arXiv: 2605.24846 · PDF
作者: Xiangtian Ji, Yuxin Chen, Zhengzhou Cai, Xiang Wang, An Zhang, Tat-Seng Chua
单位: National University of Singapore, University of Science and Technology of China, University of Melbourne
主分类: cs.LG · 全部: cs.AI, cs.LG
命中关键词: large language model, llm, inference, serving, transformer, fine-tun
TL;DR
在多个主流开源 Transformer 中,极少数神经元(<0.2%)跨任务持续高激活,关闭它们即触发全局能力崩溃;仅对这批"keystone neurons"做有监督微调,效果优于或持平全参数微调,同时更好保留通用能力。
Motivation
当前对 LLM 内部机制的理解严重滞后于其外部表现:研究者已知存在"任务专属神经元"(如多语言、代码、数学各有一批),但尚不清楚是否存在更基础的、跨任务皆不可缺的神经元子集。这一空白直接影响两类实践:一是模型可解释性研究者——缺乏对"核心骨干"的定量把握,无法解释为何极小扰动就能让 LLM 彻底失能;二是 PEFT(参数高效微调)从业者——现有方法(LoRA 等)从优化视角选参数,并未考虑"哪些神经元对多维能力最关键"。作者认为激活分析工具和多模型对比实验的成熟让这个问题现在值得系统研究,且只需极少几条 prompt 即可完成探测,成本极低。
核心观点
下图从概念层面说明了 keystone neurons 的核心性质:它们在不同任务的 prompt 下都保持高激活,一旦关闭就引发全局能力崩溃,而非仅影响某一特定任务。
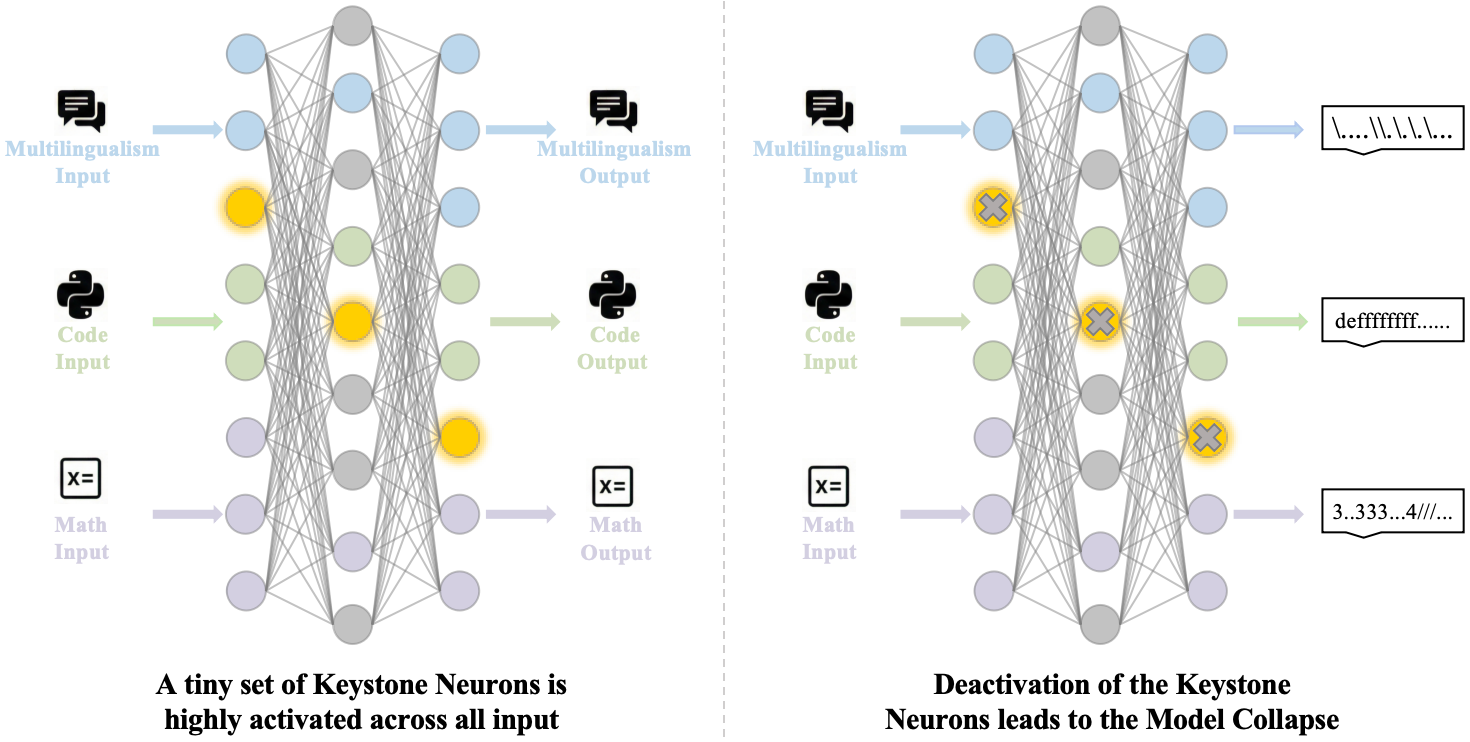
