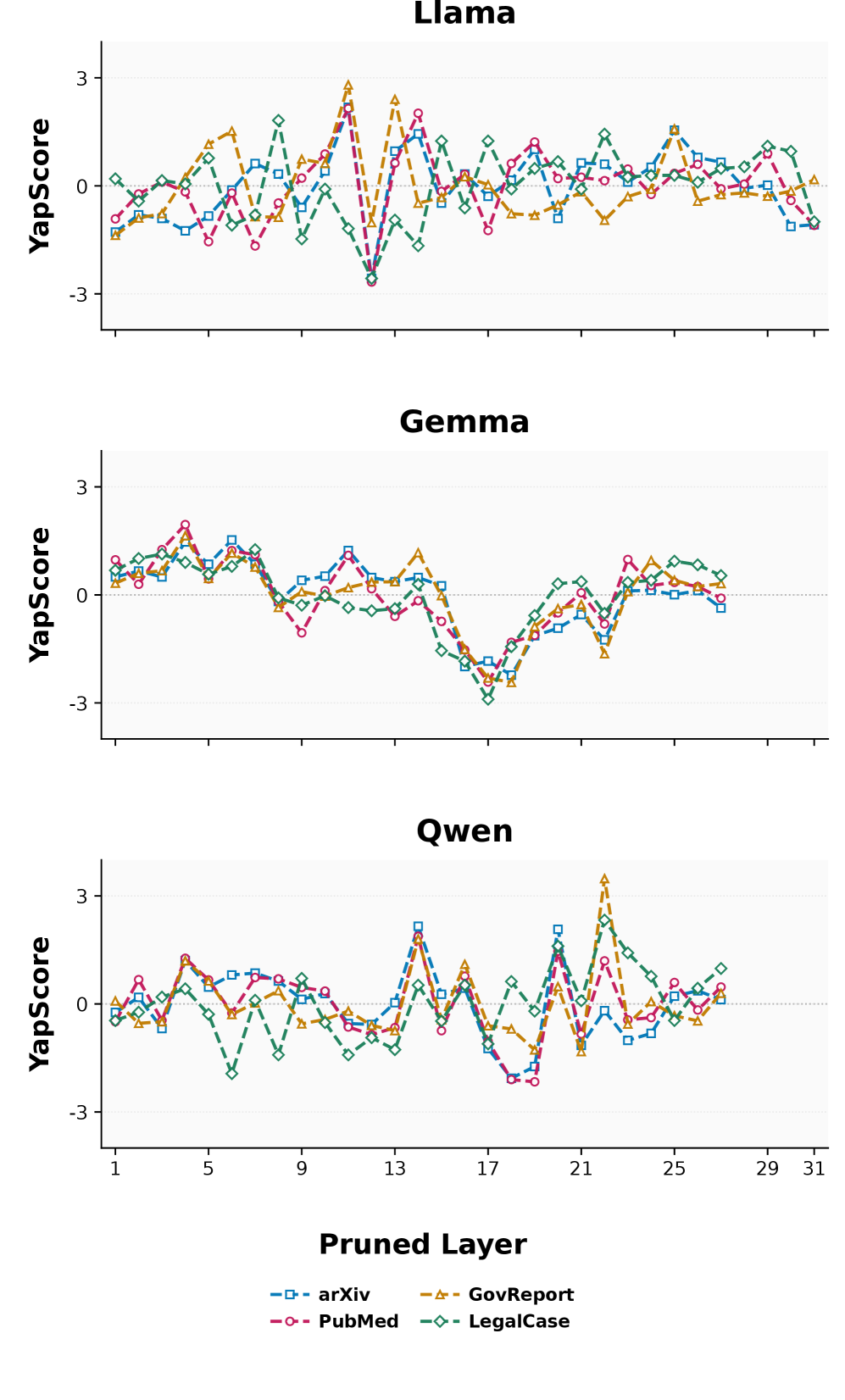
图 3 支撑"content amplification layers"论点:各数据集在单层剪枝下的 YapScore z-score 曲线,在少数特定层出现显著下陷,这些层恰好与 ROUGE-1 上最敏感的层重合——即这些层被剪掉时模型输出大幅缩水,是性能退化的直接机制。
方法
问题形式化:decoder-only Transformer 有 L 层,每层分配 KV 预算 B^(l),受全局约束 ΣB^(l)=B_total。token 级重要性沿用 H2O(w/o V:累积注意力;w/ V:累积注意力乘 value 范数 ℓ1/ℓ2)。关键创新在层间分配:
- MLP(Middle-Layer Protection):保留中间两层 ⌊L/2⌋ 和 ⌊L/2⌋+1 完整 KV,其余层均匀剪。
- MGA(Metric-Guided Allocation):把 post-attention InfoNCE 反向映射为得分 s^(l)(InfoNCE 低 = 敏感 = 得分高 = 预算多),归一化后按比例分配剪枝率,单层上限 ρ_max=0.7 防塌陷,超出部分迭代重分配给未饱和层。
- MLMA:结构保护 + InfoNCE 分配组合,变体 2L/4L/6L 对应保护 2/4/6 个中间层。
首层不剪。pruning 发生在 prefill 阶段、chunk size=1024 的 chunked prefill 里,每处理一个 chunk 更新 importance 分数并剪 KV;decoding 期间 KV 固定。
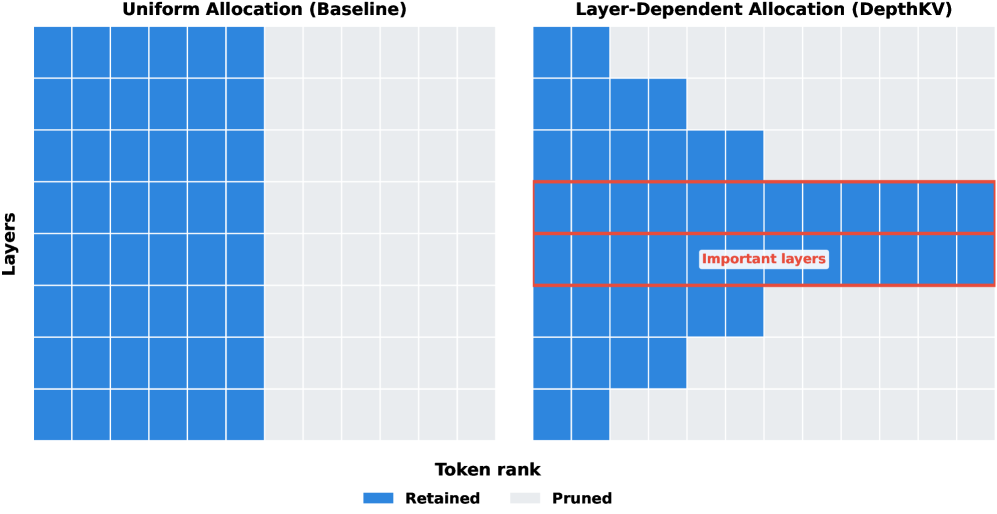
图 1 对比 uniform 与 DepthKV 的分配机制:左侧 uniform 各层保留相同 token 数(颜色均匀),右侧 DepthKV 给关键层(高亮)更多预算、给冗余层更激进剪枝,token rank 体现相对重要性——这就是本文方法所有变体共同的核心 intuition 图。
