arXiv: 2604.24039 · PDF
作者: Hojoon Kim, Yuheng Wu, Thierry Tambe
单位: Stanford University, Harvard University
主分类: cs.LG · 全部: cs.AI, cs.CL, cs.LG
命中关键词: large language model, llm, agent, agentic, multi-agent, rag, latency
TL;DR
AgenticCache 利用 embodied 任务的「plan locality」,让 agent 通过 2-gram plan 缓存 + 后台异步 LLM 更新器避免逐步调用 LLM,在四个多 agent benchmark 上平均成功率 +22%、延迟 -65%、token -50%。
Motivation
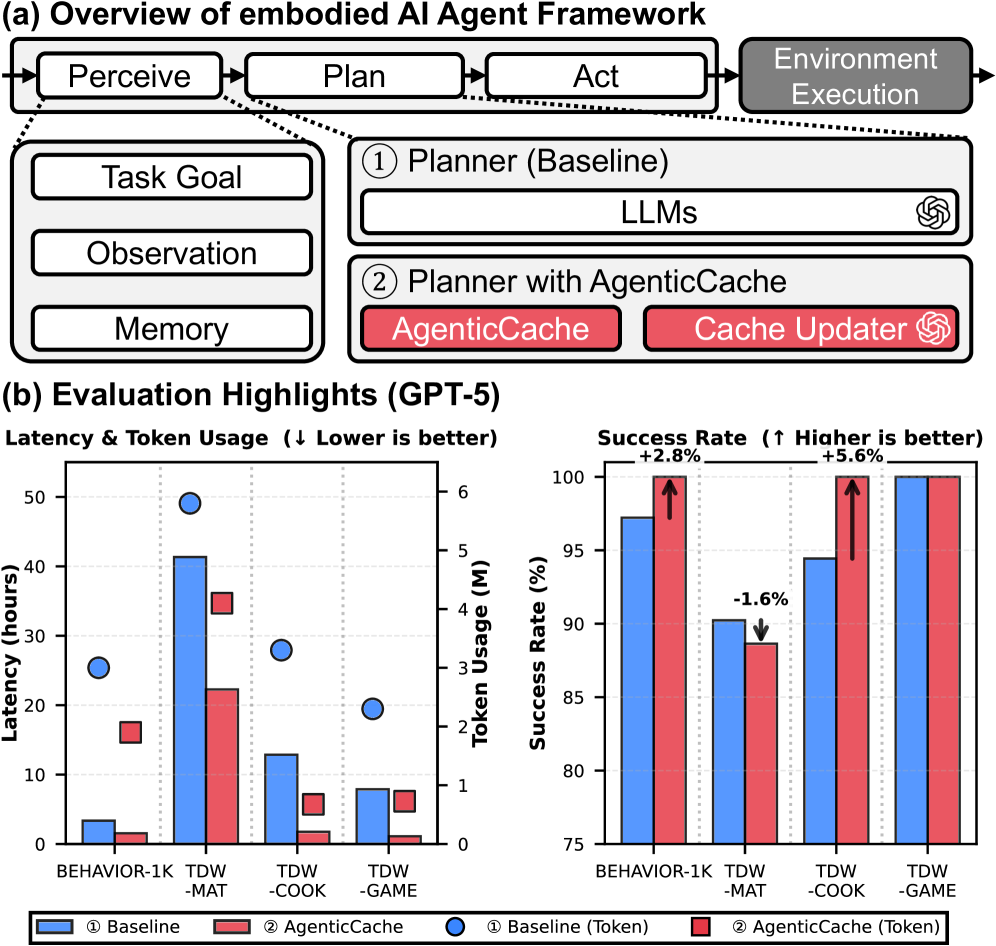
LLM 驱动的 embodied agent 当前采用同步 plan-act 循环:每一步动作前都要等 LLM 返回一个新 plan,结果是 Figure 2 显示跨 benchmark 超过 70% 的运行时间消耗在 LLM planning query 上。对于需要数千步长 horizon 的多 agent 仿真(TDW-MAT、BEHAVIOR-1K 等),这意味着 GPT-5 baseline 在 TDW-MAT 上要跑 41.34 小时、花 40.5 美元(Table 2)——对任何想做大规模 evaluation 或实际部署的团队都难以承受。
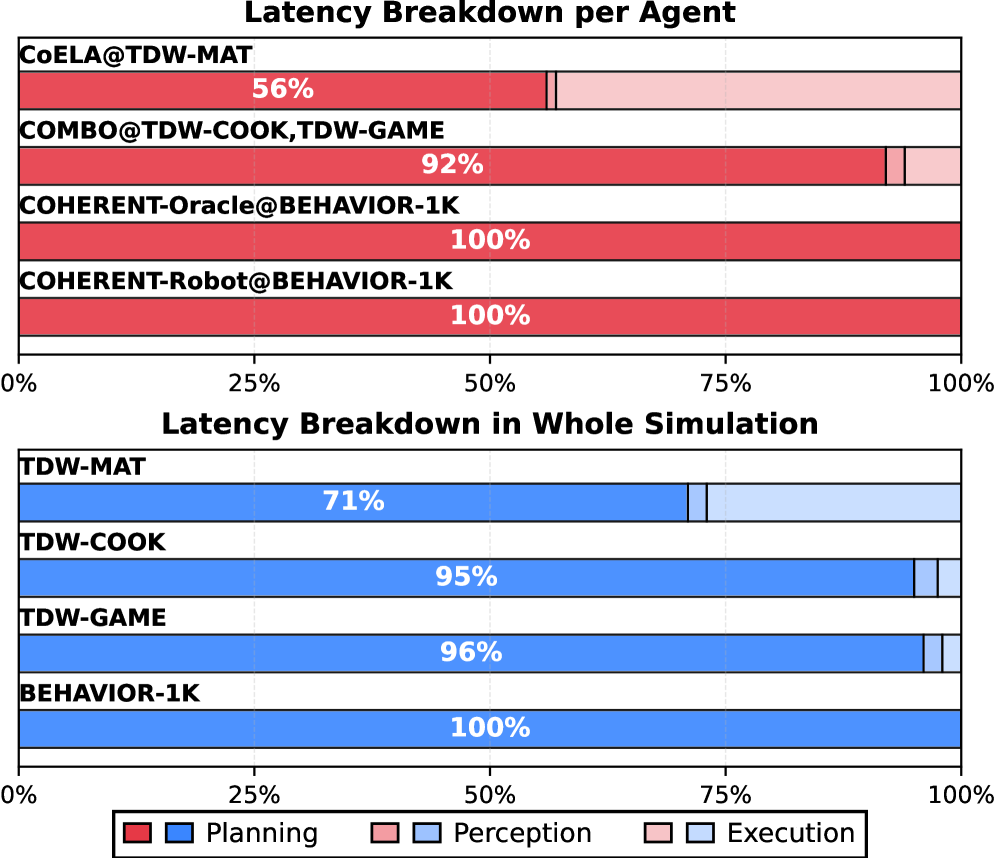
图 2 按 agent 类型把 TDW-MAT / TDW-COOK / TDW-GAME / BEHAVIOR-1K 的运行时间拆成 LLM 调用 vs 其他部分,结果 LLM 占比均超过 70%,直接说明"逐步调 LLM"就是瓶颈。这也是整篇工作要打掉的具体痛点,而不是笼统讲"LLM 慢"。