- 跨多个主流 Transformer 系列,存在一批极稀疏的神经元(通常 <0.2%),在不同能力维度的 prompt 下均持续高激活,称为 keystone neurons。
- 仅关闭这批神经元即造成全部评测指标归零,而关闭等量随机神经元影响极微(Table 1)。
- Keystone neurons 对 prompt 选择高度稳定,5 组不同 prompt 检测的平均 IoU 在 80%–95% 之间,最低也超 73%(Table 2)。
- 该子集主要在预训练阶段形成,其参数被高精度校准,微小的乘法缩放即引发显著性能退化。
- 仅更新 keystone neurons 的权重做监督微调,在数学推理和安全对齐任务上效果可达到或超越全参数微调,同时更好保留其他维度能力。
方法
两阶段识别流程:
Stage 1(多 prompt 激活分析):构造 K 条跨能力维度的探测 prompt(本文用 4 条,分别覆盖通用、数学、代码、多语言),对每条 prompt 收集全部神经元的平均绝对激活值 $\bar{a}i(p)$;在每个 layer-module block 内,取各 prompt 激活前 $\rho$ 分位的神经元集合,再对所有 prompt 取交集,得到候选池 $\mathcal{S}\text{cand}$。
Stage 2($\alpha$-controlled masking):对候选池按激活强度排序,逐步扩大前 $\alpha$ 比例神经元并在 forward pass 中将其输出置零,在 MMLU / Math500 / MGSM / EvalPlus 上评测,找到触发全局崩溃的最小前沿,即 keystone set。
推理时扰动:对 keystone neurons 输出乘以标量 $r$,与等量随机神经元对比,验证精确校准的必要性。
Keystone-only 微调:在标准监督微调流程中,梯度仅回传到与 keystone neurons 对应的权重行/列,其余参数冻结。