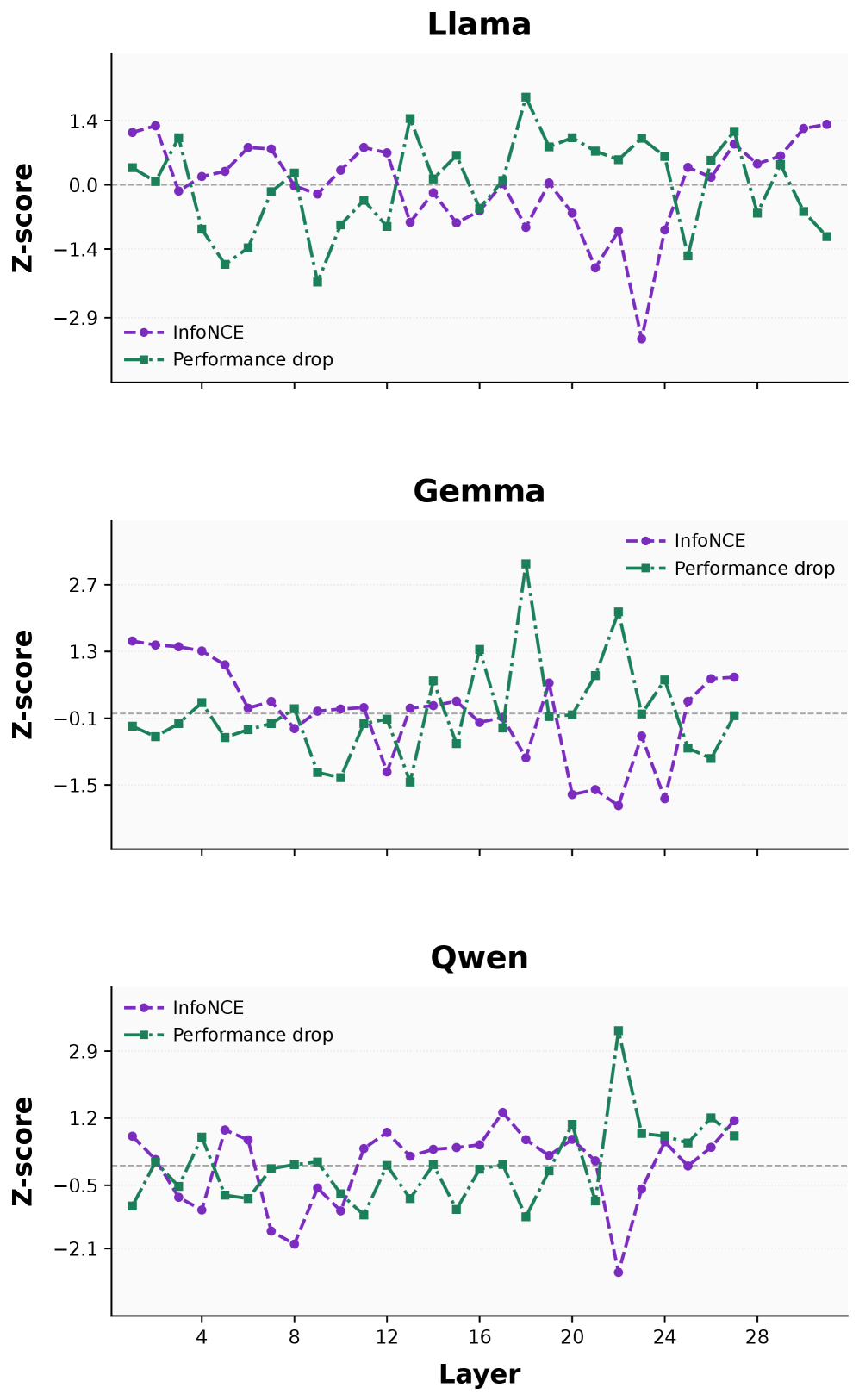
图 4 支撑 MGA 使用 InfoNCE 的合理性:arXiv 数据集下,post-attention InfoNCE(标准化)与 ROUGE-1 性能下降曲线呈明显负相关——InfoNCE 低的层剪掉下降更大,于是 MGA 就把预算倾向这些层。
实验
数据集:四个长文档摘要 benchmark(arXiv, PubMed, GovReport, LegalCase,平均 4.9K–5.8K words)各 1000 样本;两个 QA(HotpotQA 1000、Qasper 100,≤4K token);数学推理 GSM-∞ 500 样本。模型:gemma-7b-it (GEM7)、Llama-3.1-8B-Instruct (LAM8)、Qwen2.5-7B-Instruct (QWEN7)。Baseline:FullKV、H2O w/o V、H2O w/ V (ℓ1/ℓ2)(全部 uniform)。全局剪枝率固定 60%。指标:摘要用 ROUGE-1/2/L、SBERT、YapScore;QA 用 EM + precision/recall/F1;LLM-as-judge 用 Prometheus-8x7b 评 Correctness/Completeness/Conciseness。硬件:8×H200。
结果
摘要(Gemma,Table 3):arXiv 上 MGA 把 ROUGE-1 从 uniform w/o V 的 26.75 提到 29.75(+3.0),SBERT 从 55.09 提到 61.98(+6.89),是所有变体最佳;GovReport 上 MGA 把 ROUGE-1 从 26.76 提到 28.43(+1.67),SBERT 从 62.05 提到 70.24(+8.19)。