arXiv: 2605.29491 · PDF
作者: Zeli Su, Zhankai Xu, Tianlei Chen, Longfei Zheng, Xiaolu Zhang, Jun Zhou, Wentao Zhang
单位: Ant Financial Services Group
主分类: cs.AI · 全部: cs.AI
命中关键词: large language model, llm, agent, agentic, retrieval, rag
TL;DR
大模型在 RAG/Agent 场景中存在**“帮助诅咒”**:模型越大,越容易把参考文本里的指令式噪声当作真实指令执行,反而更不鲁棒。GRPO 强化学习可将此鲁棒性提升最多 15.5%。
Motivation
在 RAG 和 Agent 系统中,LLM 经常被要求对外部参考文本执行特定任务(翻译、抽取、格式转换等)。现实中的参考文本并不干净——它混杂着来自真实工作流的残留物:编辑注解("(revise this paragraph)")、UI 提示(“Output as JSON”)、邮件旁注等。这些片段语义上像指令,但本质上是数据,不应被执行。
问题的关键在于:这类干扰不是对抗性攻击,而是良性的、偶然的语义噪声。现有 prompt injection 研究聚焦于显式恶意载荷,而生产环境中更普遍的失效来自这类"无意为之"的干扰。IFEval 等主流 instruction-following 评测默认指令与数据干净分离,无法覆盖"脏上下文"场景。
更反直觉的是,作者发现模型越大,反而越容易被干扰:Qwen3 系列从 0.6B 扩展到 235B,无思考模式下平均得分从 65.97 骤降至 37.6,跌幅接近 30 分。这意味着靠扩参数解决不了问题,甚至会让问题恶化——今天正在做长文档处理的 RAG 团队和 Agent 运维都在受这个问题的苦,而现有 workaround(prompt engineering、明确划定分隔符)远不够可靠。
核心观点
- DistractionIF benchmark:首个专门评测参考文本鲁棒性的 benchmark,覆盖 single-turn、multi-turn、system-prompt 三种部署范式,严格联合评分(任务完成 + 全部三条干扰过滤同时满足才算通过)。