实验
- 模型:Qwen3(0.6B/8B/30B-A3B MoE)、Qwen2.5(0.5B/7B)、Llama3(1B/8B)、Gemma3-1B、DeepSeek-R1-Distill(Qwen-1.5B/7B、Llama-8B)、Mixtral-8×7B,共覆盖 dense / MoE / instruction-tuned / reasoning-distilled 多类型。
- 评测 benchmark:MMLU(通用)、MATH500(数学)、EvalPlus(代码)、MGSM(多语言);困惑度用 C4 和 WikiText-2。
- 消融 baseline:等量随机神经元关闭、高 norm 神经元关闭、模块内随机替换(详见 Appendix C.3)。
- 微调 baseline:全参数 SFT;评测覆盖数学推理和安全对齐两类任务。
结果
全局能力崩溃的极端稀疏性(Table 1):对 Qwen3-8B,关闭 keystone neurons 后 MMLU/Math500/MGSM/EvalPlus 全部降至 0,C4 困惑度从 15.74 升至 19.53;而关闭等量随机神经元,MMLU 仍维持 0.824(基线 0.821),困惑度仅小幅上升。对 Llama-3.1-8B-Instruct,仅关闭 0.0072% 的神经元(90/1,245,184 个)即触发完全崩溃,随机关闭同等数量神经元则影响可忽略(Table 1)。
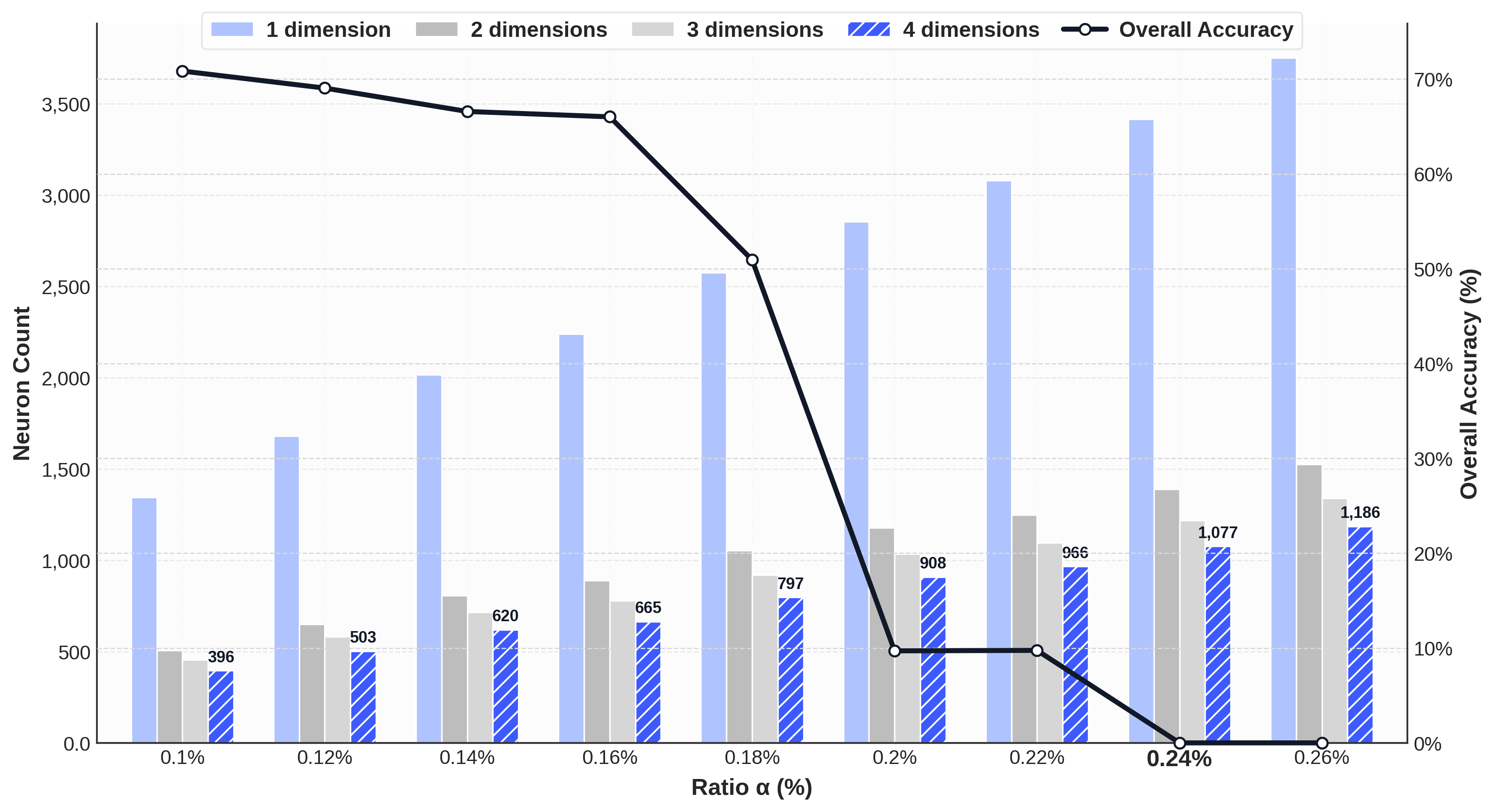
以下图展示了 Qwen2.5-7B-Instruct 在不同 $\alpha$ 下,四维度 top-$\alpha$ 神经元的交集规模(柱状图)和遮蔽交集后的综合准确率(黑线):随着 $\alpha$ 增大交集迅速缩小,而极小 $\alpha$ 的交集已足以使模型完全失能,印证了 keystone neurons 的极端稀疏性与结构关键性。