但 GovReport 上 MLMA/MLP 反而低于 uniform(MLP ROUGE-1=23.24 < w/o V 26.76),说明结构化保护不稳定。
QA(Table 4,EM%):Qasper 上 MLMA-6L 拿下 GEM7=40 与 LAM8=64(vs w/o V GEM7=6/LAM8=54);HotpotQA 上策略依模型不同——GEM7 MLP 最佳 23(vs w/o V 12),LAM8 MGA 最佳 67(vs w/o V 47、逼近 FullKV 72)。Table 5 显示 MGA 在 LAM8/HotpotQA 上 F1=74,MLMA-6L 在 LAM8/Qasper 上 F1=76。LLM-as-judge(Table 6):MGA 在 LAM8 上 CR/CP/CN = 4.40/4.38/4.55,反超 FullKV(3.39/3.74/4.80 的 CR、CP)。
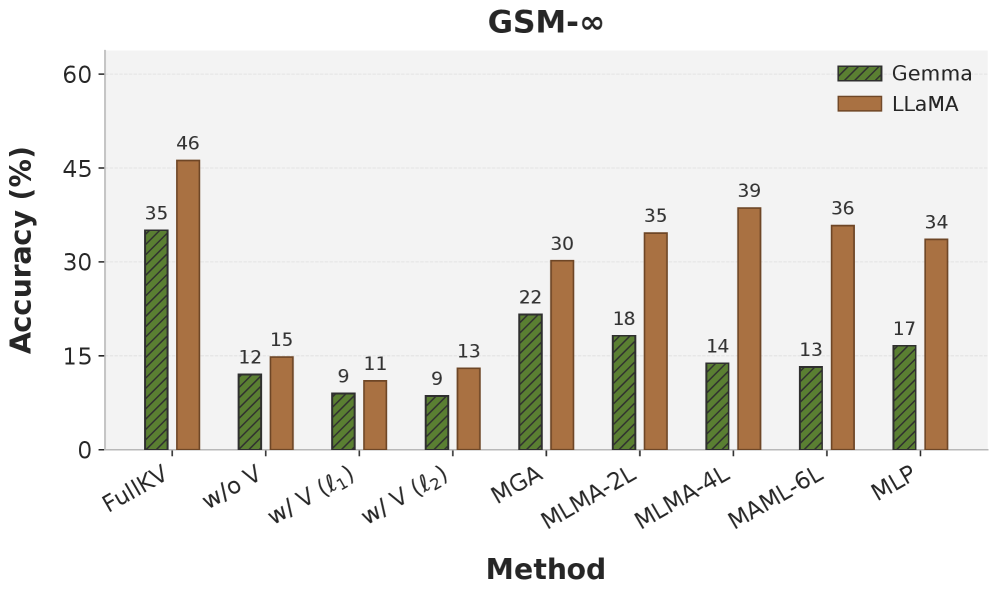
图 5 覆盖数学推理这一任务维度:GSM-∞ 上所有 DepthKV 变体都超过 uniform pruning baseline,论文正文未给出具体数值,但定性结论是"all variants outperforming uniform pruning"。作者没提具体百分点,是本节最薄弱的报告。
值得注意:value-aware(w/ V ℓ1/ℓ2)相对 w/o V 几乎无增益(arXiv ROUGE-1: 26.84 vs 26.75),作者明确承认主要收益来自层间分配而非 token importance estimator。
结论
