arXiv: 2605.29491 · PDF
Authors: Zeli Su, Zhankai Xu, Tianlei Chen, Longfei Zheng, Xiaolu Zhang, Jun Zhou, Wentao Zhang
Affiliations: Ant Financial Services Group
Primary category: cs.AI · all: cs.AI
Matched keywords: large language model, llm, agent, agentic, retrieval, rag
TL;DR
Larger LLMs are systematically less robust to instruction-like noise embedded in reference text — a “Curse of Helpfulness” — which the new DistractionIF benchmark quantifies; GRPO-based RL partially recovers up to 15.5% robustness without hurting general instruction following.
Motivation
RAG and agentic pipelines routinely ask LLMs to process externally provided reference text: retrieved documents, enterprise files, upstream tool outputs. Real-world reference text is messy — it contains editorial annotations, UI residues, copied conversations, and system traces that look like instructions but are not intended to be followed. Current benchmarks like IFEval assume clean separation between instructions and data; no prior benchmark measures whether a model can resist incidental, benign noise at scale. The problem turns out to be worse precisely where practitioners would expect the opposite: larger, more capable models are more likely to “helpfully” act on embedded noise rather than ignore it. Practitioners deploying frontier models in production RAG pipelines had no reliable way to measure or anticipate this failure mode. The gap existed because prior prompt-injection work focused on conspicuous adversarial payloads, not low-salience benign residues like TODO comments or formatting hints naturally occurring in documents.
Key Ideas
The central finding is an “over-interpretation bias” in larger models — rather than treating reference text as flat passive data, they infer latent structure and misidentify incidental instruction-like fragments as actionable directives.
Figure 1 contrasts how smaller models correctly preserve all formats and notes in reference text against how larger models identify a “true body” and elevate semantic noise (e.g., “output as latex”) into executable constraints. This over-interpretation is the proposed mechanistic explanation for the ~28-point inverse scaling drop quantified on Qwen3 0.6B → 235B.
- DistractionIF benchmark: tasks over reference text contaminated with 3 low-salience distractors from a pool of 40+ atomic patterns; three deployment paradigms (single-turn, multi-turn, system-prompt); strict 5-criterion conjunctive rubric.
- Inverse scaling law: within Qwen3 (non-thinking), score drops 65.97 → 37.6 as scale goes 0.6B → 235B.
- Perplexity-based mechanism: scaling compresses the Robustness Margin Ratio (RMR) between robust and distracted output paths; Qwen3-0.6B has RMR = 2.24, which collapses at larger scales.
- GRPO mitigation: RL with rubric-based reward widens the eroded margin, recovering up to +15.5% robustness without degrading general instruction following.
Method
Benchmark construction: each instance has one main instruction (sampled from four task categories: Meta-Processing, Traditional NLP, Structure & Format, Analysis & Safety) and exactly three distraction intents from a pool of 40+ atomic patterns (editorial annotations, UI residues, style hints). Distractors are embedded as natural low-salience artifacts — side remarks, TODO notes, forwarded-message fragments — with no special markers. All three interaction paradigms are rendered from the same instance using gemini3-pro in one atomic invocation that also produces the gold output and evaluation rubric (“who poses also answers”), minimising alignment errors. ~2% of instances had rubric mismatches and were manually corrected.