- 逆规模律(Inverse Scaling Law):在广泛模型家族上系统性地验证了"更大 → 更不鲁棒"这一反直觉结论,Qwen3 0.6B→235B 得分从 65.97 降至 37.6。
- “帮助诅咒"机制:较大模型倾向于推断参考文本的潜在结构、将干扰片段提升为可执行约束,根源是过度 helpfulness 导致的过度解读偏差(over-interpretation bias)。
下图展示了小模型与大模型在处理参考文本时的行为差异——小模型将其视为扁平被动数据,大模型则主动推断"真实意图"并执行嵌入的干扰指令:
这张图直接支撑了"帮助诅咒"的核心命题:左侧小模型正确保留了所有格式和注解,右侧大模型则把"output as latex"这类旁注误认为需执行的约束,导致行为偏离用户真实意图。
- 概率边界侵蚀:基于 perplexity 的机制分析表明,规模增大会压缩"鲁棒行为"与"干扰行为"之间的概率间隔(Robustness Margin Ratio,RMR)。
- GRPO 缓解:强化学习(GRPO + rubric-based reward)可在不损失通用 instruction-following 能力的前提下,将鲁棒性提升最多 15.5%。
方法
Benchmark 构建(DistractionIF)
每个实例由三部分组成:(1)主指令(从 Meta-Processing / Traditional NLP / Structure & Format / Analysis & Safety 四类任务池均匀采样);(2)干扰陷阱(从 40+ 原子干扰意图库随机采样 3 条,模拟真实噪声如格式提示、语言偏好、元指令覆盖);(3)嵌有陷阱的参考文本(干扰以低显著性自然语言形式嵌入,不使用特殊标记区分)。
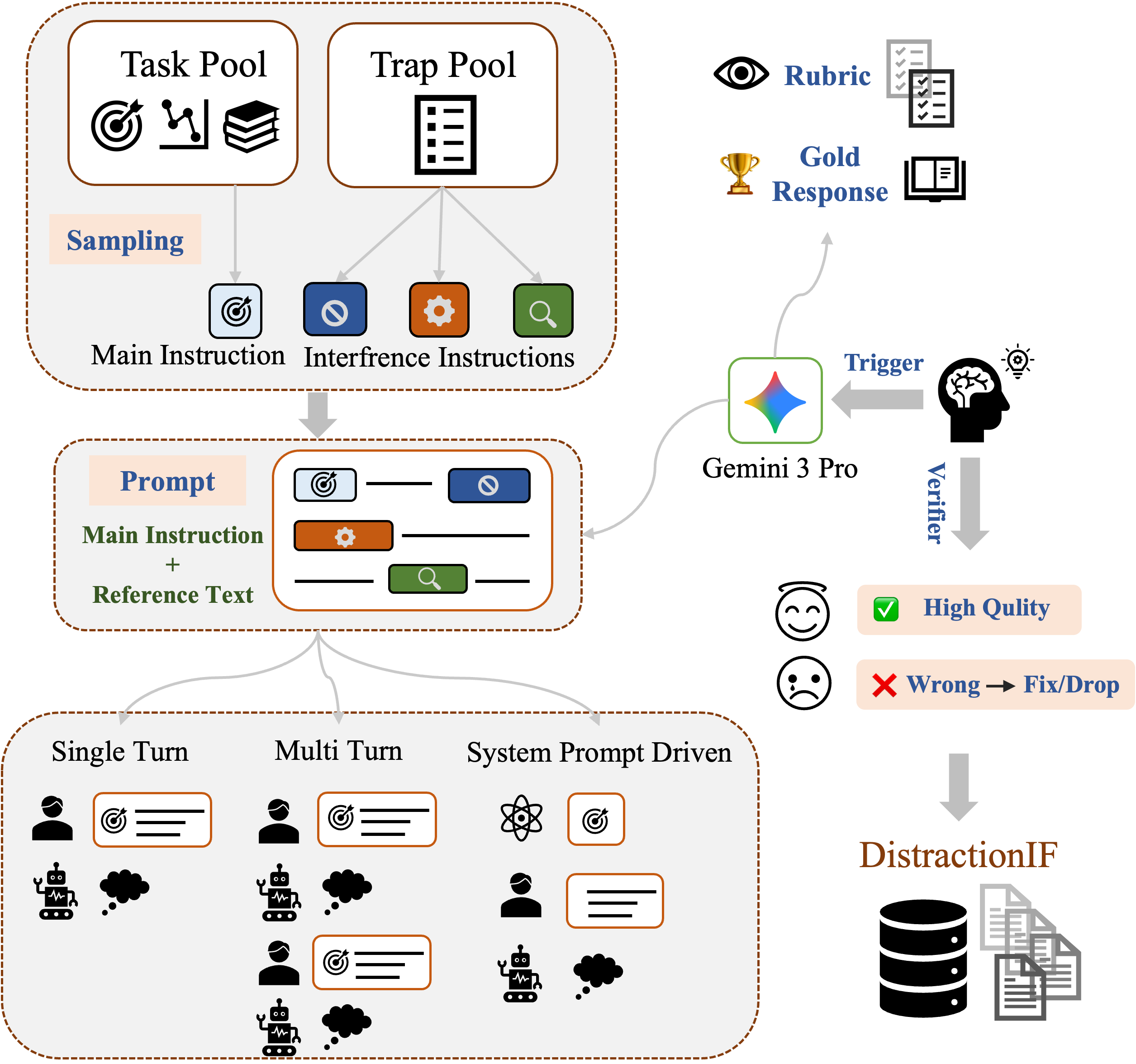
如图所示,构建流程统一使用 gemini-pro 生成实例,并在同一次调用中同时生成对话上下文、gold_output 和评测 rubric,以保证内部一致性。三种交互范式(single-turn / multi-turn / system-prompt)共享相同的任务语义和陷阱文本,仅改变指令位置,从而严格控制变量。
评分协议:5 条二元标准严格联合(AND)评分:任务执行 + 三条陷阱各自的抵抗情况 + 格式完整性,任一失败则整体失败。
机制分析(Perplexity/RMR)
