arXiv: 2602.00994 · PDF
作者: Yu Li, Mingyang Yi, Xiuyu Li, Ju Fan, Fuxin Jiang, Binbin Chen, Peng Li, Jie Song, Tieying Zhang
单位: School of Information, Renmin University of China, Bytedance Inc
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, agent, agentic, tool use, tool-use, retrieval, reasoning
TL;DR
本文发现 Agentic RL 中推理能力与工具调用能力存在梯度干扰,并提出 DART——用两个独立 LoRA adapter 解耦两类梯度——在 13 个 benchmark 上超越所有联合优化 baseline,逼近双模型上界。
Motivation
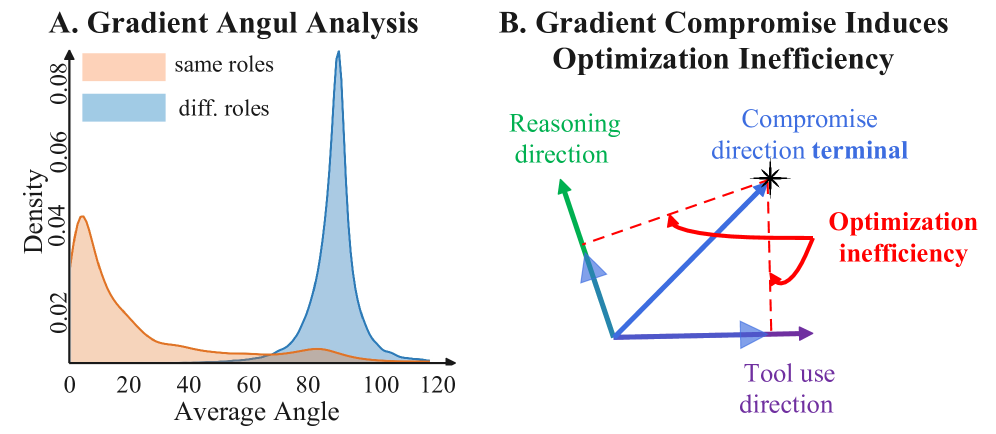
当前 Agentic RL(ARL)的主流做法是用一套共享参数同时学习"链式推理"和"外部工具调用"两种行为,默认两者可以在同一参数空间中和谐共存。这一假设从未经过系统的实证检验。问题的关键在于:推理 token(思考步骤)和工具调用 token(search/API 调用)在 RL 训练时会产生方向接近正交的梯度,混合后的参数更新是两者的折中,对任何一方都是次优的。
实际受害者是今天所有在 Search-R1、ToolBench 类框架上做 ARL post-training 的团队:他们用单模型联合优化,却不知道推理和工具调用在"争抢"同一批 LoRA 参数。现有 workaround 仅有"多 LoRA + soft router"(MoLoRA 等 MoE 范式),但这类方法每个 token 的梯度依然流向所有 adapter,本质上没解决干扰问题。作者认为,LoRA adapter 的普及让"将两种能力路由到不同低秩矩阵"变得参数高效且工程可行,这是现在做这件事的前提条件。
核心观点
-
提出 CEA(Capability Effect Attribution):通过梯度掩码构造六种受控模型变体,对每道题独立求解交互系数 $\lambda_{23}^q$,量化推理与工具调用之间的正/负交互效应。
-