现有 workaround 有两条:Parallelized Planning-Acting(Li et al. 2026,边 act 边 prefetch 下一步 plan)和 Speculative Planning(Hua et al. 2025,小模型先 draft 大模型 verify)。但两者都还是每步打 LLM,trajectory 越长成本线性涨;而且 prefetch 的 plan 一旦环境改变就失效,要回滚重规划。作者指出现在「前置条件」变了:embodied 任务的 plan 转移高度规律(plan locality),可以把缓存+分支预测那套思路搬过来替换逐步 LLM 调用。
核心观点
- Plan locality 是普遍现象:用 2-gram 统计 GPT-5 执行轨迹,很多 plan 只有少量可能的后继(如 “go grasp target → put into container” 占 59.7%)。
- 纯缓存不够用:环境变化会让缓存 plan 过时(例如目标物体被另一个 agent 拿走),必须有 context-aware 的修正机制。
- 提出 AgenticCache:2-gram plan 转移缓存 + 后台异步 Cache Updater(LLM 校验/修正),每条 entry 带 metadata range 做过滤,用
C·I(count × importance)评分选择下一个 plan,灵感来自硬件分支预测器的 local+global history 组合。 - 异步更新 + 即时替换:Updater 返回时要么确认当前 plan(抑制冗余查询),要么立刻用正确 plan 替换正在执行的 plan。
- 可选的 offline prefilling:用 1–4 个成功 GPT-5 episode 预填缓存,避免 cold miss;但非必需,cold-start 仍能获益。
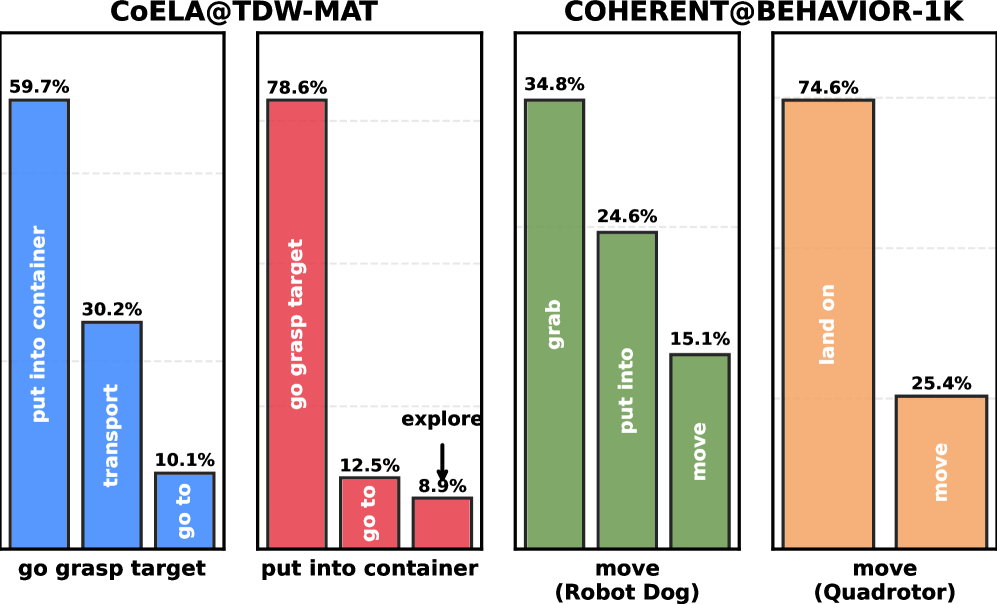
图 4 展示 GPT-5 执行轨迹的 2-gram 后继概率分布——大量转移集中在少数候选上,例如 “go grasp target” 后最大概率的后继占 59.7%。这是整篇论文假设成立的实证底盘:如果 plan 转移是近均匀分布,缓存就不会有收益。
