arXiv: 2604.24039 · PDF
Authors: Hojoon Kim, Yuheng Wu, Thierry Tambe
Affiliations: Stanford University, Harvard University
Primary category: cs.LG · all: cs.AI, cs.CL, cs.LG
Matched keywords: large language model, llm, agent, agentic, multi-agent, rag, latency
TL;DR
AgenticCache caches 2-gram plan transitions for LLM-driven embodied agents, serving most planning decisions from a local cache while a background LLM updater asynchronously validates and corrects entries. Across 4 multi-agent benchmarks × 3 GPT-5 scales, it lifts success rate by 22% on average, cuts latency 65%, and reduces tokens 50%.
Motivation
LLM-powered embodied agents (CoELA, COMBO, COHERENT) invoke an LLM at every planning step, which dominates wall-clock time — Figure 2 shows over 70% of runtime across benchmarks is spent on LLM queries. Under a synchronous plan-act loop (Fig 3a), the agent stalls on each call. Prior asynchronous strategies don’t fix the root issue: parallelized planning-acting (Li 2026) overlaps plan and action but its prefetch goes stale when the environment shifts, and speculative planning (Hua 2025) pays heavy rollback cost when a small drafter is wrong in physical environments (e.g., undoing manipulations). Both still scale LLM cost linearly with trajectory length. The authors argue the missed opportunity is plan locality — after “go grasp target,” the next plan is “put into container” 59.7% of the time (Fig 4) — so most steps don’t need a fresh LLM call at all. The target users are operators running GPT-5-class models inside long-horizon multi-agent simulators (TDW, BEHAVIOR-1K), where a 10-hour TDW-COOK run at $21 per episode (GPT-5 baseline, Table 2) is painful.
Key Ideas
- Plan locality: 2-gram transitions between high-level plans are highly predictable; many plans have a small set of likely successors (Fig 4).
- Cache-as-planner: each agent stores ⟨Pᵢ → Pⱼ⟩ transitions with metadata ranges (step index, items held, sub-goals done, rooms visited) for feasibility filtering.
- Hybrid design: pure pattern-following hurts success (Fig 5), so an asynchronous LLM Cache Updater validates/corrects entries without blocking.