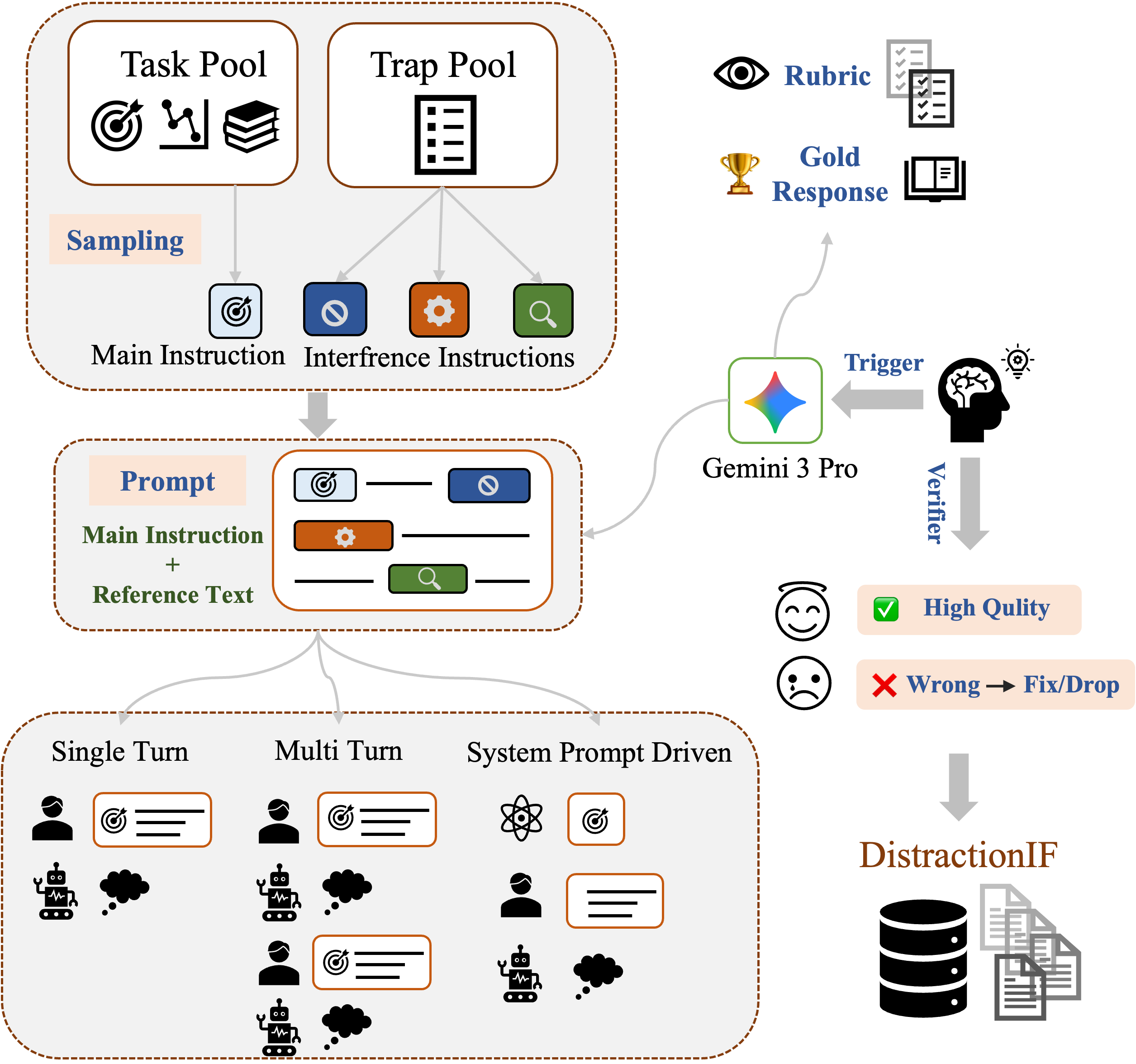
Figure 2 shows the full pipeline: starting from main instruction and trap pool, the 3 distractors are embedded into the reference text, then a single gemini3-pro call renders the instance into all three interaction formats with a consistent gold output and rubric, controlling for content variation across paradigms.
Scoring: 5 binary rubric criteria — (1) task execution, (2–4) resistance to each of the three distractors, (5) format integrity — graded conjunctively: all five must pass simultaneously.
GRPO mitigation: Qwen3-8B is fine-tuned with Group Relative Policy Optimization using the rubric-based reward directly.
Experiments
- Models: Qwen3 family (0.6B → 235B) in thinking and non-thinking modes; DeepSeek v3.2-1201 and thinking variants; Kimi-k2 (thinking and non-thinking); GPT-5.1-chat and GPT-5.1-HighThinking; Gemini-3-Pro (low- and high-reasoning).
- Benchmark: DistractionIF (authors’ own), three paradigms.
- Metric: Pass rate (%) under strict conjunctive rubric.
- Hardware: Not specified in available text.
Results
Within Qwen3 under non-thinking decoding, average DistractionIF score drops from 65.97 (0.6B) to 37.6 (235B) — a ~28-point degradation (Figure 3).