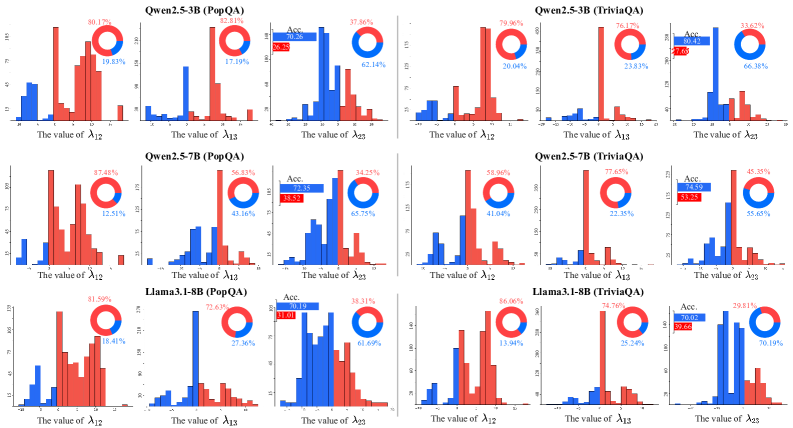
实证发现负交互:$\lambda_{23}^q$ 在多个数据集、多种模型规模和架构下均以负值为主(Fig. 2、Fig. 7),证明联合优化导致两类能力相互抑制。
-
梯度视角解释根因:推理 token 与工具调用 token 的梯度方向近乎正交(Fig. 3),联合更新等于沿折中方向走,两种能力均受损。
以下图展示了 CEA 的整体流程:六种模型变体填充设计矩阵,求解后得到每题的交互系数向量;$\lambda_{23}<0$ 即表明存在干扰。

-
提出 DART:冻结 backbone,为推理和工具调用各加一个独立 LoRA adapter,用确定性 token 级路由器(以
<search>等 sentinel token 触发)将梯度硬路由到各自参数子空间,彻底消除共享参数的竞争。 -
干扰是 capacity 问题还是 misalignment 问题:同等参数量的单个 LoRA 与 Search-R1 表现相当,DART 的提升来自梯度解耦而非参数增加(Fig. 6)。
-
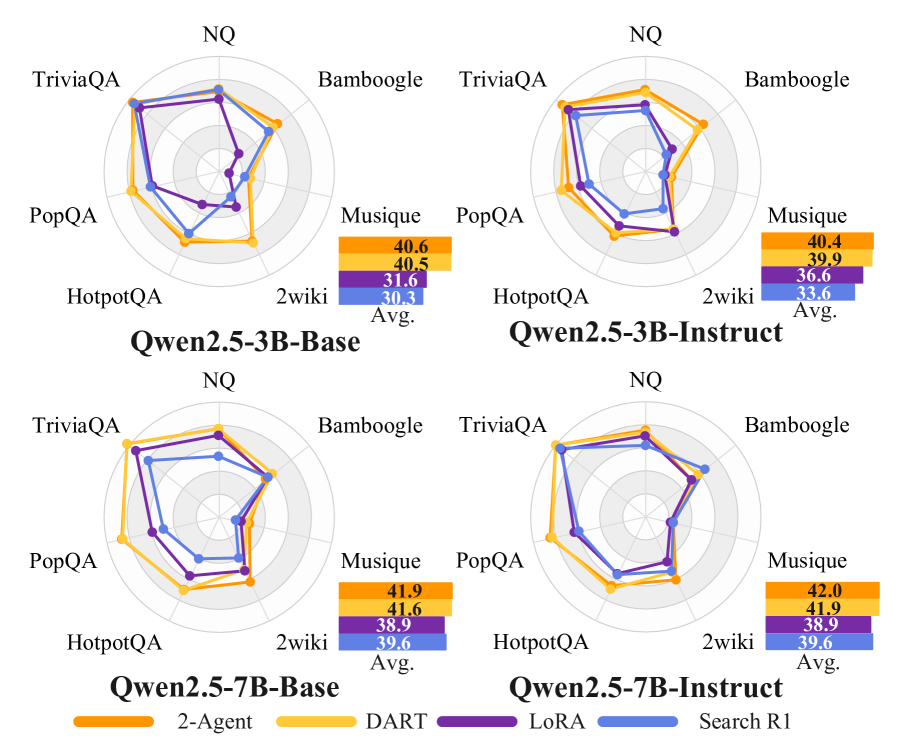
在 13 个 benchmark(7 QA + 6 NL2SQL)上,DART 超越所有联合优化 baseline,接近"两个专用模型"的上界。
方法
CEA 诊断框架:定义三个二值能力指标(base/tool-use/reasoning)及其两两交互项,共 6 维系数向量 $\boldsymbol{\lambda}^q$。通过构造恰好六种能力组合的模型,以 logit 变换将期望正确率转为线性方程组 $\mathbf{z}^q = \mathbf{X}\boldsymbol{\lambda}^q$,逐题求解得到交互系数 $\lambda_{23}^q$,负值即为干扰信号。六种变体通过两种手段生成:(1)梯度掩码——在 GRPO 策略梯度中对推理或工具调用 token 的贡献置零,产生纯推理模型、纯工具模型、联合模型等;(2)混合推理(inference-derived)——在推断时将两个独立训练的专用模型拼接使用,实现无参数交互的能力组合,补全设计矩阵缺少的两个变体。
下图中,推理 token 与工具调用 token 的梯度夹角分布(在 Qwen2.5-3B/NQ 上)显示,同类梯度高度对齐,异类梯度接近正交——这直接解释了联合更新为何会走折中方向。