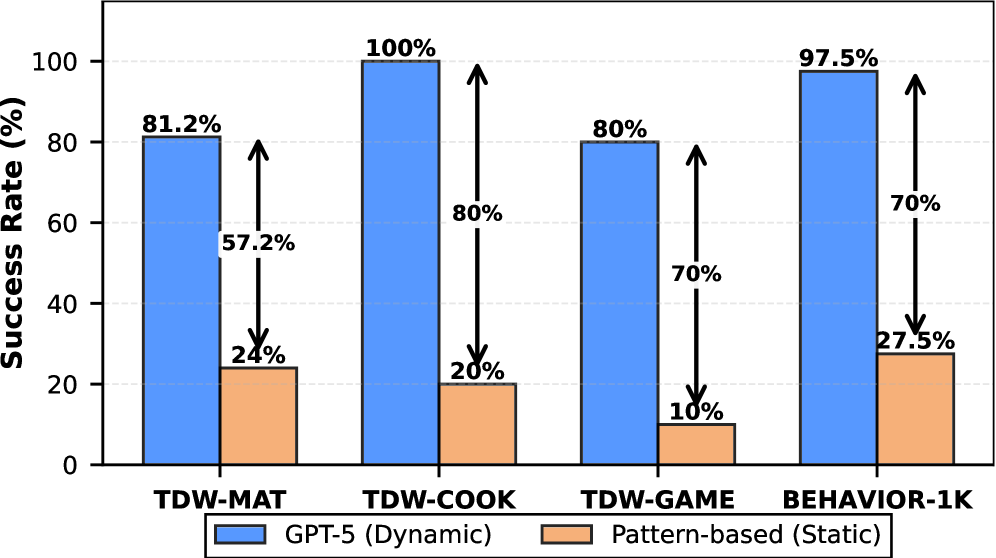
图 5 对比「纯按缓存 pattern 走的 agent」与 GPT-5 agent 的性能,显示无 context-aware 更新时成功率明显下降。这直接说明为什么 AgenticCache 必须配一个后台 LLM updater,而不是单纯把 2-gram 频率表查下去——这张图是"hybrid 设计必要性"的论据。论文正文未给出该图具体数值。
方法
每个 agent 维护独立缓存,entry 为 ⟨Pᵢ→Pⱼ⟩ 的 2-gram 模式,并记录任务状态 metadata(如 TDW-MAT 中的 step index、持有物品数、已完成子目标数、访问过的房间数)按 min/max 存成整数区间。运行时以上一步 plan + 当前 metadata 为 key 查询:先按 metadata range 过滤得到可行候选集 𝓕(Pᵢ),再用复合得分 S(Pᵢ→Pⱼ) = C(Pᵢ→Pⱼ) · I(Pⱼ) 选最高分——C 是转移出现次数(local),I = N_conf/N_cand 是 LLM 确认率(global),论文明确类比 Yeh & Patt / Smith 的 hybrid branch predictor。
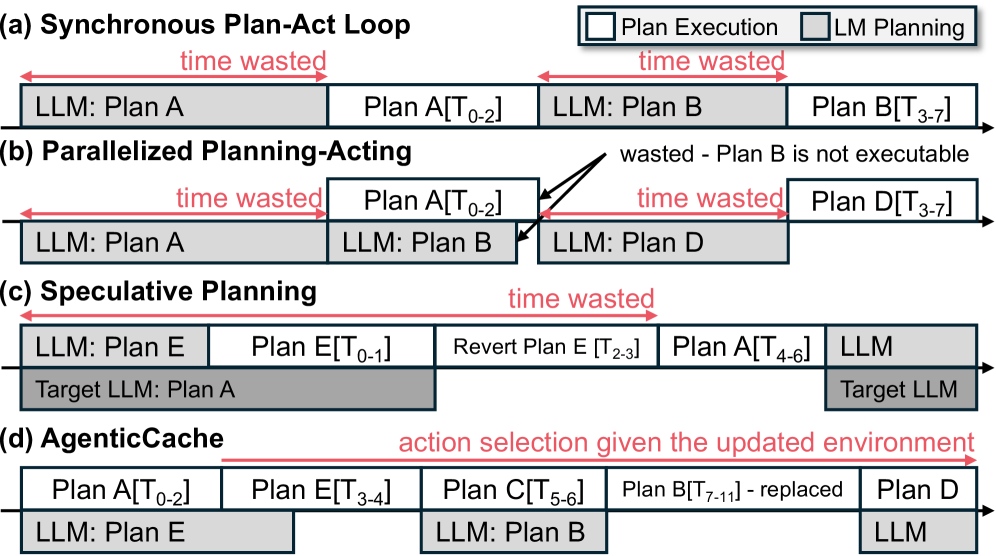
图 3 并排对比四种 planning 策略:(a) 同步 plan-act、(b) 并行 planning-acting、(c) speculative planning、(d) AgenticCache。前三者都在每一步调 LLM,而 (d) 把 LLM 调用移到后台异步通道,主循环靠缓存返回 plan。这张图是理解 AgenticCache 相对于 baseline 的关键时序差异。
