arXiv: 2604.24647 · PDF
Authors: Zahra Dehghanighobadi, Asja Fischer
Affiliations: Ruhr University Bochum, UAR Research Center for Trustworthy Data Science and Security
Primary category: cs.CL · all: cs.AI, cs.CL
Matched keywords: large language model, llm, reasoning, inference, kv cache, attention
TL;DR
DepthKV reallocates a fixed global KV-cache budget non-uniformly across transformer layers based on per-layer sensitivity to pruning, using InfoNCE-derived importance scores. At 60% global pruning, it consistently beats uniform pruning (e.g., H₂O) across summarization, QA, and GSM-∞ reasoning on Gemma-7B, LLaMA-3.1-8B, and Qwen2.5-7B.
Motivation
Long-context LLM serving is memory-bound: the KV cache grows linearly with sequence length and quickly exceeds GPU memory on inputs of 5–10K tokens. Post-training KV pruning (H₂O, SnapKV, StreamingLLM, FastGen) is the most practical mitigation because it avoids retraining and is orthogonal to PagedAttention-style system tricks. But nearly all of these methods apply a uniform pruning ratio per layer — implicitly treating all transformer layers as equally important. The authors argue this is wrong: prior interpretability work (Skean et al., 2025) already hints that middle layers carry disproportionate representational load, and nothing in existing KV-pruning pipelines exploits that. The practitioners hurt today are teams deploying Gemma/LLaMA/Qwen-scale models for long summarization, multi-hop QA, or document reasoning under a fixed memory budget — they leave quality on the table because their pruner treats layer 3 and layer 15 identically. The gap DepthKV claims to fill: no prior post-training pruner allocates the global KV budget layer-dependently based on measured sensitivity. The framing is scoped honestly — the paper targets the prefill-dominated long-input/short-output regime and does not claim gains in query-aware or training-time settings.