DART:冻结 pretrained backbone $W$,挂载两个互斥的 LoRA adapter($\Delta W_r$ 用于推理,$\Delta W_a$ 用于工具调用),分别附着在所有线性层上。Token 路由完全确定性:遇到 <search> 等 sentinel token 即切入工具调用 LoRA,否则走推理 LoRA。前向计算:$\mathbf{h}_t’ = W\mathbf{h}t + \Delta W{\ell(t)}\mathbf{h}_t$,反向时梯度只更新对应 adapter,两套参数无交叉。
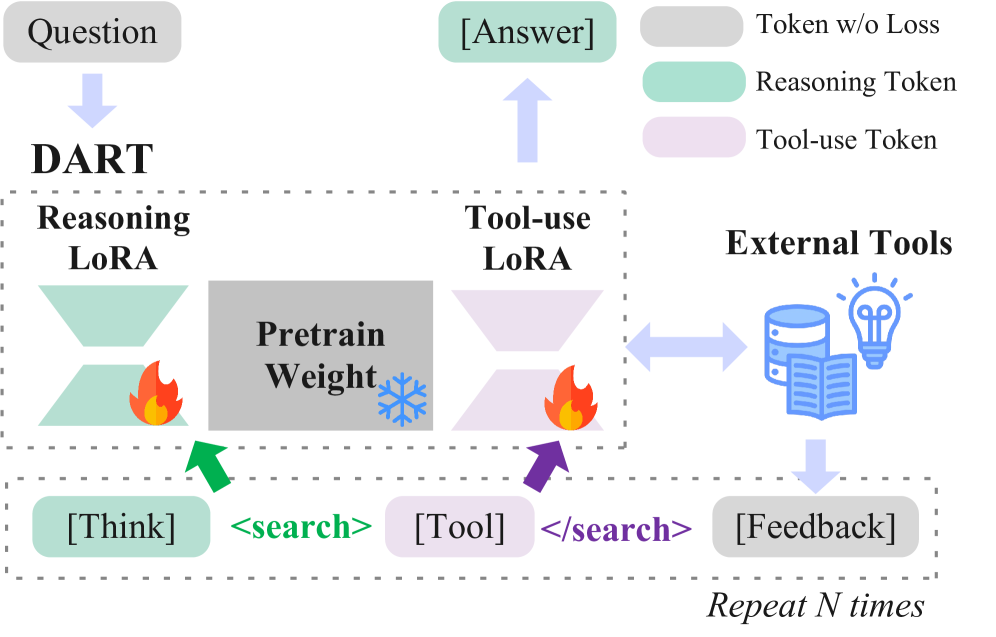
如 Fig. 4 所示,DART 的核心约束是"硬路由"而非软混合——这与 MoLoRA 等方法的根本区别在于梯度完全不共享,而非仅权重隔离。
实验
任务与数据集:
- Retrieval-Augmented QA(7 个 benchmark):NQ、HotpotQA、PopQA、TriviaQA 等
- Multi-Turn NL2SQL(6 个 benchmark)
Baseline:Search-R1(代表性 ARL 联合优化方法)、多种 multi-LoRA soft-routing 方法
模型规模:Qwen2.5-3B、Qwen2.5-7B、Llama3.1-8B
CEA 分析规模:每个数据集取前 1000 条测试样本,跨三种模型架构验证干扰的普遍性
结果
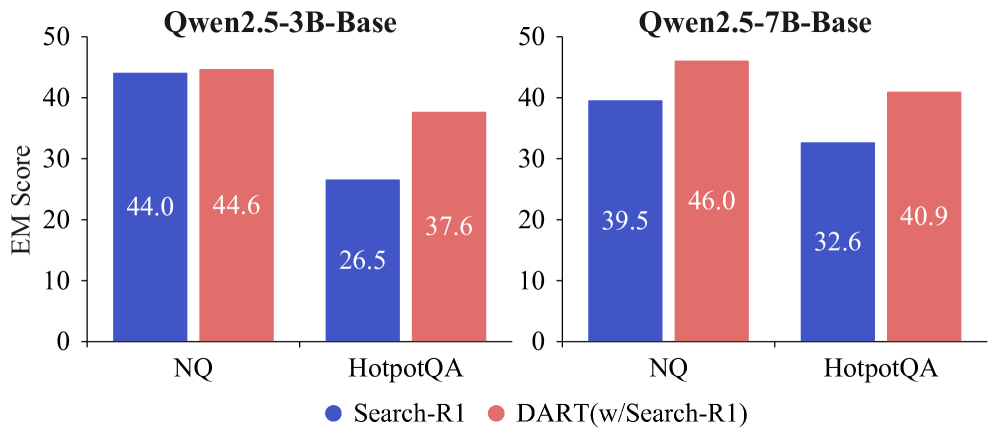
推理能力提升(Fig. 5):固定相同检索上下文后,DART 在 NQ 和 HotpotQA 上 EM 均高于 Search-R1,证明联合优化确实损害了推理学习,DART 通过解耦恢复了推理能力(具体 EM 绝对值论文正文截断处未给出,Fig. 5 给出的是定性比较)。
干扰的普遍性(Fig. 2、Fig. 7):$\lambda_{23}^q$ 在 NQ/HotpotQA/PopQA/TriviaQA 四个数据集、Qwen2.5-3B/7B 和 Llama3.1-8B 三种架构上均以负值为主(Fig. 7),蓝色负值区间占主导,而 $\lambda_{12}^q$(base–reasoning)和 $\lambda_{13}^q$(base–tool)则以正值为主,表明干扰特异性地出现在推理与工具调用之间。