后台 Cache Updater 是异步 LLM 进程:发 query 时记录 (cₜ, pₜ),k 步后收到 p′ₜ₊ₖ。若 p′ 出现在已执行的 trajectory 中→Confirmation(加 count 与 N_conf,并启用"确认抑制"直到当前 plan 结束);否则→Correction(新增或更新 pₜ→p′ₜ₊ₖ、扣减被错选的转移 count、并立即用 p′ 替换正在执行的 plan,然后启用"修正抑制"直到新 plan 结束)。Cache miss(候选被 metadata 过滤光)时才退回同步 LLM 调用,并把结果写入新 entry。可选 offline prefilling 用 1–4 条 GPT-5 成功轨迹预填缓存做 warm start。
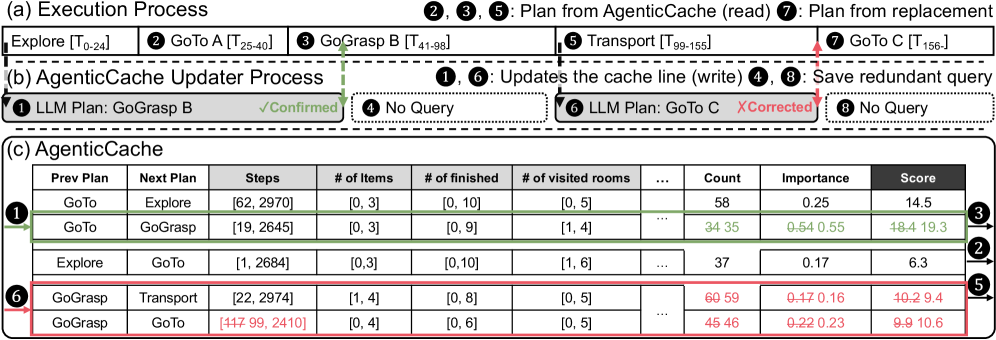
图 6 用 TDW-MAT 的一个真实 episode 串起整条流水线:(a) 主循环查缓存→选 plan(如 Explore→GoTo A→GoGrasp B→Transport);(b) 后台 updater 周期性发 LLM query;(c) 缓存表 column 对应 C、I、S,示例中一次 correction 把 “GoGrasp→Transport” 降权并把 metadata Steps 从 117 更新到 99。这张图是把前面抽象的 scoring / update 规则落到具体数字上。
实验
硬件:单机 RTX 4090 + Ryzen 9 7950X。Planner 用 GPT-5 / GPT-5-mini / GPT-5-nano(通过 OpenAI API,cost 按 2025-10 的 per-token 价格)。四个 benchmark(Table 1):CoELA@TDW-MAT(2 agent decentralized,LLM)、COMBO@TDW-COOK(2 agent,VLM)、COMBO@TDW-GAME(4 agent,VLM)、COHERENT@BEHAVIOR-1K(5 异构 agent centralized,graph 环境)。Warm-start prefill 分别用 4/2/1/4 训练 episode,评测用 44/18/9/36 episode。