arXiv: 2602.00994 · PDF
Authors: Yu Li, Mingyang Yi, Xiuyu Li, Ju Fan, Fuxin Jiang, Binbin Chen, Peng Li, Jie Song, Tieying Zhang
Affiliations: School of Information, Renmin University of China, Bytedance Inc
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, agent, agentic, tool use, tool-use, retrieval, reasoning
TL;DR
在 Agentic RL 中,推理(reasoning)与工具调用(tool-use)共享参数会产生梯度方向冲突,导致联合优化效果下降。作者量化了这一干扰,并提出 DART——用两个独立 LoRA 适配器分别承接两类梯度——在 13 个 benchmark 上超越所有联合优化基线。
Motivation
现有 Agentic RL(ARL)方法普遍假设:在单一共享参数集上联合优化推理与工具调用可以同时提升两类能力。这一假设被广泛采用,却极少受到实证检验。问题的核心在于:推理 token(如链式思维)与工具调用 token(如 <search> 之后的 API 参数)在语义性质、统计分布和所需的参数更新方向上均存在本质差异。当两类梯度被聚合施加于同一参数时,方向上的冲突(近似正交)迫使优化器走向折中更新,对两类能力都是次优的。受到跨域多任务干扰的已有研究启发(Ye et al. 2026; Yuan et al. 2026),但单一 Agentic 任务内部不同 capability 之间是否也存在干扰,此前无人系统研究。既有 Multi-LoRA 方法(MoE 软路由)旨在扩大容量或跨域迁移,并未解决梯度干扰;其软路由仍让每个 token 的梯度流过多个适配器,本质上并未切断干扰路径。
Key Ideas
-
CEA(Capability Effect Attribution):通过构造六个受控模型变体,逐问题求解交互系数 $\lambda_{23}^q$,$\lambda_{23}^q < 0$ 即表明推理与工具调用之间存在干扰。
-
梯度不对齐(Gradient Misalignment):同类 token 的梯度方向高度一致,而推理 token 与工具调用 token 的梯度方向近似正交,导致联合更新成为折中方向。
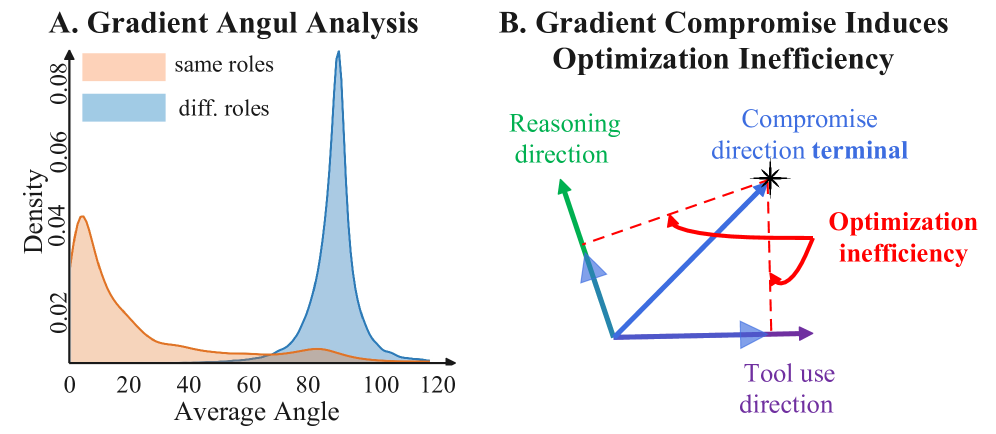 在 Qwen2.5-3B + NQ 任务下,同类 token 梯度夹角集中在小角度区域,而推理与工具调用 token 的梯度几乎正交(分布峰值接近 90°)。这一不对齐直接使合并后的更新方向(图 B 中的黄色箭头)偏离两个能力各自所需的最优方向,从而量化解释了 CEA 揭示的负向交互。