Key Ideas
- Layer sensitivity to KV pruning is highly non-uniform; a permutation test rejects uniform-importance across all tested models/datasets (p<0.05, N=10,000 permutations; Appendix F).
- “Content amplification layers”: pruning certain layers collapses output length/informativeness (YapScore), strongly correlated with ROUGE-1 drop (r up to 0.99 on LegalCase for GEM7, Table 1).
- Representation metrics — especially InfoNCE at the post-attention stage — predict layer sensitivity: lower InfoNCE ⇒ larger degradation when pruned.
- Three allocation strategies under a fixed global budget: Middle-Layer Protection (MLP), Metric-Guided Allocation (MGA, InfoNCE-driven), and hybrids (MLMA-2L/4L/6L).
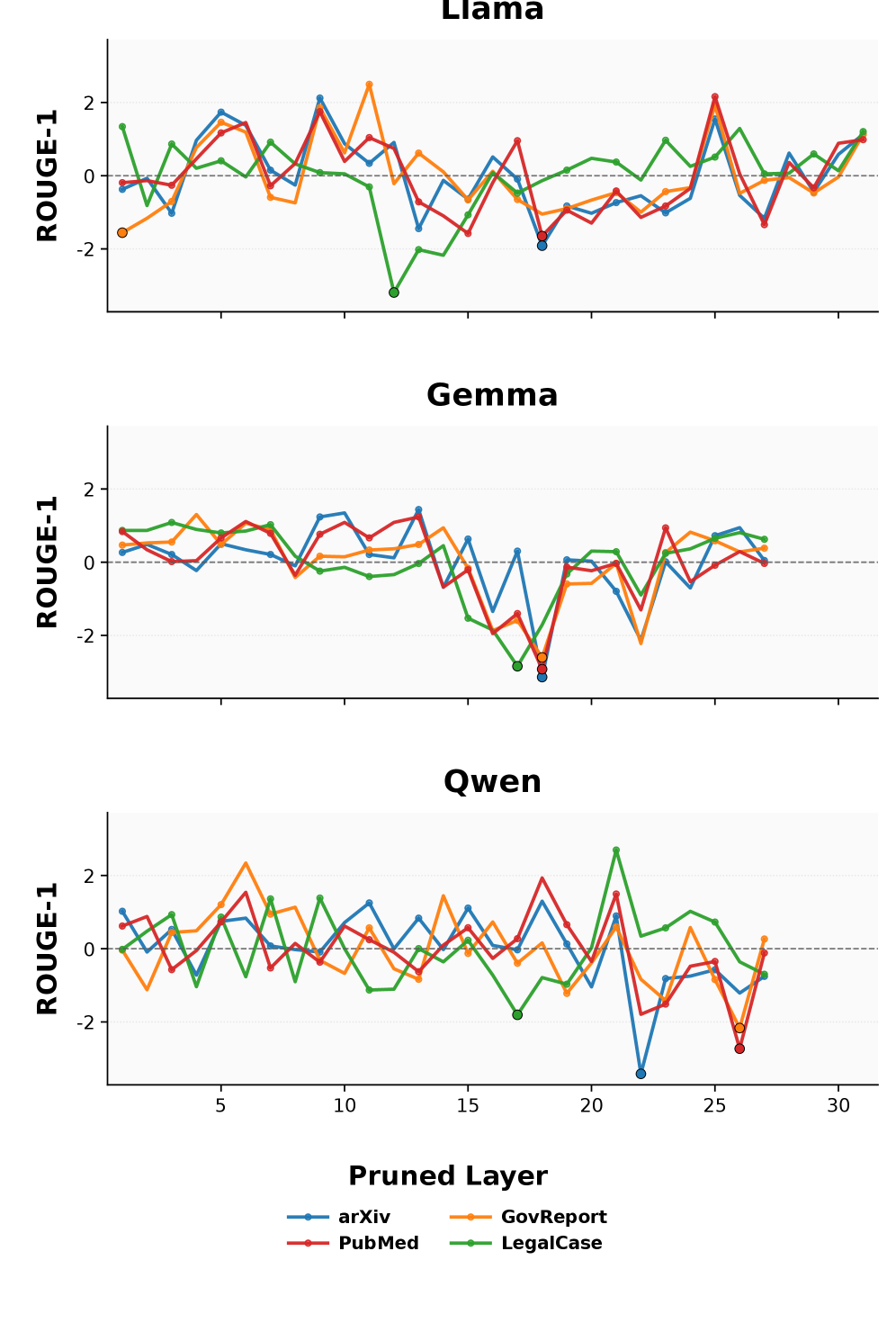
Figure 2 supports the non-uniform layer sensitivity claim that drives the whole paper. It reports z-score-normalized ROUGE-1 after pruning a single layer’s KV cache while leaving all others untouched, per model/dataset pair. The curves show sharp, dataset-specific troughs — one or two layers produce large performance drops (markers) while most layers deviate near zero. The takeaway is that a uniform-ratio pruner wastes budget on insensitive layers and under-protects the sensitive ones.
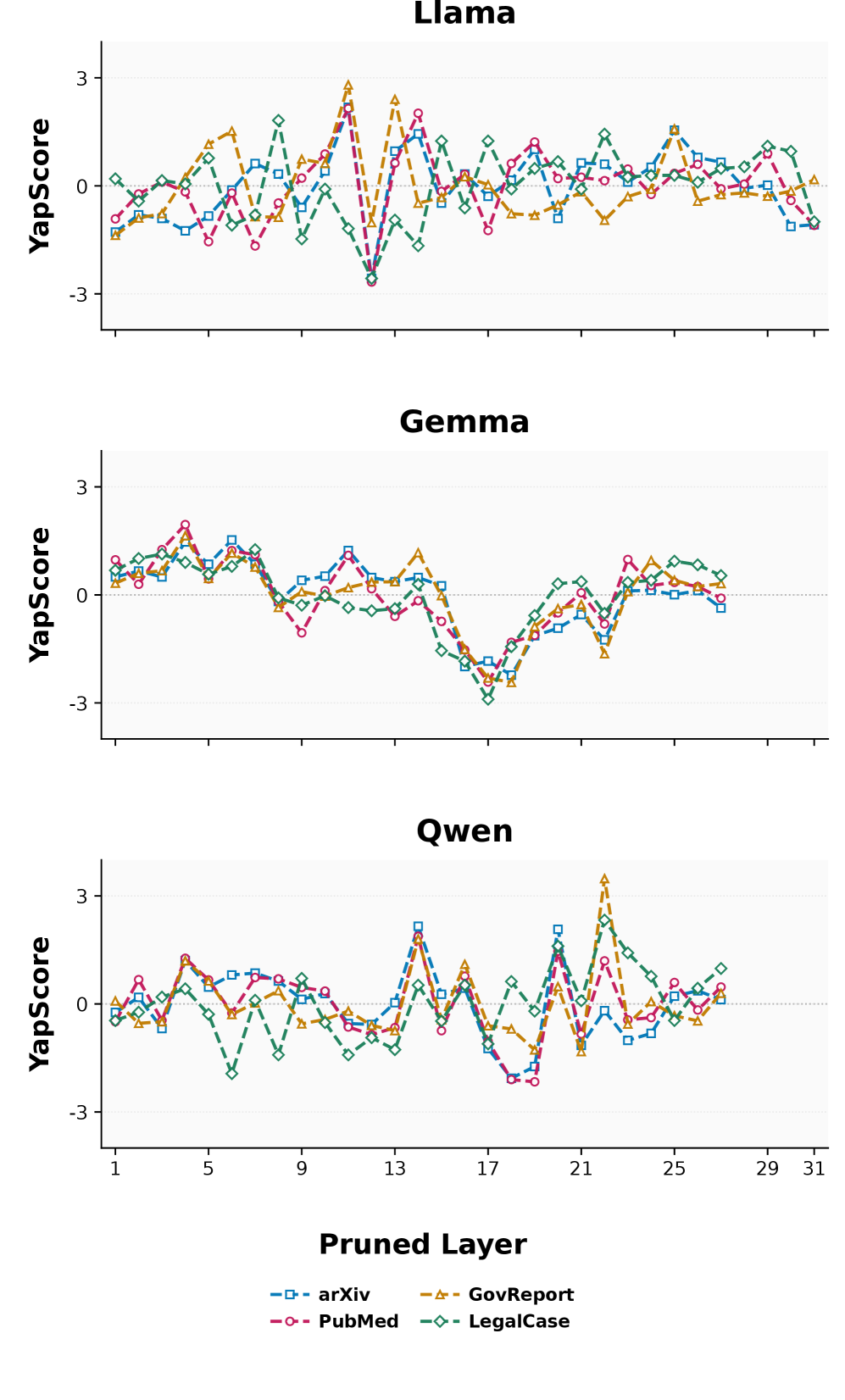
Figure 3 backs the content amplification claim in Key Ideas. Curves plot z-normalized YapScore (verbosity deviation from a fixed baseline) under single-layer pruning, per dataset. The layers that tank YapScore are approximately the same layers that tank ROUGE-1 in Figure 2 — pruning them makes the model stop generating content, not just lose accuracy. Table 1 quantifies this with Pearson r of 0.52–0.99 (p ≤ 2.5e-4) across models.
Method
