arXiv: 2605.24846 · PDF
Authors: Xiangtian Ji, Yuxin Chen, Zhengzhou Cai, Xiang Wang, An Zhang, Tat-Seng Chua
Affiliations: National University of Singapore, University of Science and Technology of China, University of Melbourne
Primary category: cs.LG · all: cs.AI, cs.LG
Matched keywords: large language model, llm, inference, serving, transformer, fine-tun
TL;DR
A tiny, cross-task subset of neurons (< 0.2% of all neurons) called “keystone neurons” can be identified in open-weight LLMs with just four prompts; removing them collapses all model capabilities, while fine-tuning only them matches or exceeds full-parameter fine-tuning.
Motivation
Prior interpretability work has identified task-specific neurons linked to multilingual processing, code generation, and mathematical reasoning. But those neurons primarily affect their target task while leaving other capabilities largely intact. This leaves a deeper question unanswered: is there a cross-task structural backbone — an even tinier set of neurons that every capability depends on — that underlies the model’s broad competence? If such a set exists, its removal should cause global, not local, collapse. No prior work had posed or answered this question. The practical stakes are real: if such a backbone exists and is stable, it could be leveraged for highly parameter-efficient fine-tuning, enabling task adaptation that does not degrade unrelated capabilities — a known failure mode of standard full-parameter supervised fine-tuning.
Key Ideas
The paper identifies “keystone neurons” in LLMs — a cross-task, consistently activated subset that functions as a structural backbone:
- Extreme sparsity with global criticality: keystone neurons make up < 0.2% of all neurons (e.g., 30 neurons out of 1,245,184 in Llama-3.1-8B), yet zeroing them drives all benchmark scores to 0.
- Prompt-agnostic stability: five disjoint prompt groups covering the same capability dimensions yield pairwise IoU of 80–95%, confirming keystone neurons are an intrinsic model property, not a detection artifact.
- Established during pretraining: base and instruction-tuned variants share substantial keystone overlap, and the sets are stable across fine-tuning variants (reasoning-distilled, MoE).
- Tight calibration: keystone neuron outputs are highly sensitive to multiplicative scaling; equivalent interventions on random neurons of matched size produce far smaller degradation.
- Targeted fine-tuning: updating only keystone neuron parameters achieves gains comparable to or better than full-parameter fine-tuning on math and safety benchmarks while better preserving unrelated capabilities.
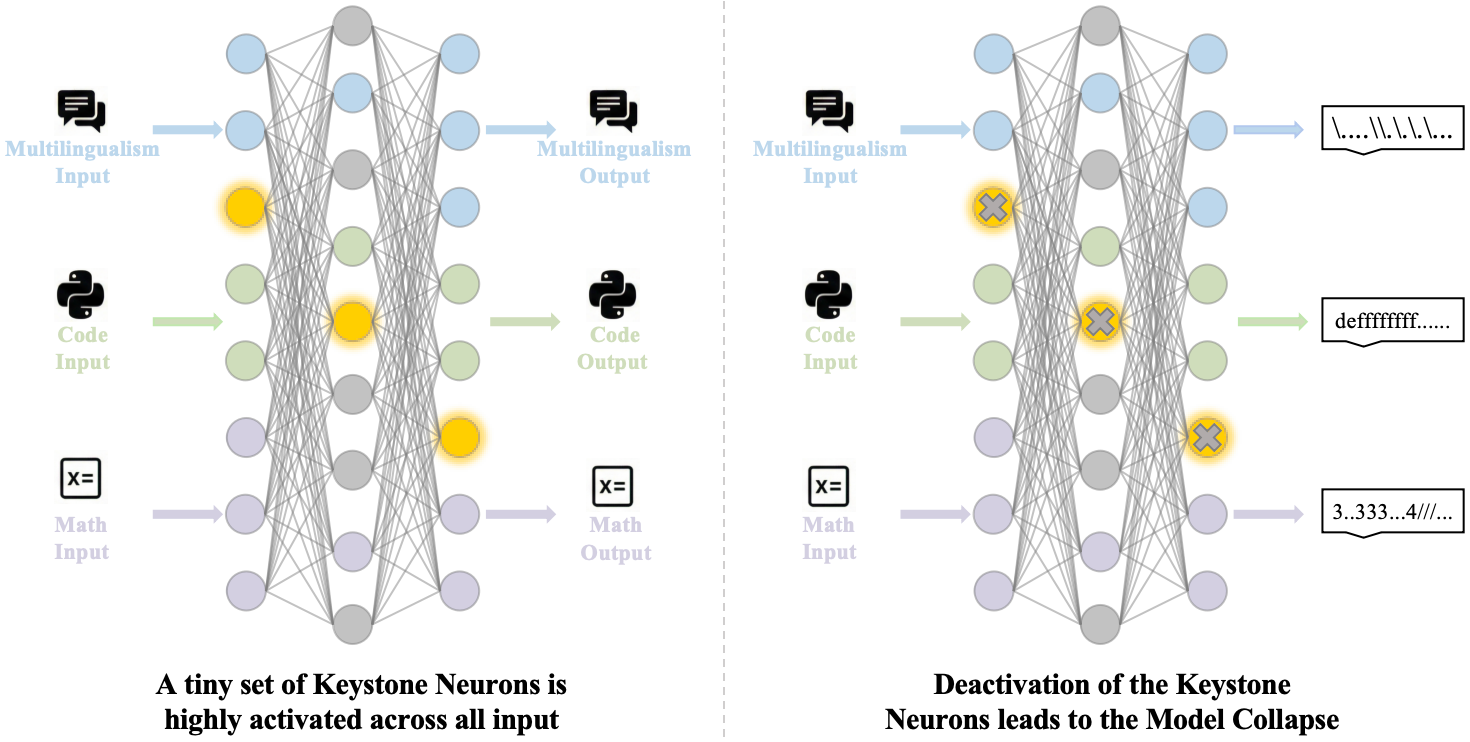