在 Qwen2.5-3B + NQ 任务下,同类 token 梯度夹角集中在小角度区域,而推理与工具调用 token 的梯度几乎正交(分布峰值接近 90°)。这一不对齐直接使合并后的更新方向(图 B 中的黄色箭头)偏离两个能力各自所需的最优方向,从而量化解释了 CEA 揭示的负向交互。
-
DART(Disentangled Action-Reasoning Tuning):冻结预训练主干,为推理和工具调用分别配备一个独立 LoRA 适配器,由确定性硬路由器将每个 token 精确导向对应适配器。
-
实验验证双向:DART 在 13 个 benchmark(7 个 QA + 6 个 NL2SQL)上超越全部联合优化基线;消融表明增益来自梯度解耦而非参数量增加。
Method
CEA 框架(§4)利用梯度掩码和混合推理构造六个受控变体,在 6 维能力向量空间中建立线性方程组,通过 logit 变换后直接求解每道问题的 $\boldsymbol{\lambda}^q$。六个变体包括:基础预训练模型、仅工具调用训练模型、仅推理训练模型、联合训练模型,以及两个推理时组合模型(不同参数的模型在推理时依 token 类型切换)。
 CEA 分四个模块:(A) 推理时组合——不同 token 在推理期被路由至各自独立训练的模型;(B) 设计矩阵——六个变体的能力指示向量构成满秩矩阵,求解得 $\boldsymbol{\lambda}^q$,$\lambda_{23}^q < 0$ 即标志干扰;(C) token 级梯度掩码——二值掩码门控每个 token 对梯度的贡献;(D) 训练导出变体——在共享基础模型上应用不同掩码得到专项模型。
CEA 分四个模块:(A) 推理时组合——不同 token 在推理期被路由至各自独立训练的模型;(B) 设计矩阵——六个变体的能力指示向量构成满秩矩阵,求解得 $\boldsymbol{\lambda}^q$,$\lambda_{23}^q < 0$ 即标志干扰;(C) token 级梯度掩码——二值掩码门控每个 token 对梯度的贡献;(D) 训练导出变体——在共享基础模型上应用不同掩码得到专项模型。
DART(§5)在冻结主干之上挂载两个不相交的 LoRA 适配器(分别作用于所有线性层),由确定性硬路由函数 $\ell(t)$ 决定每个 token 流入哪个适配器:遇到 <search> 等哨兵 token 则激活工具调用适配器,否则激活推理适配器。
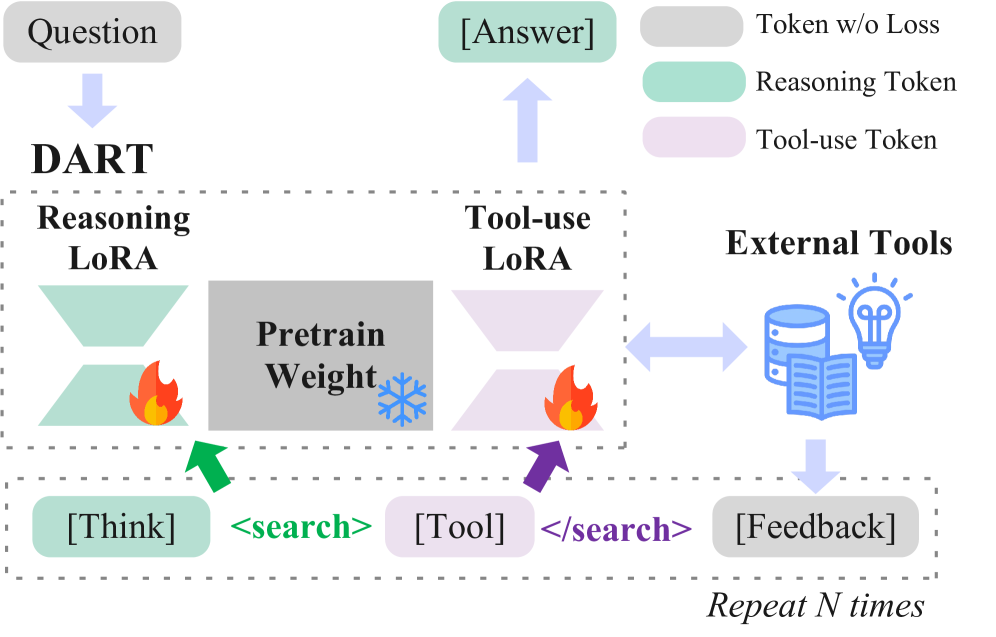 DART 架构图清晰展示了"一个冻结主干 + 两条独立 LoRA 路径"的设计:推理 token 和工具调用 token 各走专属适配器,梯度在参数层面完全隔离,避免了正交更新方向相互抵消的问题。
DART 架构图清晰展示了"一个冻结主干 + 两条独立 LoRA 路径"的设计:推理 token 和工具调用 token 各走专属适配器,梯度在参数层面完全隔离,避免了正交更新方向相互抵消的问题。
Experiments
- 任务一:Retrieval-Augmented QA,数据集包括 NQ、HotpotQA、PopQA、TriviaQA;基线:Search-R1 及其他联合优化方法;模型规模:Qwen2.5-3B、Qwen2.5-7B、Llama3.1-8B。