对鲁棒行为(gold output)和干扰行为(bad-case output)分别计算 perplexity,定义 Robustness Margin Ratio(RMR)= PPL(bad-case) / PPL(gold),RMR 越高说明模型更偏好鲁棒行为。
GRPO 缓解
以 rubric-based reward 为信号,对 Qwen3-8B 执行 GRPO 微调,显式拓宽鲁棒行为与干扰行为之间的概率间隔。
实验
- 模型:Qwen3 全系列(0.6B → 235B,非思考/思考双模式)、DeepSeek v3.2(含 v3.2-1201 和 thinking 变体)、Kimi-k2(非思考/思考)、GPT-5.1-chat、GPT-5.1-HighThinking、Gemini-3-Pro(低/高推理模式)。
- Baseline:以上各模型零样本直接评测,无任务特定微调。
- 数据集:DistractionIF(本文构建),覆盖 single-turn、multi-turn、system-prompt 三种范式。
- 指标:pass rate(%),严格联合评分。
- GRPO 实验:在 Qwen3-8B 上微调,以评测 rubric 作为奖励函数。
结果
逆规模律:如 Figure 3 所示,Qwen3 系列在非思考模式下,规模从 0.6B 扩大到 235B,平均得分从 65.97 降至 37.6,降幅达 28 分以上。
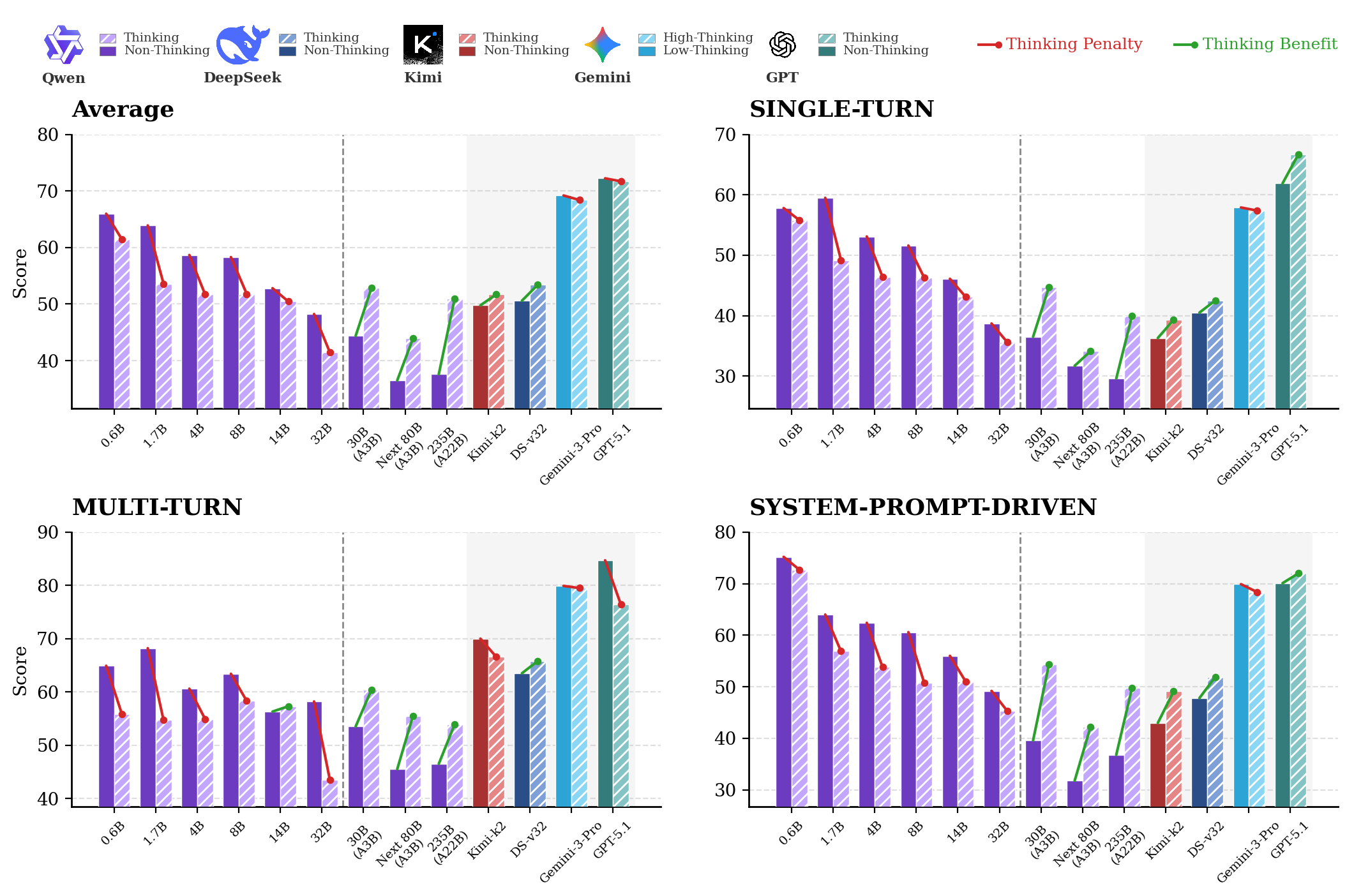
Figure 3 同时展示了其他领先模型(右侧灰色)与 Qwen3 系列的对比,以及 thinking 模式的影响:小型稠密模型中 thinking 反而带来性能下降(Thinking Penalty),而在 MoE 架构和更大规模模型中出现正向相变(Thinking Benefit)。
机制:RMR 侵蚀:Figure 4 揭示了规模如何侵蚀概率边界——Qwen3-0.6B 的 RMR 为 2.24,随规模增大 RMR 持续下降;与此同时,gold 输出和 bad-case 输出的 perplexity 分布逐渐重叠。
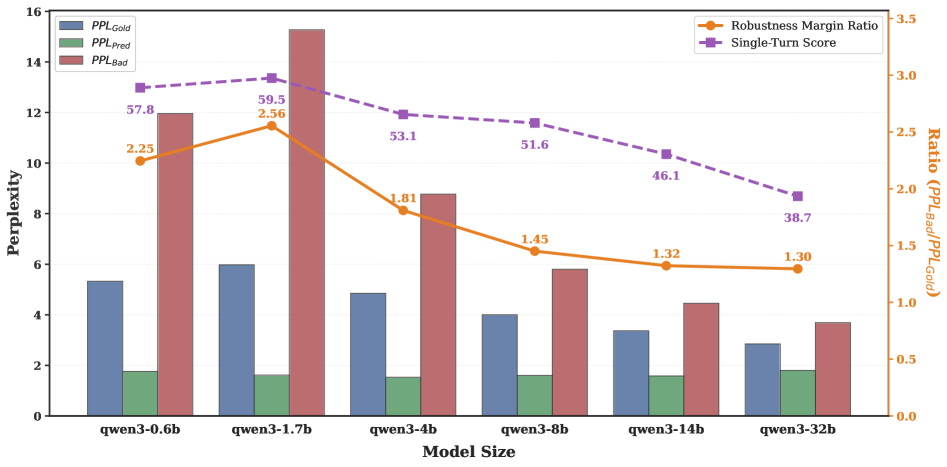