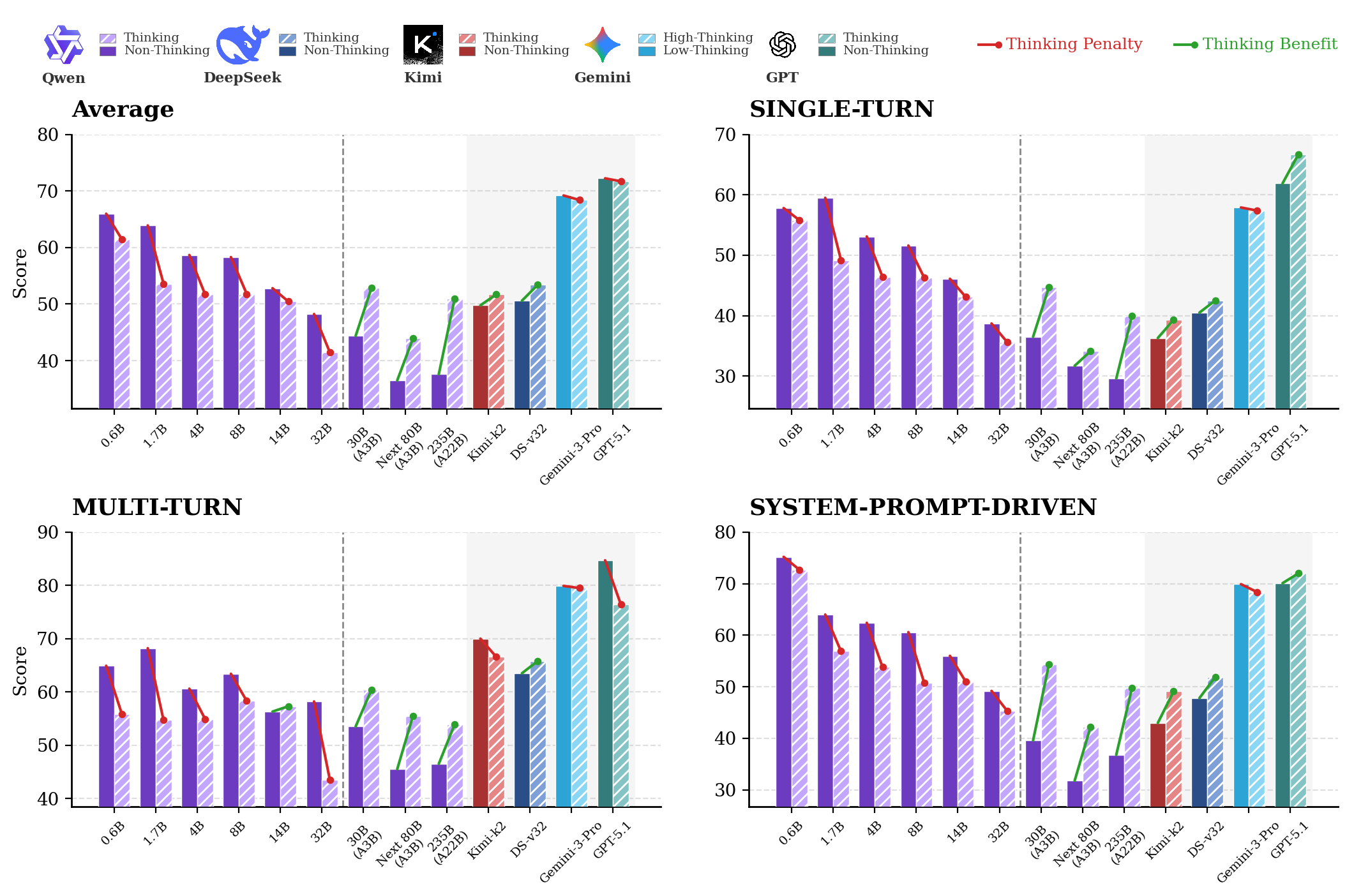
Figure 3 (left) shows Qwen3 as a clear monotonic inverse-scaling curve. It also reveals a nuanced thinking interaction: small dense models suffer a Thinking Penalty (reasoning mode worsens robustness), while large MoE architectures show a Thinking Benefit (phase transition to positive scaling). The right panel places proprietary models (GPT-5.1, Gemini-3-Pro, DeepSeek, Kimi-k2) in context.