- 任务二:Multi-Turn NL2SQL,6 个 NL2SQL benchmark;同一系列基线。
- CEA 分析:使用上述模型和数据集的前 1000 个测试样本(§D.4 附录)。
- 消融:对比单 LoRA(相同总 rank)、DART、2-Agent 上界(两个独立完整模型)。
- 硬件:论文正文未明确列出具体 GPU 配置。
Results
主要发现(1)——CEA 揭示负向交互:
 在 NQ 上 Qwen2.5-3B 的 per-question 分布中,$\lambda_{12}^q$(base–reasoning)和 $\lambda_{13}^q$(base–tool)均以正值为主(蓝色占比少),而 $\lambda_{23}^q$(reasoning–tool 交互)分布以负值(蓝色)为主,证明推理与工具调用在联合优化下确实相互干扰。
在 NQ 上 Qwen2.5-3B 的 per-question 分布中,$\lambda_{12}^q$(base–reasoning)和 $\lambda_{13}^q$(base–tool)均以正值为主(蓝色占比少),而 $\lambda_{23}^q$(reasoning–tool 交互)分布以负值(蓝色)为主,证明推理与工具调用在联合优化下确实相互干扰。
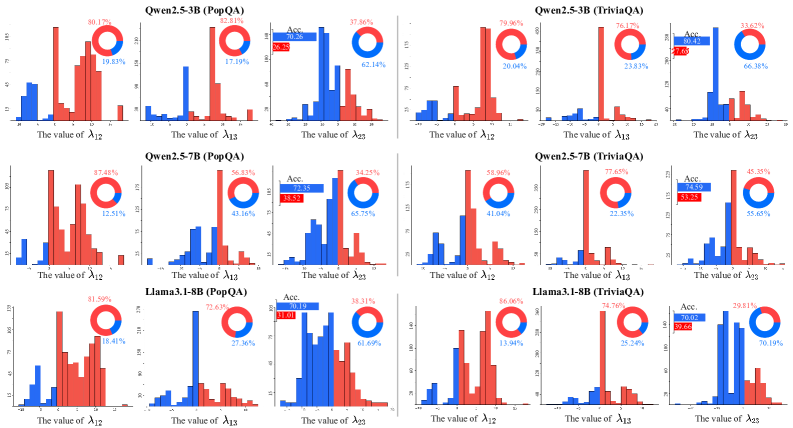 将 CEA 扩展至 PopQA、TriviaQA,以及 Qwen2.5-3B、Qwen2.5-7B、Llama3.1-8B,$\lambda_{23}^q$ 在所有数据集–模型组合中始终以负值为主(Fig. 7),表明推理–工具调用干扰具有跨数据集、跨模型规模、跨架构的普遍性。
将 CEA 扩展至 PopQA、TriviaQA,以及 Qwen2.5-3B、Qwen2.5-7B、Llama3.1-8B,$\lambda_{23}^q$ 在所有数据集–模型组合中始终以负值为主(Fig. 7),表明推理–工具调用干扰具有跨数据集、跨模型规模、跨架构的普遍性。
主要发现(2)——DART 在固定检索上下文下的推理能力:
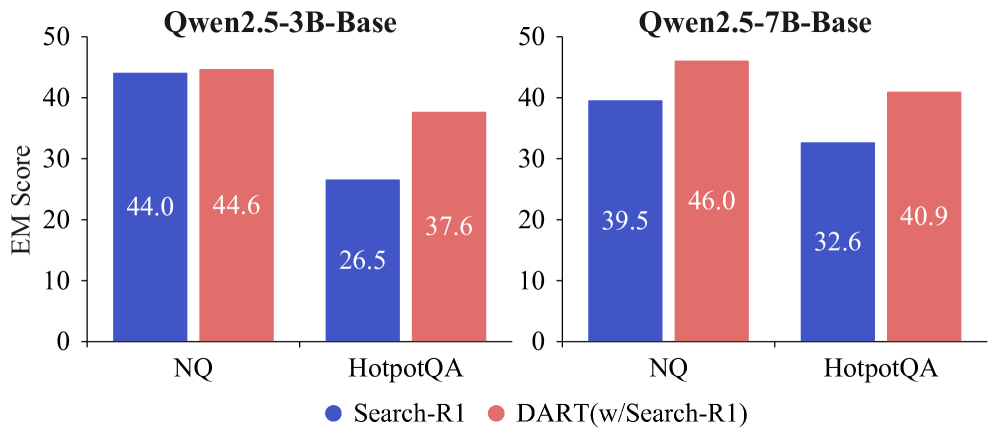 在固定检索上下文(相同 retrieved evidence)下,DART 在 NQ 和 HotpotQA 上的精确匹配(EM)均高于 Search-R1,排除了检索质量差异后证明 DART 提升了推理能力本身,而非依赖更好的检索。
在固定检索上下文(相同 retrieved evidence)下,DART 在 NQ 和 HotpotQA 上的精确匹配(EM)均高于 Search-R1,排除了检索质量差异后证明 DART 提升了推理能力本身,而非依赖更好的检索。
主要发现(3)——消融排除参数量解释:
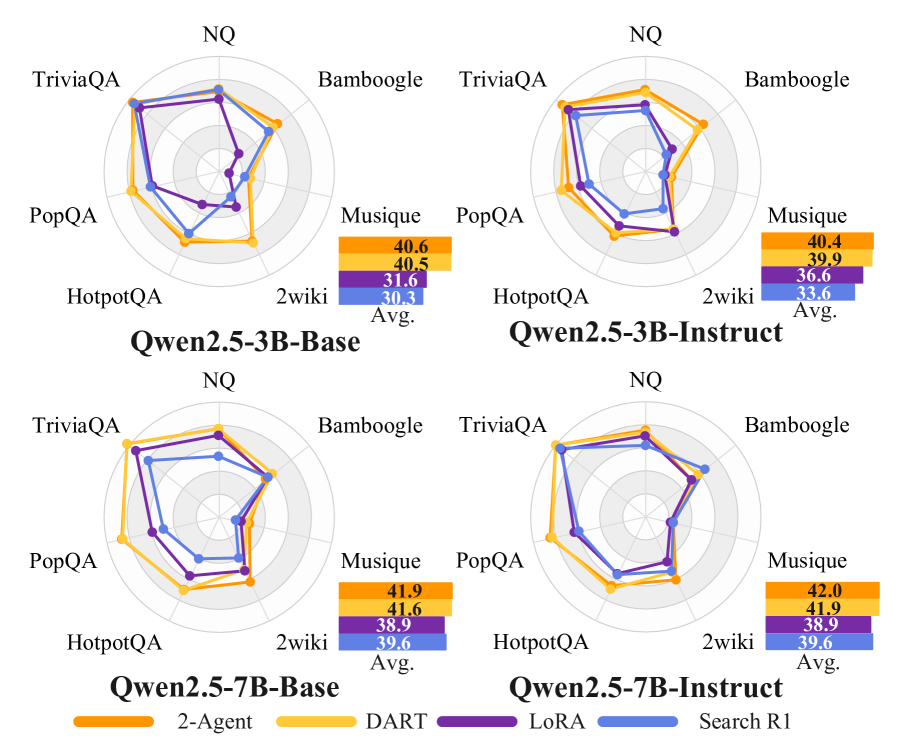 相同总 rank 的单 LoRA 与 Search-R1 性能相近(额外参数本身无益),而 DART 在多个规模和 benchmark 上接近 2-Agent 上界(两个独立完整模型各司一职),说明增益来自梯度解耦而非容量扩张。