实践者的 single takeaway:给定固定 KV 预算、现成 pretrained 模型、不改架构不重训,只把预算按 post-attention InfoNCE 在层间重分配(MGA),就能在 60% 剪枝率下比 uniform H2O 明显回血(arXiv ROUGE-1 +3.0, SBERT +6.89)。边界必须点清:(1)所有实验在 60% 一个剪枝率下跑,没扫 40%/80%;(2)三个模型全是 7B–8B instruct,没验证 70B+ 或 base model;(3)方法是 non-query-aware 且忽略 head 级差异,作者自己在 Limitations 里承认;(4)结构化策略(MLP/MLMA)在 GovReport 等数据集上反而掉点,说明"保中间层"并不通用;(5)GSM-∞ 的定量数字正文只放了图、未报具体精度。标题叫"Layer-Dependent KV Cache Pruning"但真正 work 的只有 MGA,MLP/MLMA 更多是 ablation。
是否新瓶装旧酒
作者自述的最近相关工作:H2O(Zhang et al. 2023)、SnapKV(Li et al. 2024)、FastGen(Ge et al. 2023)都是 token-level 重要性 + uniform 层分配;DuoAttention/SeerAttention 是 learned、需额外训练;Quest/RetrievalAttention/MorphKV 是 query-aware。作者把自己 frame 成"non-query-aware, heuristic, post-training,但转向 layer-wise sensitivity"这一空缺。