下图 Fig. 2 展示了这一发现的汇总:对同一模型,base–reasoning 和 base–tool 交互系数为正(协同),而 reasoning–tool-use 交互系数 $\lambda_{23}^q$ 分布偏负(干扰)。

参数 capacity 消融(Fig. 6):将 DART 的两个 LoRA 合并为等总 rank 的单个 LoRA,结果与 Search-R1 相当,说明 DART 的收益来自梯度解耦而非参数量增加;DART 的性能曲线跨模型规模和 benchmark 均接近"2-Agent 上界"(两个模型各自专注一种能力)。
结论
核心 takeaway:ARL 联合训练中推理与工具调用的梯度正交性是一个可量化、可缓解的系统性瓶颈;用两个独立 LoRA 做硬路由解耦梯度这一"简单改动"在 13 个 benchmark 上即可逼近双模型上界。这意味着现有所有共享参数的 ARL 框架(Search-R1 等)可能存在系统性的能力互压问题,值得在部署前重新审视。
边界:实验仅在推理+单种工具(检索或 SQL)的两能力场景下验证;更多工具类型的多能力扩展(例如推理+代码执行+搜索)是否线性可扩展未经验证。规模限制在 3B–8B 参数范围,70B+ 模型的干扰强度和 DART 收益待确认。NL2SQL 属结构化输出任务,工具调用 token 边界清晰;在工具边界模糊的 open-domain agent 场景中,sentinel token 路由的有效性需另行验证。
缺失 ablation:LoRA rank 分配的灵敏度(附录 G 提及但正文截断)、不同 ARL 算法(非 GRPO)下干扰是否同样存在、以及 DART 在超过两种能力时的扩展方案,论文均未给出完整结论。
是否新瓶装旧酒
作者自述最相近工作(Related Work §2):
- Multi-LoRA / MoE-LoRA(MoLoRA、LoRAMoE 等):作者明确区分——这些方法使用 soft router,每个 token 梯度流向所有 adapter,目标是增加 capacity 或跨域迁移,而非消除同任务内的能力干扰;DART 使用确定性硬路由,梯度完全隔离。
- 跨域优化干扰(Ye et al. 2026、Yuan et al. 2026):跨域干扰已有研究,但同一 agentic 任务内部推理与工具调用之间的干扰此前未被检验,是作者声称的 gap。