DepthKV keeps the standard H₂O attention-score token importance (optionally value-weighted, Eq. 3–4) but replaces uniform per-layer budgets B^(l) with layer-specific ones summing to a fixed global B_total. The first layer is never pruned. MGA transforms each layer’s InfoNCE score s^(l) into an allocation weight α^(l) = s^(l) / Σ s^(j), assigns proportional pruning ratios, caps each layer at ρ_max=0.7, and iteratively redistributes any remaining mass to unsaturated layers until Σρ^(l) = Lρ. MLP hard-protects the two midpoint layers ⌊L/2⌋ and ⌊L/2⌋+1 and prunes the rest uniformly. MLMA-{2L,4L,6L} hybrids protect 2/4/6 middle layers, then use InfoNCE to spread the remaining budget. Pruning is executed at prefill with chunked prefill (1024-token chunks) updating importance scores after each chunk; the cache is frozen during decode.
Experiments
Datasets: four long-document summarization sets (arXiv, PubMed, GovReport, LegalCase; 5–10K-token inputs, 1,000 samples each) plus Qasper (100), HotpotQA (1,000), and GSM-∞ (500) for QA and math reasoning, capped at ≤4K tokens. Models: Gemma-7B-it (GEM7), Llama-3.1-8B-Instruct (LAM8), Qwen2.5-7B-Instruct (QWEN7). Baselines: FullKV (upper bound) and uniform pruning with H₂O w/o V, H₂O w/ V (ℓ₁, ℓ₂). Fixed 60% global KV reduction, greedy decoding, 500-token generation cap, 8× H200 GPUs. Metrics: ROUGE-1/2/L, SBERT, YapScore (summarization); EM + token P/R/F1 (QA); EM on GSM-∞; plus Prometheus-8×7B LLM-as-judge on correctness/completeness/conciseness (1–5 scale).
Results
Full text available; numbers traceable to tables/figures.
- Summarization on Gemma (Table 3): on arXiv, MGA lifts ROUGE-1 from 26.75 (uniform H₂O w/o V) to 29.75 and SBERT from 55.09 to 61.98; on GovReport, ROUGE-1 goes 26.76 → 28.43, SBERT 62.05 → 70.24. Value-aware uniform variants (w/ V ℓ₁/ℓ₂) barely move (26.84/26.63 R-1 on arXiv), confirming gains come from allocation, not token scoring.