Baseline 三条:Synchronous(CoELA / COMBO / COHERENT 原版)、Parallelized Planning-Acting(Li et al. 2026)、Speculative Planning(Hua et al. 2025,GPT-5-nano 做 drafter,最多 3 步投机)。指标:SR、延迟(小时)、token 用量、美元成本。
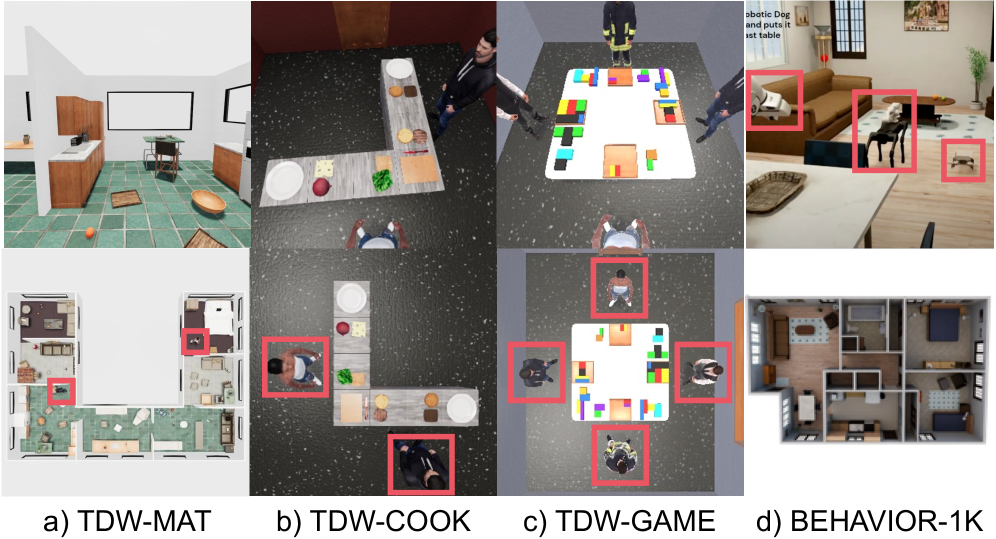
图 7 给出四个 benchmark 环境的画面快照(agent 用红框标出):前三个是 TDW 3D 场景里的 transport / cooking / puzzle 任务,最后一个 BEHAVIOR-1K 由 COHERENT 把仿真重表达为图结构并引入 arm / dog / quadrotor 三种异构机器人。这张图帮助理解为什么同一个方法要在 VLM 与 LLM、decentralized 与 centralized 之间都验证。
结果
GPT-5 × TDW-COOK(Table 2):baseline 12.86h / 3.3M token / $21.0 → AgenticCache+ 1.75h / 675K token / $4.4,延迟 7.4×、成本 4.8× 降幅,SR 100% vs 94.44%。GPT-5 × TDW-GAME:Parallel 成功率 0%、Speculative 11.11%,AgenticCache+ 100%,说明两条前作 baseline 在多 agent VLM 任务里基本崩掉。整体 12 个配置(4 benchmark × 3 模型):SR 平均 +22%、延迟 -65%、token -50%。Cold-start(Table 3/4,空缓存):TDW-MAT 上 GPT-5-nano SR 从 42.8% → 62.8%,GPT-5-mini 62.8%→69.4%;GPT-5 SR 微降 82.2%→80.6%,但延迟仍降 1.3–1.9×、成本降 1.4–1.8×。Ablation(Figure 9):static cache 仅 24% SR,加 cache update 提升 12%,加 plan replacement 提升 35%,两者组合达 70.7%。