独立判断:DART 的结构(冻结 backbone + 两路 LoRA + 硬 token 路由)在形式上与 Mixture-of-LoRA 高度相似,区别确实主要在"硬路由"这一约束。CEA 诊断框架的设计是工作中更有原创性的部分,将联合优化的隐式代价量化为可测系数。整体不属于换名,但 DART 方法侧的 delta 相对窄,核心贡献更多在诊断框架和对"硬路由必要性"的实证论证上。
尚未回答的问题
- 超过两种能力时如何扩展:当 agent 同时需要检索、代码执行、计算器调用等多种工具时,是否每种能力都需要独立 LoRA?adapter 数量与干扰程度的关系未建立。
- 缺失更大规模验证:所有实验在 3B–8B 范围内,70B 模型是否存在同等程度的梯度正交性未知。
- LoRA rank 分配:两个 adapter 如何最优分配 rank(推理 vs 工具调用的 rank 比例)的 ablation 仅在附录 G 中提及,正文未给出充分结论。
- online RL vs offline SFT 下的差异:CEA 的梯度分析基于 RL 训练;SFT 场景下是否同样存在干扰,以及 DART 在 SFT 上的增益未报告。
- Sentinel token 依赖:DART 的路由完全依赖
<search>等特殊 token;对于不使用固定格式 tool-call 边界的 agent(如 function-calling 格式多样的场景),路由机制的鲁棒性未测试。
原始摘要(中文翻译)
Agentic 强化学习(ARL)训练大型语言模型将推理与外部工具调用交替执行,以解决复杂任务。现有大多数 ARL 方法用单套参数同时支持推理和工具调用行为,隐式地假设联合训练可以提升整体 agent 性能。尽管这一做法被广泛采用,该假设却鲜有实证检验。本文通过引入能力效果归因(CEA)系统性地检验这一假设,提供了推理与工具调用行为之间存在干扰的定量证据。通过深入分析,我们发现这两种能力往往会诱发方向不一致的梯度,导致训练干扰,削弱联合优化的有效性,并对主流 ARL 范式提出挑战。为解决这一问题,我们提出解耦动作-推理调优(DART),这是一个简单高效的框架,通过独立的低秩适配模块显式解耦推理和工具调用的参数更新。仅凭这一简单改动,DART 在检索增强 QA 和 NL2SQL 的十三个 benchmark 上超越了所有联合优化 baseline,并接近双模型上界,进一步印证了共享优化下存在能力干扰的发现。