- QA (Tables 4–5): on Qasper, MLMA-6L reaches EM=40 (GEM7) and 64 (LAM8) vs. 6 and 54 under uniform H₂O w/o V. On HotpotQA/GEM7, MLP raises EM from 12 → 23 and F1 from 14 → 26; on LAM8, MGA goes 47 → 67 EM and F1 from 55 → 74. Best strategy is model-dependent (MLP wins for GEM7, MGA for LAM8).
- LLM-as-judge on HotpotQA (Table 6): MGA’s CR/CP/CN on LAM8 is 4.40/4.38/4.55, beating uniform’s 3.59/3.60/3.76 and even exceeding FullKV’s 3.39/3.74/4.80 on CR/CP (plausibly because shorter MGA answers get higher conciseness credit — the paper does not isolate this).
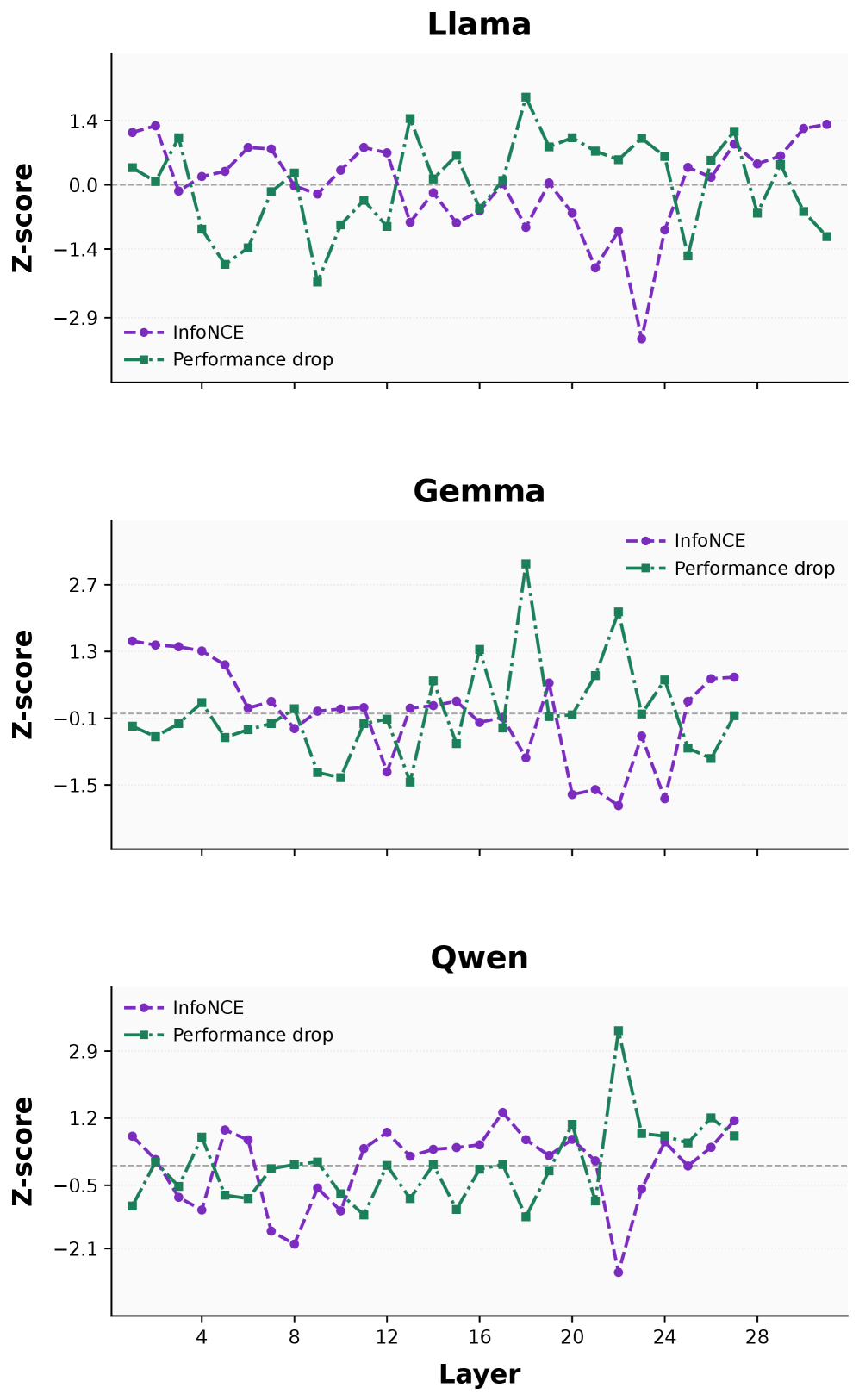
Figure 4 is the evidence that InfoNCE (post-attention) is a usable proxy for layer importance — the mechanism MGA depends on. It overlays standardized InfoNCE against the measured ROUGE-1 drop per layer on arXiv; the curves are inversely aligned, meaning layers with low InfoNCE (representations not invariant to input perturbations) are exactly the layers whose pruning hurts ROUGE-1 most. This is what justifies using InfoNCE as the α^(l) signal in Section 5.