The conceptual illustration captures the defining property of keystone neurons: unlike task-specific neurons that light up for one domain, keystone neurons engage consistently across all capability dimensions (general, math, code, multilingual), forming a universal backbone. Their deactivation does not selectively impair one task — it causes global capability collapse across every benchmark.
Method
Stage 1 — Multi-prompt activation analysis: A small probe set of K prompts (one per capability dimension: general, math, code, multilingual) is passed through the model. For each prompt, every neuron’s mean absolute activation across all generated tokens is recorded. Within each layer–module block, the top-ρ fraction by activation is retained per prompt. The intersection across all K prompts forms the candidate pool — neurons persistently among the most activated regardless of task.
Stage 2 — α-controlled masking: Candidates are ranked by cross-task activation strength. A scalar α sweeps the top-α fraction: selected neurons are zeroed during the forward pass (outputs set to zero) while the rest of the network is frozen. Performance is measured on MMLU, MATH500, MGSM, and EvalPlus plus C4 and WikiText-2 perplexity, identifying the sparse frontier where masking triggers capability collapse.
Targeted fine-tuning: Only the weight rows/columns corresponding to keystone neurons are updated during supervised fine-tuning; all other parameters are frozen.
Experiments
Models: Qwen3 (0.6B, 8B, 30B-A3B MoE), Qwen2.5 (0.5B, 7B, instruct variants), Gemma-3-1B, Llama-3.2-1B and Llama-3.1-8B (base and instruct), DeepSeek-R1-distill variants (Qwen-1.5B, Qwen-7B, Llama-8B), Mixtral-8×7B.
Benchmarks: MMLU (general), MATH500 (math), MGSM (multilingual), EvalPlus (code synthesis); C4 and WikiText-2 perplexity for language modeling quality.
Baselines: random-neuron ablation (matched count), high-norm neuron ablation, module-aware random ablation, same-layer same-module random replacement (all in Appendix C.3).
Results
Complete collapse from keystone removal (Table 1): Across every tested model, zeroing keystone neurons drives MMLU, MATH500, MGSM, and EvalPlus to 0. For Llama-3.1-8B-Instruct, deactivating just 90 neurons (0.0072% of 1,245,184 total) achieves this; the same model’s perplexity on C4 jumps from 11.78 to 522. By contrast, removing an equal-sized random set preserves near-baseline accuracy (random-off MMLU = 0.706 vs. base 0.713) and causes only minor perplexity shifts (C4: 11.83 vs. 11.78). Qwen3-8B shows the same pattern: keystone-off collapses all benchmarks from a base of 0.821/0.942/0.842/0.669 on MMLU/MATH500/MGSM/EvalPlus to 0, while random-off is 0.824/0.638/0.856/0.651 — a partial but not catastrophic degradation.