- Scoring: transition selected by S = C · I, where C is local transition count and I is global confirmation ratio N_conf/N_cand — analogous to hybrid branch predictors (Yeh & Patt 1993).
- Optional offline prefilling warms the cache from 1–4 successful GPT-5 trajectories per benchmark.
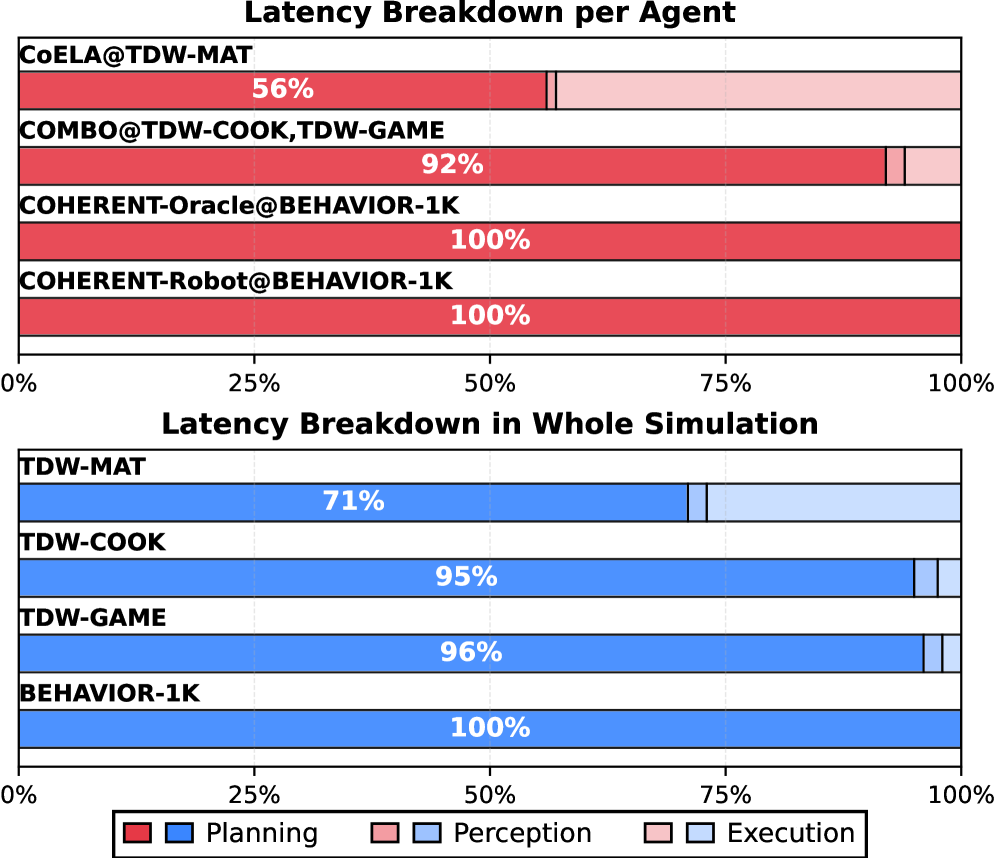
This latency breakdown motivates the whole framework: across all four benchmarks, >70% of per-step runtime is the LLM call itself, so any optimization that does not remove LLM calls will leave the dominant cost untouched. The chart compares several agent stacks on the same axes and shows LLM time dwarfing perception, action, and bookkeeping — the exact budget AgenticCache attacks by replacing per-step invocations with cache lookups.
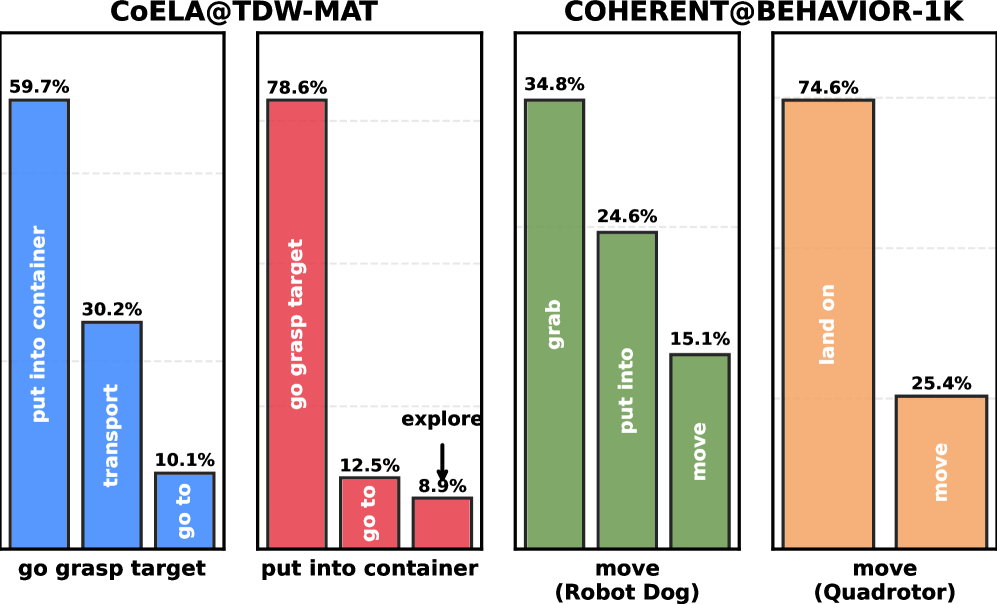
The 2-gram distribution over GPT-5 execution trajectories is the empirical claim underlying cache viability. The paper gives one concrete data point: after “go grasp target,” the successor is “put into container” in 59.7% of cases. Bars for other predecessor plans similarly concentrate on one or two successors, confirming plan locality is strong enough that a small cache could cover most decisions.
Method
Each agent owns a small table of 2-gram entries ⟨Pᵢ→Pⱼ⟩ annotated with per-field min/max metadata ranges. At runtime: (1) query with previous plan + current state, (2) filter entries whose metadata range excludes the current state, (3) pick argmax S = C(Pᵢ→Pⱼ) · I(Pⱼ). The asynchronous Cache Updater periodically calls the LLM with context c_t and active plan p_t; after a k-step delay the response p′_{t+k} is compared to the executed trajectory. If it appears in the trajectory → confirmation (bump C and N_conf). Otherwise → correction: add/update the new transition, decrement the mispredicted one, and immediately replace the ongoing plan if executable. Query control suppresses redundant calls during confirmation and correction windows. Cache miss pauses planning and falls back to an LLM call whose result seeds a new entry.