精确校准敏感性(Figure 3):对 Qwen2.5-7B-Instruct 和 Qwen2.5-0.5B-Instruct,对 keystone neurons 输出乘以缩放因子 $r$,综合分(MMLU+Math500+MGSM+EvalPlus 等权均值)随 $r$ 偏离 1 迅速下降;而对等量随机神经元做同样操作,曲线在更大范围内保持平稳,两者在 $r$ 偏离时的退化速率差异显著。
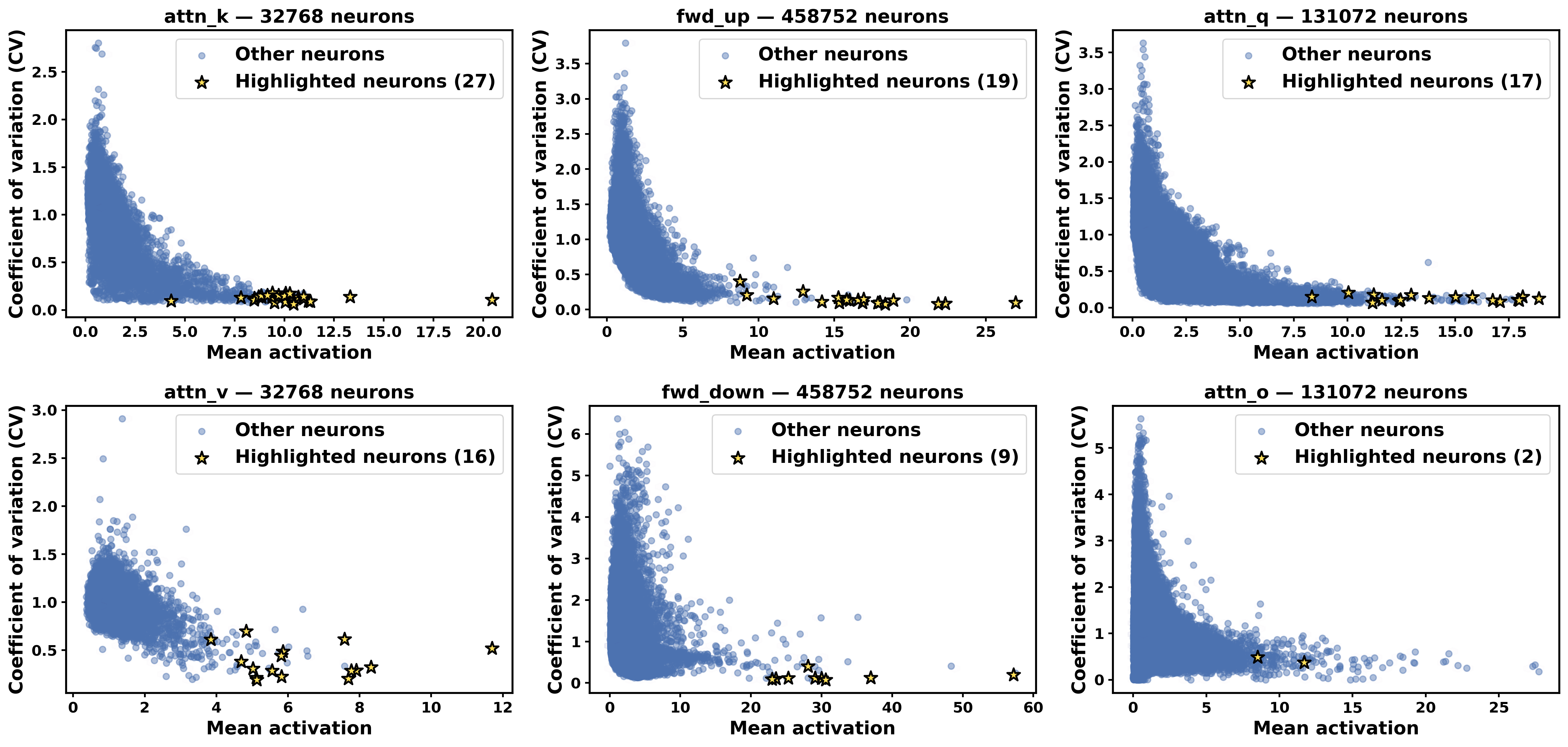
高激活–低变异系数的分布特征(Figure 4):在 Llama-3.1-8B-Instruct 的各子模块(Q/K/V/O attention 及 FFN up/down)散点图上,keystone neurons 集中在高均值激活、相对小变异系数的尾部区域,与普通神经元分布明显分离,定量描述了其"稳定高激活"的结构特征。论文未在此图中给出具体数值。
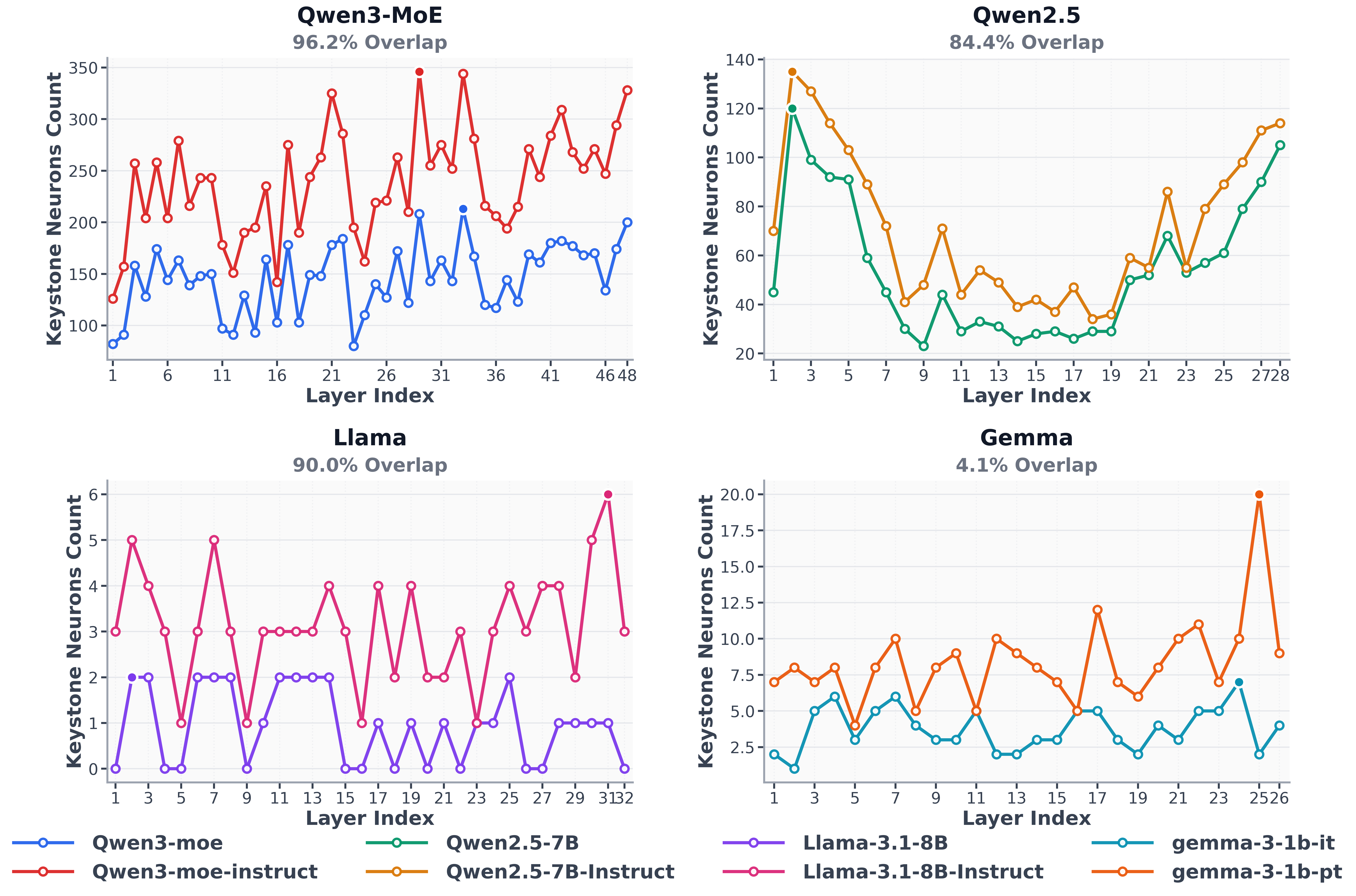
Keystone neurons 的层分布与 base/instruct 一致性(Figure 5):跨 Qwen2.5、Qwen3-MoE、Llama3、Gemma3 系列,base 与 instruct 模型的 keystone neurons 逐层分布高度重叠(图注标注了各模型的 base–instruct overlap 百分比),支持"keystone neurons 主要在预训练阶段形成"的核心论断。论文正文未给出每个模型的具体重叠百分比数值。
微调结果:论文正文在本次提供的截断版本中未给出具体数字,abstract 描述为"comparable to or even better than full-parameter fine-tuning while better preserving performance in other