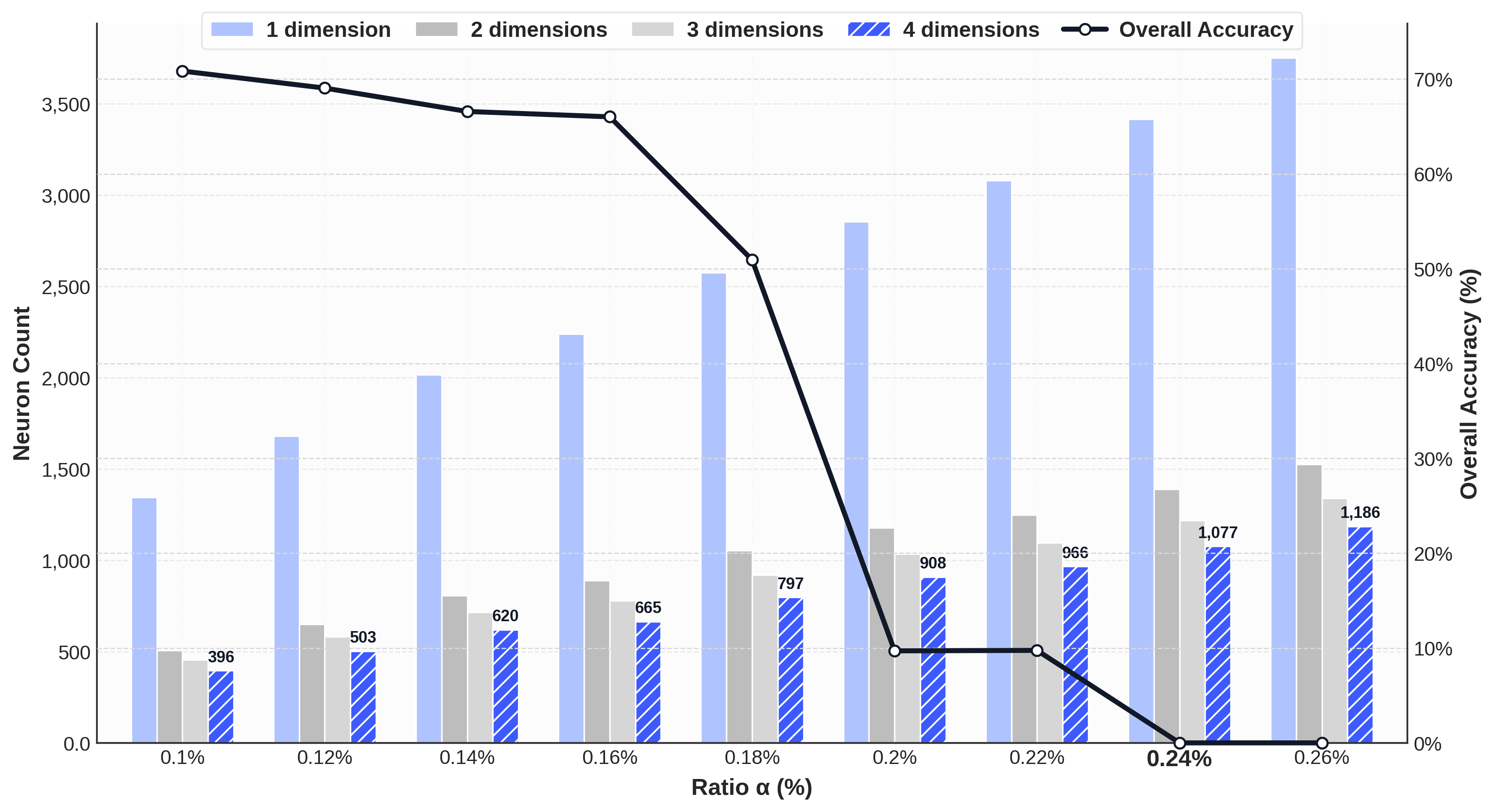
Figure 2 shows for Qwen2.5-7B-Instruct how the 4-dimension intersection of top-α neurons (bars, left axis) remains a tight cluster even as α grows, while the comprehensive accuracy (black curve, right axis) collapses sharply once the intersection is zeroed — confirming that cross-task overlap, not raw activation magnitude, is the key predictor of functional criticality.