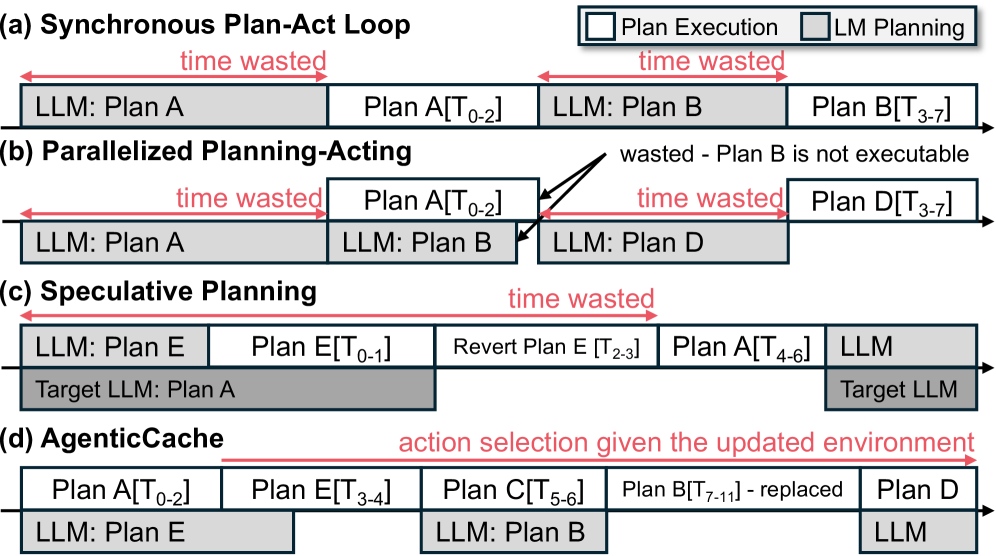
Figure 3 places AgenticCache (d) against three strategies (synchronous, parallelized, speculative). The timing diagrams show how the synchronous loop blocks on every LLM call, the parallelized variant overlaps calls but rolls back on stale plans, speculative planning pays undo cost on wrong drafts, while AgenticCache serves most steps from the cache and piggybacks LLM validation in the background — this is the visual argument for why the update/correction protocol in §4.2 avoids both stalling and rollback.
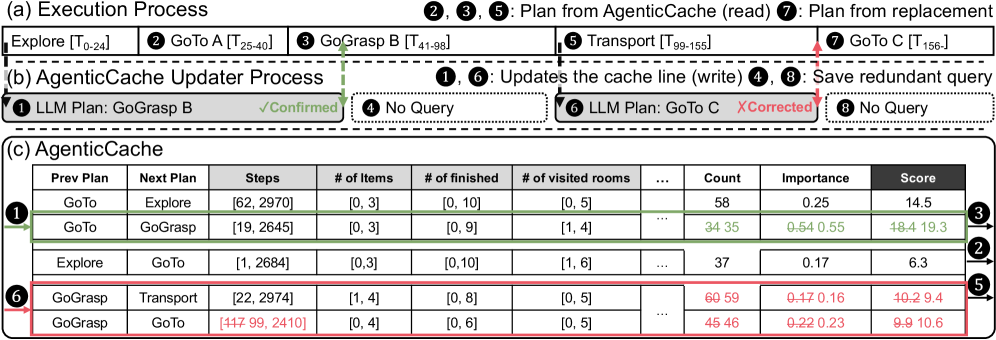
Figure 6 walks a concrete TDW-MAT episode through the mechanics of §4.1–4.2: cache entry table with Count/Importance/Score columns, a runtime query selecting GoGrasp B, a subsequent LLM confirmation bumping the transition’s counts, and later a correction swapping “GoGrasp → Transport” for “GoTo C” with metadata (Steps 117 → 99) rewritten. This is the worked example showing how the scoring formula and the confirmation/correction/suppression logic actually touch cache state.