The Robustness Margin Ratio mechanically explains why. Qwen3-0.6B achieves RMR = 2.24, meaning its probability mass for the correct response is 2.24× that of the distracted response; this margin collapses with scale (Figure 4).
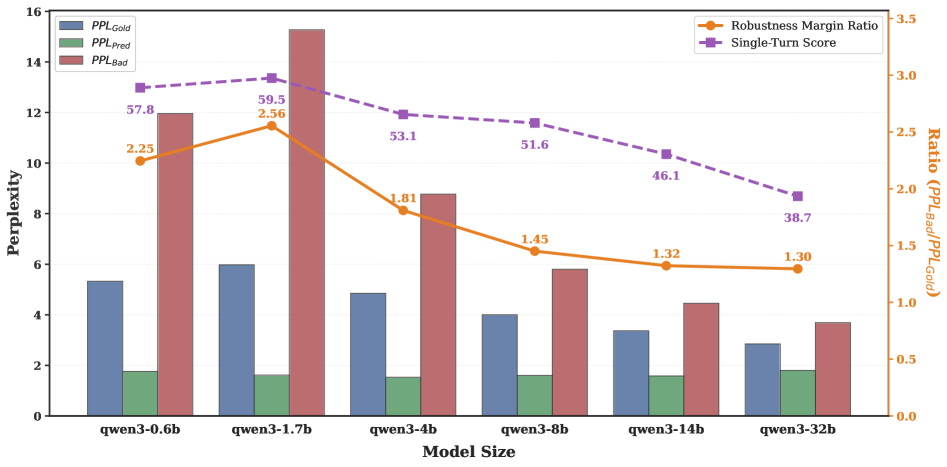
Figure 4 plots PPL of gold (blue bars), model prediction (green), and bad-case distracted (red) responses on the left axis, and the RMR with single-turn score on the right axis across model scales. Smaller models maintain a wide PPL gap; larger models assign increasingly similar likelihoods to both paths, directly explaining robustness erosion.
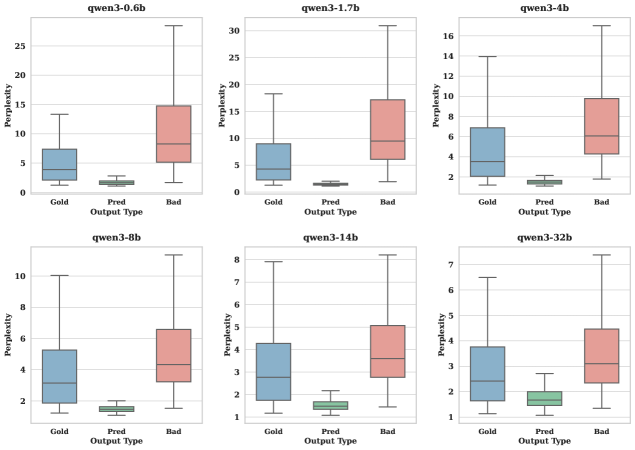
Figure 5 shows per-scale perplexity distribution grids: the gap between gold (blue) and bad-case (red) distributions narrows continuously with model size, confirming the erosion is distributional rather than isolated to outlier instances.
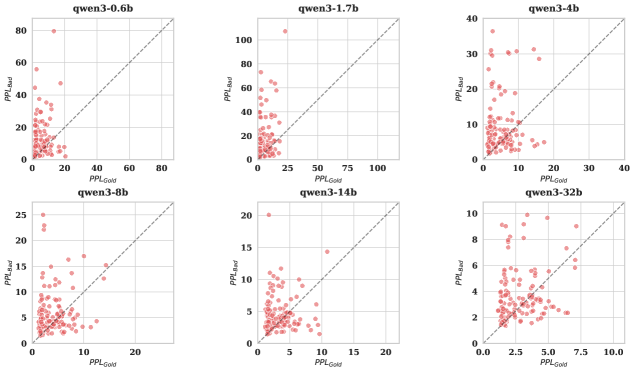
Figure 6 plots per-instance gold PPL vs. bad-case PPL as scatter plots across model scales. Points below the identity line indicate instances where the model finds distracted behavior more probable than correct behavior; the mass shifts increasingly below the diagonal at larger scales, quantifying how individual instances flip from robust to distracted as scale grows.