相同总 rank 的单 LoRA 与 Search-R1 性能相近(额外参数本身无益),而 DART 在多个规模和 benchmark 上接近 2-Agent 上界(两个独立完整模型各司一职),说明增益来自梯度解耦而非容量扩张。
Conclusion
DART 提供了一个经实证支持的结论:在单一 Agentic 任务中,推理与工具调用并非天然互补——它们的梯度方向几乎正交,共享参数优化是主动的性能瓶颈。用两个独立 LoRA 适配器硬路由即可大幅缓解干扰,在 13 个 benchmark 上接近双模型上界。局限方面:实验仅覆盖检索增强 QA 和 NL2SQL 两类任务,尚未验证代码执行、数学工具调用等其他工具类型;模型规模止于 8B;论文未报告具体 GPU 硬件配置及训练时间开销;此外,硬路由对哨兵 token 的依赖要求数据预处理时精确标注工具调用边界,在格式不规范的真实场景中可能面临挑战。
Novelty Check
论文自述 Related Work:
- ARL with Tool-use(Schick 2023, Shao 2024, Zeng 2024 等):这些工作均采用联合优化,未研究能力间是否干扰。
- Multi-LoRA(Li 2024a, Luo 2024, Wu 2025 等):这些方法用软路由扩大容量或跨域迁移,本质上仍让梯度流过多个适配器,未解决硬隔离问题。
作者的核心 delta 是:将"任务/域级干扰"的已有认知推进到"同一 Agentic 任务内部、能力级别的干扰",并提供了逐问题量化工具(CEA)及对应解法(DART)。
独立评估:DART 的两适配器硬路由在结构上与专家混合(MoE)及条件 LoRA 方向相近,但将路由信号绑定到语义角色(reasoning vs. tool-use token)而非任务/域,切入点有新意。CEA 的形式化(per-question 交互系数)对于 ARL 场景是较新的诊断工具。总体属于有实质贡献的增量创新,并非简单重贴标签。
Open Questions
- CEA 分析是否适用于工具类型更多的场景(代码执行、计算器、多跳检索)?不同工具类型之间是否也存在类似干扰?
- DART 的硬路由依赖哨兵 token;若输入格式不规范(如混合格式的多轮对话),路由错误对性能的影响有多大?
- 论文在 3B–8B 规模验证;在 30B+ 或 MoE 架构模型上,梯度不对齐程度是否随规模变化?
- 消融仅比较了"单 LoRA vs DART vs 2-Agent";未探索 rank 分配策略对推理/工具调用的不对称影响(附录 G 提及 rank 效果,但主文未展开)。
- 2-Agent 上界本身的推理成本是 DART 的两倍;论文附录 F 从理论上分析了效率,但缺少实测 latency/memory 数据。
Original abstract
arXiv:2602.00994v2 Announce Type: replace Abstract: Agentic Reinforcement Learning (ARL) trains large language models to interleave reasoning with external tool execution to solve complex tasks. Most existing ARL methods train a single set of parameters to support both reasoning and tool-use behaviors, implicitly assuming that joint training leads to improved overall agent performance. Despite its widespread adoption, this assumption has rarely been examined empirically. In this paper, we systematically examine this assumption by introducing Capability Effect Attribution (CEA), which provides quantitative evidence of interference between reasoning and tool-use behaviors. Through an in-depth analysis, we show that these two capabilities often induce misaligned gradient directions, leading to training interference that undermines the effectiveness of joint optimization and challenges the prevailing ARL paradigm. To address this issue, we propose Disentangled Action–Reasoning Tuning (DART), a simple and efficient framework that explicitly decouples parameter updates for reasoning and tool use via separate low-rank adaptation modules. With this simple change alone, DART outperforms all joint-optimization baselines and approaches the 2-Agent upper bound across thirteen benchmarks on retrieval-augmented QA and NL2SQL, further supporting our finding of capability interference under shared optimization.