Keystone sensitivity vs. random neurons under scaling (Figure 3): For Qwen2.5-7B-Instruct and Qwen2.5-0.5B-Instruct, multiplicative rescaling (r ≠ 1) of keystone neuron outputs causes rapid, pronounced degradation in the aggregate score, whereas the same rescaling applied to a size-matched random set produces far smaller effects — establishing that keystone neurons are tightly calibrated, not merely high-activation.
The figure plots aggregate capability score vs. scaling factor r for keystone vs. random neurons across both model sizes. Keystone curves drop steeply for both r > 1 (amplification) and r < 1 (attenuation), while random-neuron curves remain nearly flat across the same range — quantifying the sensitivity asymmetry that defines keystone neurons as precisely calibrated.
Fine-tuning results (Sections 4.2–4.3): The full text is truncated before the specific fine-tuning numbers; the abstract states keystone-only fine-tuning achieves “comparable to or even better than full-parameter fine-tuning” on math and safety benchmarks while “better preserving performance in other capability dimensions” — exact deltas not available in the provided text.
Conclusion
The central finding is that LLMs harbor an extremely sparse cross-task backbone (< 0.2% of neurons), whose removal causes uniform, global capability collapse while equal-sized random ablations do not. This is established empirically across 19 model checkpoints spanning 4 architecture families (Qwen, Llama, Gemma, Mixtral) at sizes from 0.5B to 30B. The targeted fine-tuning result is directionally compelling but its specific quantitative gains are not available in the provided text. The study is limited to decoder-only Transformers evaluated on English-centric benchmarks; the claim that keystone neurons are established during pretraining rests on base–instruct overlap patterns rather than a pretraining intervention. The practical benefit of keystone-only fine-tuning over established PEFT methods (LoRA, DoRA) is not directly compared.
Novelty Check
From Related Work (Section 5): The authors position against task-specific neuron work — multilingual (Tang et al., 2024; Chen et al., 2025), code (Miller et al., 2025), math (Yu and Ananiadou, 2024), and safety (Song et al., 2024; Wang et al., 2025a) — and against modularity/sparsity work (Fedus et al., 2022; Bricken et al., 2023). Their framing: prior work isolates neurons for single capabilities; they are the first to identify a cross-task, globally-critical subset.
Independent assessment: The cross-task framing is a genuine conceptual shift from task-specific neuron work. The identification of a universal capability backbone with global collapse-inducing properties is novel in its framing and empirical scope. The use of only 4 prompts for identification is a notable practical contribution. The connection to fine-tuning efficiency overlaps with LoRA-adjacent literature (which targets low-rank subspaces rather than specific neurons), but the keystone-based approach is mechanistically distinct. Overall, genuinely new contribution, not a relabel.
Open Questions
- How do keystone neurons compare to LoRA/DoRA in fine-tuning efficiency and capability retention on the same benchmarks, with identical training data?
- Do keystone neurons identified in English-prompt probing remain structurally identical for multilingual models evaluated on non-English tasks?
- What is the causal mechanism during pretraining that makes specific neurons become keystone? Is it tied to a particular training phase or data mix?
- For MoE models (Mixtral, Qwen3-30B-A3B), do keystone neurons cluster in specific experts, and does expert routing interact with keystoneness?
- Can keystone neurons be used to detect or prevent fine-tuning-based capability degradation in production settings?
Original abstract
arXiv:2605.24846v2 Announce Type: replace-cross Abstract: Large language models (LLMs) display strong comprehensive abilities, yet the internal mechanisms that support these behaviors remain insufficiently understood. In this work, we show that across a wide range of open-weight Transformers, a subset of neurons remains consistently highly activated during inference across tasks of multiple capability dimensions. By probing along the cross-task activation strength, an extremely sparse subset is isolated, whose removal causes a collapse in model behavior, which we term keystone neurons. Our analysis reveals that keystone neurons are a stable and intrinsic neuron subset of the model that is largely established during pretraining. The parameters associated with these neurons are tightly calibrated during the training process, and their precise values are critical for the capabilities of the model. Building on these insights, we propose a supervised fine-tuning approach that updates only keystone neurons, achieving task gains comparable to or even better than full-parameter fine-tuning while better preserving performance in other capability dimensions, despite modifying a much smaller number of parameters.