独立判断:FastGen (Ge et al. 2023) 其实已经按 head 分配不同保留策略,是"非 uniform 分配"的先例;PyramidKV / PyramidInfer(2024)也按层金字塔式递减 KV,早于本文直接探讨 layer-wise 非均匀分配——作者没引用 PyramidKV 这类同方向工作,有点遗漏。本文的实质 delta 是把 Skean et al. 2025 的表征分析(InfoNCE 等)作为分配依据首次迁移到 KV 剪枝,偏向系统化地把"表征敏感度 → 预算"这条链条落地,而不是完全 first-of-kind。
尚未回答的问题
- 不同全局剪枝率(20%/40%/80%)下 MGA 是否仍稳定胜出?
- InfoNCE 需要多少 calibration 样本才能算出稳健的层分配?工程上 overhead 是多少?
- 跨模型/跨数据集的 InfoNCE 分配可迁移吗,还是每次换模型都要重跑?
- 和 head-level 方法(FastGen、DuoAttention)combine 能否继续加益?作者自己承认忽略了 head 差异。
- 70B+ 模型和 base(非 instruct)模型上是否同样成立?
- query-aware 扩展(结合 Quest/MorphKV)下层分配是否还有意义?
原始摘要(中文翻译)
长上下文推理是大语言模型(LLM)的一项关键能力,支撑着长文档理解、摘要和代码生成等应用。然而,高效的自回归推理依赖 key-value(KV)cache,其显存占用随序列长度线性增长,形成主要的显存瓶颈。为缓解这一开销,KV cache 剪枝方法在推理过程中丢弃注意力分数较低的已缓存 token。大多数现有方法对所有层采用统一的剪枝比例,隐式地假设所有层对模型整体性能贡献相同。我们指出这一假设并非最优,因为各层对剪枝的敏感度差异显著。我们提出 DepthKV,一个层相关的剪枝框架,根据各层的敏感度将固定的全局 KV 预算分配到各层,而非使用统一分配。在多个模型和多个任务上,DepthKV 在相同全局剪枝率下始终优于统一剪枝,证明通过层相关分配能够更有效地利用 KV cache 预算。