Experiments
- Platform: single RTX 4090 + Ryzen 9 7950X workstation; LLMs are GPT-5, GPT-5-mini, GPT-5-nano via OpenAI API (cost priced at Oct 2025 rates).
- Benchmarks (Table 1, Fig 7): CoELA@TDW-MAT (2-agent transport, 44 eval episodes), COMBO@TDW-COOK (2-agent cooking, 18 eps), COMBO@TDW-GAME (4-agent puzzle, 9 eps), COHERENT@BEHAVIOR-1K (5 heterogeneous robots on graph, 36 eps).
- Prefilling: 4/2/1/4 disjoint training episodes respectively.
- Baselines: Synchronous (CoELA/COMBO/COHERENT with ReCA planning-then-comm), Parallelized Planning-Acting (Li 2026), Speculative Planning (Hua 2025, GPT-5-nano drafter + GPT-5/mini verifier, depth 3).
- Metrics: task success rate (SR), latency (hours), tokens, USD cost.
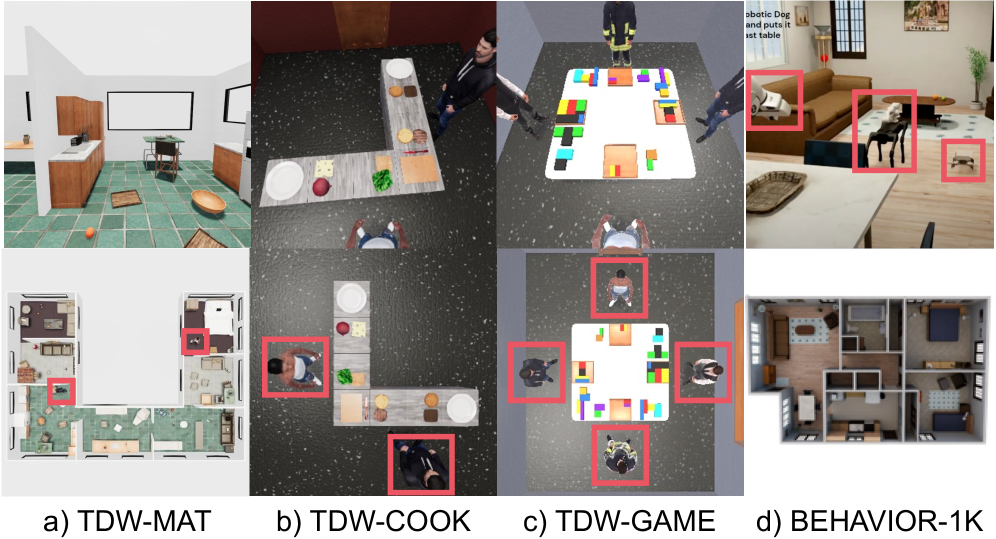
Snapshots of the four benchmark environments ground the scale of the evaluation — heterogeneous tasks ranging from 2-agent TDW manipulation and cooking to 4-agent puzzle assembly and 5-robot household BEHAVIOR-1K graphs. Figure 7 is used to visually justify that “plan locality” is being tested across meaningfully different coordination modes, not just one TDW variant.
Results
Headline numbers from Table 2 (warm-start “Ours+”):
- TDW-COOK, GPT-5: latency 12.86 h → 1.75 h (7.4×), cost $21.0 → $4.4 (4.8×), SR 94.4% → 100%.
- TDW-GAME, GPT-5: parallel planning collapses to 0% SR and speculative to 11.1%, while AgenticCache holds 100% SR at 1.11 h vs 7.88 h baseline.
- TDW-MAT, GPT-5: latency 41.34 h → 22.27 h, tokens 5.8M → 4.1M, but SR 90.2% → 88.6% (a slight drop the authors acknowledge).
- Aggregate (12 configs): 22% avg SR improvement, 65% latency reduction, 50% token reduction (matches abstract).
- Cold start (no prefill, Tables 3–4): on long-horizon tasks, AgenticCache improves GPT-5-nano SR from 42.8% → 62.8% and GPT-5-mini from 62.8% → 69.4%, while GPT-5 drops 82.2% → 80.6% — authors attribute the GPT-5 regression to stale transitions and multi-agent coordination conflicts over long episodes.