capability dimensions",章节标题亦注明"Keystone-only tuning consistently outperforms full-parameter fine-tuning on mathematical reasoning"——未拿到全文数值,不作具体引用。
结论
核心 takeaway:LLM 中存在一个极稀疏(<0.2%)但功能上不可或缺的神经元子集,仅凭 4 条 prompt 即可可靠识别,关闭它们必然引发全局崩溃,而基于它们的定向微调效果可超越全参微调。这一结论在 Qwen2.5/Qwen3/Llama3/Gemma3/Mixtral 等多个系列上均成立。边界:① 所有实验限于英文 decoder-only Transformer,encoder 或多模态架构未验证;② 微调结果仅覆盖数学和安全对齐两个任务,未知对其他任务类型是否普适;③ 缺少与 LoRA 等主流 PEFT 方法在相同计算预算下的直接对比数字;④ Keystone neurons 在持续预训练或进一步 RLHF 后是否漂移,论文未讨论。
是否新瓶装旧酒
论文 Related Work 自述:作者将最相近工作分为两类:(1) 任务专属神经元(Tang et al. 2024 多语言;Miller et al. 2025 代码;Yu & Ananiadou 2024 数学)——作者的 delta 是跨任务而非单任务;(2) LLM 模块化(Bricken et al. 2023 稀疏自编码器;Fedus et al. 2022 MoE 路由)——作者的 delta 是用激活稀疏直接识别,无需额外训练。
独立判断:Lottery Ticket Hypothesis(Frankle & Carbin 2019,论文已引)从梯度角度找关键权重,而本文从激活角度找关键神经元,且目标是"跨任务崩溃"而非剪枝稀疏性,框架确有区分。“用激活交集定位关键神经元"这一操作本身并非首创,但系统地跨模型系列验证其跨任务必要性,并直接用于微调选参,属于有实质增量的新工作,并非换名。