GRPO fine-tuning of Qwen3-8B recovers robustness by up to +15.5% across paradigms without degrading general instruction-following (abstract-only; detailed per-paradigm breakdown is in truncated text). Training dynamics are stable (Figure 7).
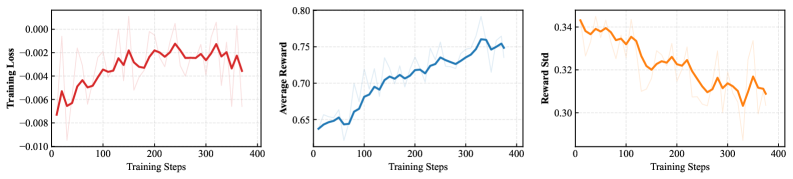
Figure 7 shows training loss, average reward, and reward standard deviation for Qwen3-8B under GRPO. The reward rises steadily while reward variance decreases, indicating the policy is learning to consistently prefer robust responses — consistent with the RMR-widening claim.
Conclusion
DistractionIF establishes that LLM robustness to benign instruction-like noise decreases with scale — Qwen3 drops ~28 points from 0.6B to 235B. The probabilistic mechanism (RMR collapsing from 2.24 at 0.6B) provides a concrete diagnostic. GRPO with rubric reward partially restores this (+15.5% peak). Key limits: the benchmark is self-constructed using gemini3-pro for both generation and evaluation, raising potential circularity and diversity concerns; GRPO results cover only Qwen3-8B, so cross-family generalization is unverified; the MoE thinking-benefit phase transition is observed but not mechanistically explained; the full per-paradigm results table is in the truncated paper section.
Novelty Check
From Related Work: Authors cite McKenzie et al. (2023)’s Inverse Scaling Prize as closest precedent, framing their delta as inverse scaling specifically in data–instruction separation under benign noise. They distinguish from Greshake et al. (2023) and Liu et al. (2023)’s adversarial injection work by targeting incidental residues rather than crafted attacks. IFEval (Zhou et al., 2023) is the nearest instruction-following benchmark, but assumes clean separation.
Independent assessment: The framing is reasonably novel — targeting benign ambient noise rather than adversarial payloads is a genuine gap. However, the LLM-generated-and-LLM-judged benchmark methodology is a standard limitation in this line of work that the paper does not deeply address. The GRPO application is methodologically straightforward, not algorithmically novel.
Open Questions
- Does inverse scaling hold uniformly across non-Qwen3 families? Figure 3 shows them but the results text is truncated.
- Does GRPO recovery generalize beyond Qwen3-8B to other model families or scales?
- The benchmark uses gemini3-pro for generation — is there contamination risk for Gemini-family model evaluation?
- What determines the MoE phase transition threshold for thinking benefit vs. penalty?
- The conjunctive rubric (all-or-nothing) may be overly strict; how does partial-resistance performance distribute across the three distractor slots?
Original abstract
arXiv:2605.29491v1 Announce Type: new Abstract: Large Language Models (LLMs) are increasingly deployed in agentic and retrieval-augmented generation (RAG) systems, where they must execute user-specified tasks over externally provided reference text. In practice, such context is often unstructured and contaminated with benign but instruction-like semantic noise, such as editorial comments and system traces, which should be treated strictly as data. We introduce DistractionIF, a benchmark designed to evaluate robustness against such distractor instructions in reference text. Across a broad range of models, we observe a consistent inverse scaling phenomenon: larger models are often less robust, with performance dropping by up to 30 points as scale increases. Mechanistically, our perplexity analysis reveals that scaling erodes the probabilistic boundary between robust and distracted behaviors, making models increasingly prone to over-interpreting noise as instructions. To address this, we demonstrate that reinforcement learning, specifically Group Relative Policy Optimization (GRPO), can restore this boundary, improving robustness by up to 15.5% without compromising general instruction-following capability. Our findings highlight a critical instruction-following robustness gap in reference-grounded tasks and establish reinforcement learning as a promising path for enforcing strict data-instruction separation at scale.