- Cache cost (Tables 5–6): per-agent footprint 0.1–1.0 KB; transitions saturate around ~13–14 entries by 6000 steps, so no unbounded growth.
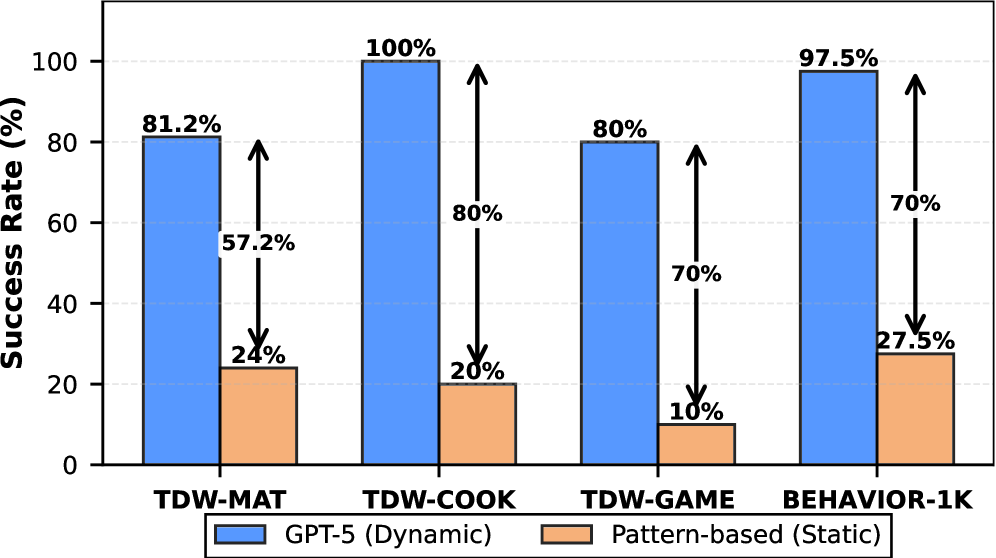
- Ablation (Fig 9): static cache 24% SR; +cache updates → +12%; +plan replacement → +35%; full system 70.7% — the two mechanisms are complementary, not redundant.
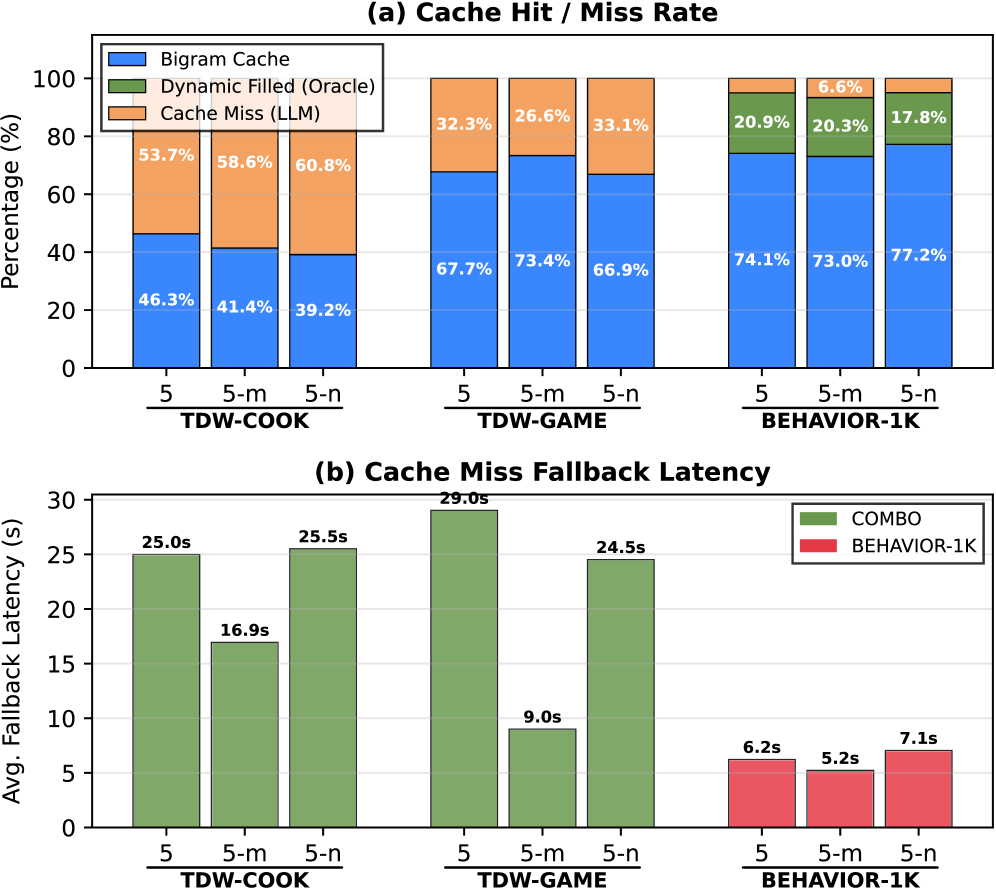
Figure 8 supports the hit-rate and fallback-latency claims of §5.5. Panel (a): the bigram cache hits >66% on TDW-GAME and ≥73% on BEHAVIOR-1K but falls to 39–46% on TDW-COOK (more plan diversity). Panel (b): on a miss, TDW-based tasks pay 9–29 s per fallback due to VLM overhead while