尚未回答的问题
- 与 LoRA 的直接对比:缺少在相同可训练参数预算下 keystone-only vs. LoRA 的量化对比,无法判断哪种 PEFT 方式更优。
- Keystone neurons 的持久性:经过多轮 RLHF 或持续预训练后,keystone set 是否漂移?IoU 会降到什么水平?
- 识别方法对非 decoder-only 架构的推广:encoder-decoder、多模态 LLM 是否也有同等性质的 keystone neurons?
- $\rho$ 和 K 的敏感性 ablation:论文固定用 4 条 prompt(K=4),但未系统消融 K 减少到 1–2 时 keystone set 的 IoU 如何变化,识别所需最小 prompt 数尚不清楚。
- 微调任务泛化:除数学和安全对齐外,指令跟随、长上下文推理等任务上 keystone-only 微调的边界未知。
原始摘要(中文翻译)
大型语言模型(LLM)在广泛的现实任务中表现出强大的综合能力,然而支撑这些行为的内部机制至今仍未得到充分理解。本文证明,在大量开放权重 Transformer 中,存在一个神经元子集,在多个能力维度的推理任务中始终保持高激活状态。通过沿跨任务激活强度进行探测,我们分离出一个极度稀疏的子集,将其去除会导致模型行为全面崩溃,我们将其称为 keystone neurons(基石神经元)。我们的分析表明,keystone neurons 是模型稳定且固有的神经元子集,大部分在预训练阶段就已形成。与这些神经元相关的参数在训练过程中被精确校准,其精确数值对模型能力至关重要。基于这些洞察,我们提出一种仅更新 keystone neurons 的有监督微调方法,在修改参数数量远少于全参数微调的情况下,实现了与全参数微调相当甚至更优的任务提升,同时在其他能力维度上的表现保留得更好。