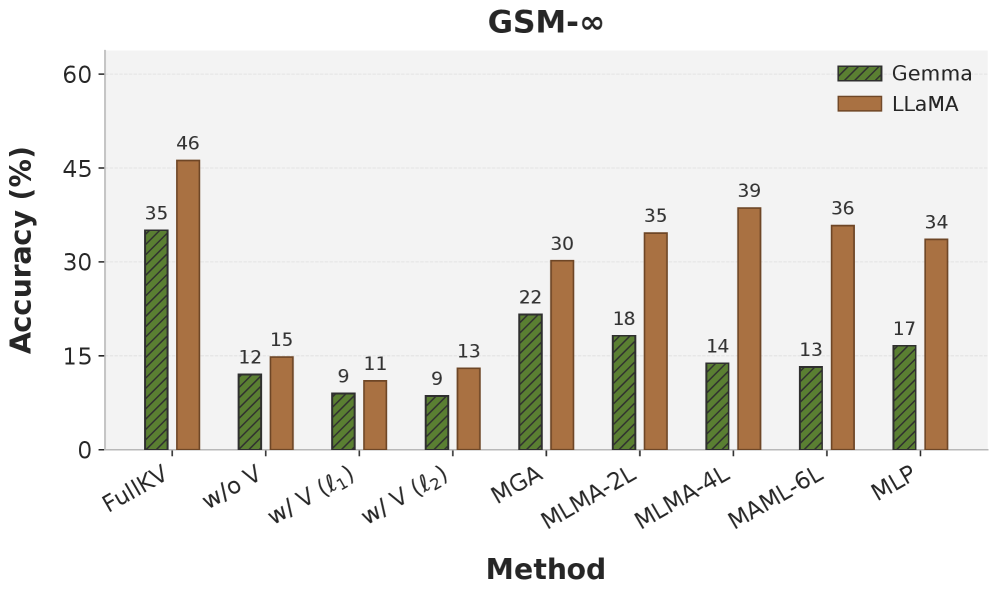
Figure 5 supports the generalization beyond summarization/QA claim. It plots GSM-∞ accuracy across uniform-pruning baselines and the DepthKV variants; per the body, all DepthKV variants beat uniform pruning. The paper does not report exact numbers in-line for Figure 5, so the magnitude of the math-reasoning gain is not quantified in the text — treat this as a directional result.
Conclusion
The practitioner takeaway: if you are already running H₂O-style KV pruning under a fixed memory budget, swap uniform-per-layer allocation for InfoNCE-driven MGA and expect meaningful quality recovery — e.g., ROUGE-1 26.75 → 29.75 on arXiv/GEM7 at 60% global pruning, with zero retraining. Honest scope: results are established only at 7–8B scale, only on three decoder-only instruction-tuned models, only at a single 60% pruning ratio, only in the long-input/short-output prefill-dominant regime, and only in non-query-aware mode. The title says “long-context LLM inference” but inputs cap at ~10K tokens for summarization and ≤4K for QA/reasoning — the 128K–1M context claim from the introduction is not tested. No wall-clock/throughput measurements are reported; “efficient utilization” is quality-per-budget, not latency.