BEHAVIOR-1K stays at 5.2–7.1 s. Together these explain why structured environments get the largest speedups, and why minimizing miss frequency is the key lever in latency-sensitive settings.
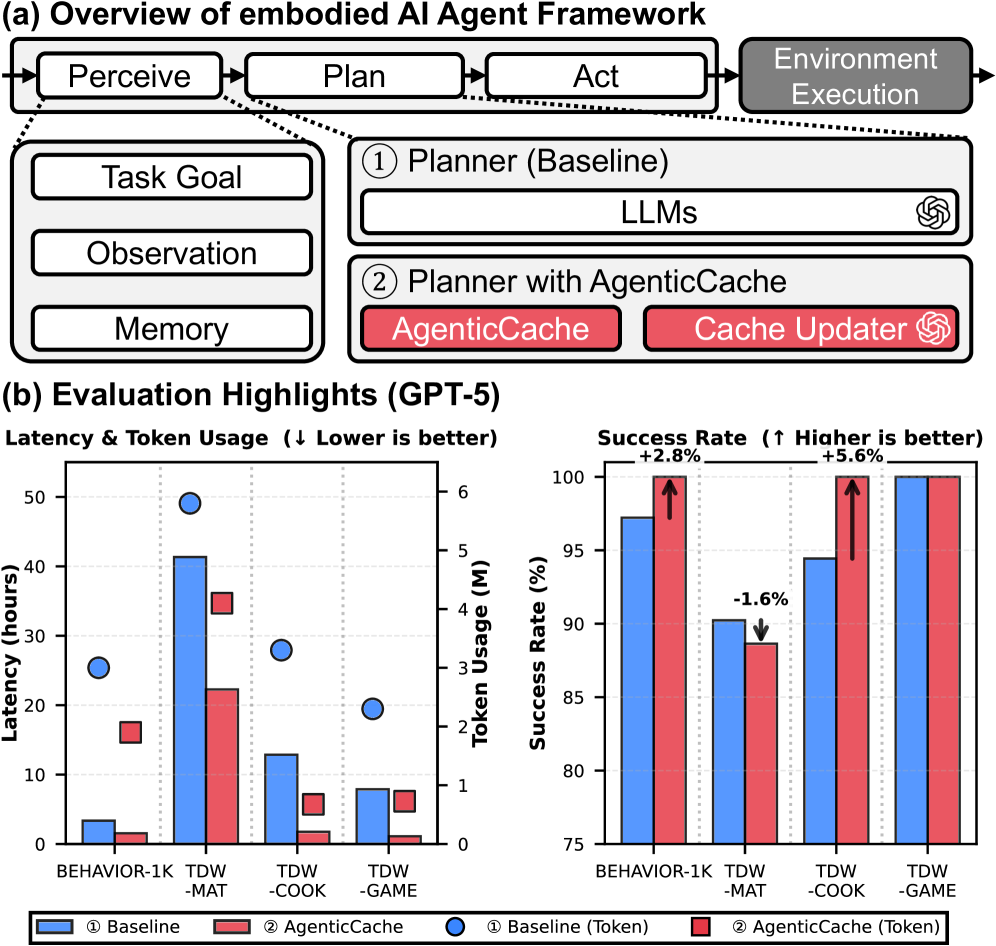
Figure 1(a) shows the cache-plus-updater sitting beside the perceive-plan-act loop — the architecture the method section formalizes. Panel (b) reports the paper’s top-line marketing numbers on GPT-5: up to 86% latency reduction and 79% cost savings on TDW-COOK with a 97% average task success rate across the four benchmarks. These match the abstract’s aggregate claims and Table 2’s TDW-COOK row (12.86 → 1.75 h = 86.4% latency reduction).