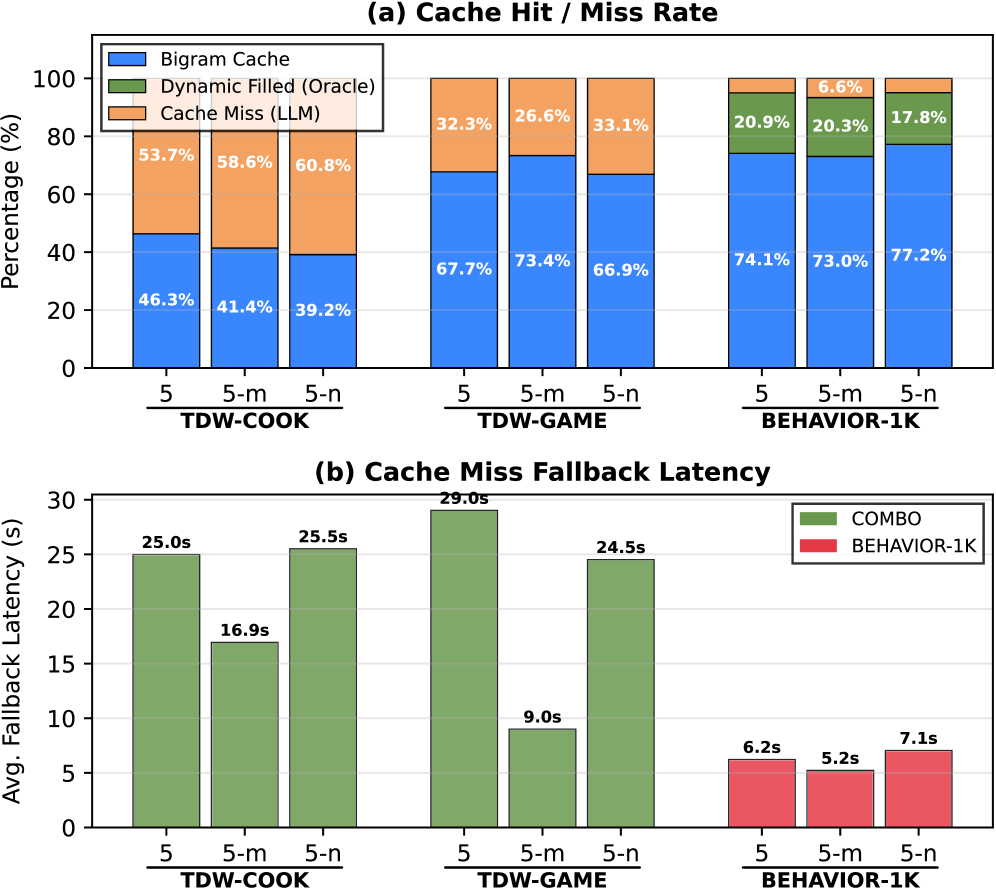
图 8(a) 给出 hit/miss 分布:bigram 缓存在 TDW-GAME 上 hit rate >66%、BEHAVIOR-1K ≥73%,而 TDW-COOK 因 plan 多样性降到 39–46%,剩余走 LLM fallback。图 8(b) 测 miss 时的 fallback 延迟:TDW 系列因 VLM 走图像通道要 9–29 s / 次,BEHAVIOR-1K 仅 5.2–7.1 s。这两张图量化了缓存收益和结构化程度正相关,同时指出高延迟场景下 miss 率必须压低。
缓存开销很小(Table 5):每个 agent 0.1–1.0 KB;(Table 6)GPT-5 下 transition 数从 0 增至 6000 步时的 13.7,1500 步后增速放缓,不会无限膨胀。对照标题口号:abstract 说"up to 86% latency reduction / 79% cost savings with GPT-5 on TDW-COOK",和 Table 2 的 12.86→1.75h(≈86.4%)、$21.0→$4.4(≈79.0%)一致。
结论
实践者的单一 takeaway:对 plan 转移规律性强的 embodied 任务,用 2-gram plan cache 替代逐步 LLM planning 能在几乎不掉 SR 的前提下把延迟砍 65%、token 砍 50%,最有说服力的单点证据是 GPT-5 × TDW-COOK 的 12.86h→1.75h(Table 2)。但边界要讲清楚:(1) 只在 4 个结构化多 agent benchmark(TDW 系 + BEHAVIOR-1K graph 版)和 GPT-5 家族 3 个 scale 上验证,abstract 没说但作者在 §6 自己承认开放式探索、创造性问题等 locality 弱的场景收益会缩水;(2) 长 horizon 多 agent 协同点(共享资源、rendezvous)会出现 