Novelty Check
The authors position DepthKV explicitly as layer-wise allocation on top of existing token-importance scorers (H₂O, Guo et al. 2024 value-aware variant), and as complementary to token-level methods (SnapKV, StreamingLLM, FastGen) and query-aware methods (Quest, RetrievalAttention, MorphKV). The explicit claim of novelty is “focusing on layer-wise sensitivity instead of token-level importance” under the same global budget. This is plausible within the post-training, non-query-aware class they target. However, non-uniform per-layer KV budgets are not entirely new — PyramidKV/PyramidInfer (2024) already allocate decreasing budgets across layers by depth heuristics, and neither is cited. If PyramidKV/PyramidInfer is the real closest prior art, DepthKV’s contribution narrows to: (a) using InfoNCE as a principled per-layer importance signal instead of a fixed pyramid prior, and (b) the content-amplification analysis linking YapScore to ROUGE. That is a meaningful refinement, not a category-creating result. Authors’ “first to do layer-wise KV allocation” framing is overstated relative to published prior work.
Open Questions
- How does DepthKV compare to PyramidKV/PyramidInfer head-to-head under the same 60% budget?
- Does the InfoNCE ranking transfer across datasets/domains, or does it need per-dataset recomputation (the per-model InfoNCE tables in Appendix G vary by dataset)?
- Behavior at other pruning ratios (30%, 80%, 95%) — does MGA still dominate, or does the cap ρ_max=0.7 hurt at aggressive budgets?
- Wall-clock prefill/decode latency and memory: the paper reports no throughput numbers, so the “efficient inference” framing is quality-only.
- Interaction with query-aware methods (Quest, MorphKV): the limitations section flags this; no experiments.
- Scaling: only 7–8B models, ≤10K-token inputs. Does layer sensitivity structure hold at 70B+ and 100K+ contexts?
- Head-level extension: authors note attention heads serve specialized roles but DepthKV aggregates across heads — does joint layer+head allocation help?
Figures
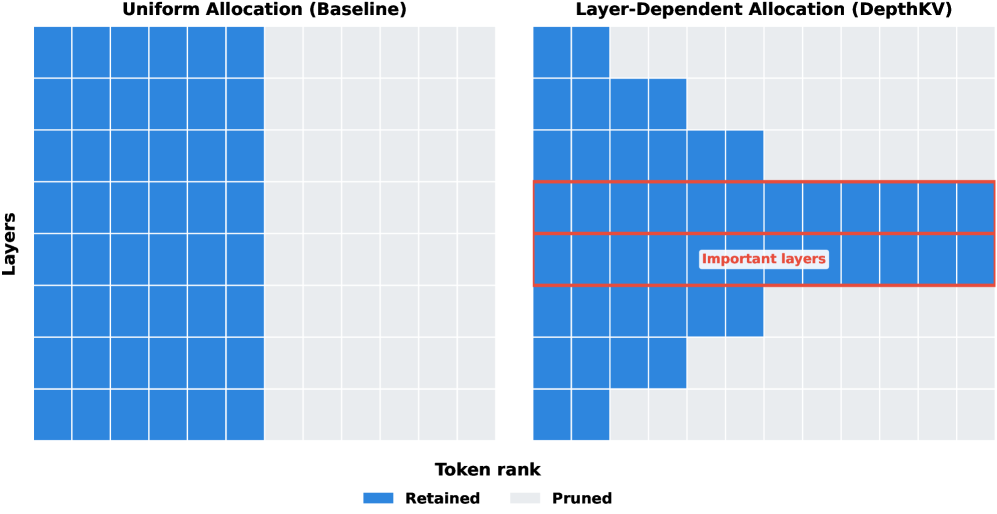
Figure 1: Figure 1: Uniform vs. layer-dependent KV allocation. Uniform allocation (left) assigns an equal KV budget across transformer layers. DepthKV (right) reallocates this budget based on sensitivity to pruning, retaining more tokens in critical layers (highlighted) and pruning less important ones more aggressively. Token rank denotes relative importance.
Original abstract
Long-context reasoning is a critical capability of large language models (LLMs), enabling applications such as long-document understanding, summarization, and code generation. However, efficient autoregressive inference relies on the key-value (KV) cache, whose memory footprint grows linearly with sequence length, leading to a major memory bottleneck. To mitigate this overhead, KV cache pruning methods discard cached tokens with low attention scores during inference. Most existing methods apply a uniform pruning ratio across layers, implicitly assuming that all layers contribute equally to overall model performance. We show that this assumption is suboptimal, as layers differ significantly in their sensitivity to pruning. We propose DepthKV, a layer-dependent pruning framework that allocates a fixed global KV budget across layers based on their sensitivity, rather than using a uniform allocation. Across multiple models and tasks, DepthKV consistently outperforms uniform pruning at the same global pruning ratio, demonstrating more effective utilization of the KV cache budget through layer-dependent allocation.