Conclusion
A practitioner should take away that, for embodied agent stacks whose per-step planner is an expensive LLM call, replacing most of those calls with a 2-gram transition cache governed by an asynchronous LLM updater cuts latency by ~65% and cost by ~50% without tanking success rate — Table 2’s 7.4× latency and 4.8× cost drop on TDW-COOK (GPT-5) is the single best-supported number. Limits: every experiment uses GPT-5 family models via OpenAI API, on structured TDW/BEHAVIOR-1K tasks with strong plan locality; authors explicitly flag that free-form or creative domains would likely have lower hit rates. Cold-start GPT-5 regresses slightly on long-horizon SR (82.2% → 80.6%), and Fig 10’s plan-execution accuracy only reaches ~0.52 for GPT-5 — high SR is sustained despite moderate plan-match accuracy, which is a load-bearing caveat the authors acknowledge. Multi-agent coordination failures at shared resources are called out as an open failure mode.
Novelty Check
The authors position against three neighbors: Agentic Plan Caching (Zhang 2025b) — stores reusable plan templates; AgenticCache frames its delta as caching sequential 2-gram transitions rather than whole templates, with online updates. GPTCache / Semantic Cache (Bang 2023; Dar 1996) — response-level exact/similar-query cache, different granularity. Speculative Planning (Hua 2025) and Parallelized Planning-Acting (Li 2026) — still per-step LLM calls, which AgenticCache avoids. The authors also explicitly borrow the C·I scoring from hybrid branch predictors (Yeh & Patt 1993; Smith 1998), which is an honest acknowledgment. Independent view: the combination of bigram transition cache + async LLM validator + immediate plan swap does look novel for embodied agents specifically; I’m not aware of a tighter prior. MemGPT is correctly cited as a conversational-memory analogue, not a direct prior. Not a relabel — genuine systems contribution, though the underlying intuition (plan locality + speculative execution) is clearly borrowed from computer architecture, as the paper itself states.
Open Questions
- Does the benefit hold beyond GPT-5 family (e.g., Claude, local Llama) where per-step latency and failure modes differ?
- How does AgenticCache degrade as plan locality weakens — is there a quantitative locality threshold below which the cache hurts?
- The GPT-5 cold-start SR regression on long-horizon tasks (82.2% → 80.6%) — which specific coordination conflicts cause it, and do 3-gram or hierarchical caches (listed as future work) actually close the gap?
- How does the 50% token-savings number split between cache hits and the suppressed validation queries? The paper doesn’t isolate these.
- Memory dynamics are shown up to ~6000 steps; behavior across hundreds of episodes of lifelong deployment (the paper’s own “lifelong adaptation” framing) is not measured.
Figures
Figure 1: Figure 5: Pattern-based agents exploit plan locality but suffer large performance gaps without context-aware updates.
Original abstract
Embodied AI agents increasingly rely on large language models (LLMs) for planning, yet per-step LLM calls impose severe latency and cost. In this paper, we show that embodied tasks exhibit strong plan locality, where the next plan is largely predictable from the current one. Building on this, we introduce AgenticCache, a planning framework that reuses cached plans to avoid per-step LLM calls. In AgenticCache, each agent queries a runtime cache of frequent plan transitions, while a background Cache Updater asynchronously calls the LLM to validate and refine cached entries. Across four multi-agent embodied benchmarks, AgenticCache improves task success rate by 22% on average across 12 configurations (4 benchmarks x 3 models), reduces simulation latency by 65%, and lowers token usage by 50%. Cache-based plan reuse thus offers a practical path to low-latency, low-cost embodied agents. Code is available at https://github.com/hojoonleokim/MLSys26_AgenticCache.