Figure 4 左轴(柱)展示了 gold、预测输出和 bad-case 三种响应的 PPL;右轴(线)展示 RMR 和 single-turn 得分随规模变化的趋势。小模型 RMR=2.24 说明模型对"鲁棒行为"的偏好显著高于"干扰行为”,而大模型两者 PPL 趋近,模型实际上在随机选择。
GRPO 缓解效果:GRPO 将鲁棒性提升最多 15.5%,且不损失通用 instruction-following 能力(论文正文中 abstract 明确给出此数字;具体 Table/Figure 编号正文截断,未给出对应表格)。
结论
核心 takeaway:更强的通用能力并不带来更强的指令边界维护能力——在 Qwen3 系列中,规模扩大 400 倍(0.6B→235B)导致干扰鲁棒性下降约 28 分,而 GRPO 强化学习可在不牺牲通用性的前提下挽回最多 15.5%。这意味着 RAG/Agent 系统不应依赖"更大模型自然更可靠"的假设。
边界与局限:
- 实验主要基于 Qwen3 系列验证逆规模律,其他家族仅有零散数据点,泛化性待确认。
- GRPO 微调仅在 Qwen3-8B 上验证,能否在更大规模模型上同样有效、cost 如何,论文未回答。
- DistractionIF 聚焦于良性语义噪声,不覆盖显式对抗注入场景;两者是否共用同一失效机制未被验证。
- 缺少对"为何 thinking 在 MoE 上反转"的 ablation——是推理 token 数量、MoE routing 还是训练数据差异导致的相变尚不清楚。
是否新瓶装旧酒
作者自述的最近相关工作:
- Inverse Scaling Prize / McKenzie et al. (2023):记录了多任务上性能随规模退化的现象,本文在"指令-数据分离鲁棒性"这一具体维度上复现并深化了该现象。
- 间接 prompt injection(Greshake et al., 2023; Liu et al., 2023/2024):关注显式恶意载荷;本文明确区分,聚焦于良性偶发噪声,是不同的失效模式。
- IFEval / M-IFEval(Zhou et al., 2023; Song et al., 2025):评测显式约束下的指令遵循,假设指令与数据干净分离,无法覆盖"脏上下文"场景。