correction 滞后,GPT-5 在长 horizon cold-start 下 SR 从 82.2% 降到 80.6% 就是这种症状;(3) 没有做跨 LLM 家族(Claude / Llama / Qwen)或本地部署 serving stack(vLLM / SGLang)上的 ablation,所以"cache 与现代 serving 互补"只是 abstract 的断言,不是实验结论。
是否新瓶装旧酒
论文在 §7 自己认领了三个最近亲:Agentic Plan Caching(Zhang et al. 2025b,存 plan 模板)、GPTCache / Semantic Cache(存 query-response 对),作者的 delta 是"不是 token/response 级缓存,而是 plan 级 2-gram 时序缓存,针对 embodied 的顺序依赖";另一亲缘是 speculative execution / branch prediction(Smith 1998、Yeh & Patt 1993、SpecInfer、Medusa),作者把 plan 当"粗粒度分支"做预测+投机执行,并借用 hybrid predictor 的 local+global 评分,这一点是诚实的工程迁移。独立判断:Agentic Plan Caching 已经做了 test-time plan 复用,本文的真 delta 是 「2-gram 顺序转移 + 异步 LLM 校验 + 即时 plan 替换」三件套而不是缓存本身的想法;如果只看"LLM agent 加缓存",不算首创。
尚未回答的问题
- 缺失 ablation:没有单独测 metadata range 过滤的贡献(去掉它缓存会退化成什么?);没有测不同 prefill 规模(1 vs 10 vs 100 episode)的敏感度;没有测 k(Updater 异步延迟步数)的选择。
- 缺失 scale:只有 GPT-5 家族,Claude、Llama、本地 7B 模型上 plan locality 还一样强吗?单机 RTX 4090 跑 GPT-5 via API,真实多机部署下这些 latency 数字会怎么变?