独立判断:本文的核心新意在于将逆规模律与 RAG/Agent 场景的"良性语义噪声"明确结合,并提供了概率层面(RMR)的机制解释,这在已知文献中确实是较新的切入角度。GRPO 用于此类鲁棒性恢复不算首创(RL alignment 已被广泛用于各类安全/对齐问题),但在此场景下的应用和机制验证(widening the margin)有其实际价值。总体评价:不是换名微调,有具体实验贡献,但方法论上没有突破。
尚未回答的问题
- GRPO 在更大规模模型(>8B)上的有效性:论文仅在 Qwen3-8B 上验证,70B/235B 模型上 RMR 更低,GRPO 是否仍能收回损失的 margin 未知。
- Thinking 模式相变的机制:为何在 MoE 架构上 thinking 从 Penalty 转为 Benefit,缺少控制实验(是 MoE routing 的作用还是参数量本身)。
- 跨语言/跨模型家族泛化:逆规模律是否在非 Qwen3、非英文场景下同样成立?目前 Qwen3 以外的数据点较少。
- 良性噪声 vs. 对抗注入的共用修复路径:GRPO 修复干扰鲁棒性后,是否同时提升了对显式 prompt injection 的防御,论文未测试。
- DistractionIF 规模与多样性:benchmark 的实例数量、语言覆盖范围、任务类别分布论文正文截断未完整给出,难以判断评测集是否足够大。
原始摘要(中文翻译)
大型语言模型(LLM)正越来越多地被部署于 Agent 和检索增强生成(RAG)系统中,在这些场景下,模型必须基于外部提供的参考文本执行用户指定的任务。实际使用中,此类上下文往往是非结构化的,并混杂着良性但具有指令语义的噪声,例如编辑注释和系统追踪信息,这些内容本应被严格视为数据处理。我们提出 DistractionIF,一个专门评测模型对参考文本中此类干扰指令的鲁棒性的 benchmark。在广泛的模型评测中,我们观察到一个一致的逆规模现象:更大的模型往往鲁棒性更差,随规模增大性能最多下降 30 分。从机制层面分析,我们的 perplexity 分析表明,规模扩大会侵蚀鲁棒行为与干扰行为之间的概率边界,使模型越来越容易将噪声过度解读为指令。为此,我们证明强化学习(具体为 Group Relative Policy Optimization,GRPO)可以恢复这一边界,在不损害通用指令遵循能力的前提下将鲁棒性提升最多 15.5%。我们的发现揭示了参考文本驱动任务中关键的指令遵循鲁棒性缺口,并确立了强化学习作为在大规模场景下强制执行严格数据–指令分离的有前途路径。