- 缺失 regime:结构化 manipulation / transport 之外,open-ended exploration、多模态对话 agent、web agent 这些 locality 较弱的场景没测,作者自己在 §6 也承认。
- Coordination 失败模式的定量分析缺失:作者说共享资源会 deadlock,但没给 deadlock 频率或修复延迟的数字。
- 3-gram / 层级子例程 能否补上 2-gram 抓不住的长依赖,作者在 future work 提了但没做。
原始摘要(中文翻译)
Embodied AI agent 越来越依赖大语言模型(LLM)来做规划,但每一步都调用 LLM 带来严重的延迟和成本开销。本文中,我们展示 embodied 任务表现出强烈的 plan locality——下一步的 plan 在很大程度上可以由当前 plan 预测出来。基于这一观察,我们提出 AgenticCache,一个通过复用缓存中的 plan 来避免逐步 LLM 调用的规划框架。在 AgenticCache 中,每个 agent 在运行时查询一个存储高频 plan 转移的缓存,同时一个后台的 Cache Updater 异步地调用 LLM 来校验并精炼缓存条目。在四个多 agent embodied benchmark 上,AgenticCache 在 12 个配置(4 benchmark × 3 模型)上平均将任务成功率提升 22%、把仿真延迟降低 65%、把 token 用量降低 50%。基于缓存的 plan 复用因而为构建低延迟、低成本的 embodied agent 提供了一条切实可行的路径。代码已在 https://github.com/hojoonleokim/MLSys26_AgenticCache 开源。
论文图表
图 1: Figure 1: Overview of AgenticCache. (a) Embodied AI agent framework. (b) Evaluation highlights on GPT-5.