arXiv: 2605.29639 · PDF
作者: Boyu Tan, Jiarui Guo, Zongwei Lv, Hanbo Sun, Tong Yang, Kan Liu, Xinfei Shi, Zetao Hu, Yaxin Yu, Chi Zhang, Jianning Zhang, Xi Yang, Wei Zhang, Bo Cai, Silu Zhou, Xiyu Wang, Na He, Yinghao Yu, Wending Bao, Guiyang Huang, Yuxing Yuan, Juncheng Yin, Nan Wang, Lin Yang, Zechao Zhang, Lu Chen, Guoding Li, Tao Lan, Lin Qu
单位: Alibaba Group, Peking University, Zhejiang University
主分类: cs.OS · 全部: cs.OS
命中关键词: large language model, llm, inference, serving, kv cache, parallelism, quantization, speculative decoding, throughput, latency
TL;DR
RTP-LLM 是阿里巴巴面向工业级 LLM 推理的高性能引擎,已在生产中服务超 1 亿用户,通过 PD 分离、分层 KV Cache、模型加速加载、投机解码等集成设计,相比 vLLM / SGLang 在加载速度、吞吐和延迟上全面领先。
Motivation
现代 LLM 推理面临四个生产级瓶颈:第一,GPU 在自回归 decode 阶段严重欠利用——内存带宽受限而算力闲置,静态 batching 无法适应请求长度的极端变化(短至几十 token,长至 128K+);第二,KV Cache 随序列长度线性膨胀,成为显存的主要消费者,限制并发和可扩展性;第三,稠密大模型、600B+ MoE、多模态模型对系统结构的异构需求,现有框架难以统一支撑;第四,企业要求分钟级加载 600B+ 参数模型以实现持续更新,而现有系统加载耗时以小时计,缺乏容错与滚动更新能力。
vLLM 和 SGLang 虽然各自推进了 KV Cache 管理(PagedAttention)和内核优化,但均聚焦单节点性能,忽略了系统各组件之间的协同:调度策略与 KV Cache 状态脱节、prefill/decode 混跑导致资源争抢、多模态视觉编码与语言生成耦合造成串行等待。RTP-LLM 的切入点不是某个孤立技术,而是在 Alibaba 亿级流量生产环境中通过系统集成来弥合这些差距。
核心观点
- 提出并实现 Prefill-Decode Disaggregation(PD 分离)架构,将计算密集的 prefill 与内存带宽受限的 decode 物理解耦到独立节点,独立弹性扩缩。
- 设计分层多级 KV Cache 管理,覆盖 GPU 显存、本地 CPU 内存、RDMA 远程 CPU 内存及分布式存储,以统一 hash 前缀匹配实现跨请求 cache 复用。
- 实现文件顺序驱动 I/O + 并行 I/O-通信重叠的模型加载优化,支持分钟级 600B+ 模型部署。
- 提供模块化投机解码框架,统一支持 Medusa、Eagle、Prompt Lookup 等多种算法,在 1.12x–2.48x 吞吐提升的同时保证输出等价。
- 采用解耦 ViT-LLM 处理,将视觉编码与语言生成分离,实现多模态吞吐 1.86x–2.52x 提升。
- 已在生产中为淘宝、天猫、菜鸟等业务服务,并以开源形式发布。
方法
RTP-LLM 的系统架构由 Frontend、Master、Prefill Node、Decode Node、多层 Cache、Name Service 和 DP-Controller 组成,下图展示了各组件的拓扑关系及请求从入口到输出的完整路径。
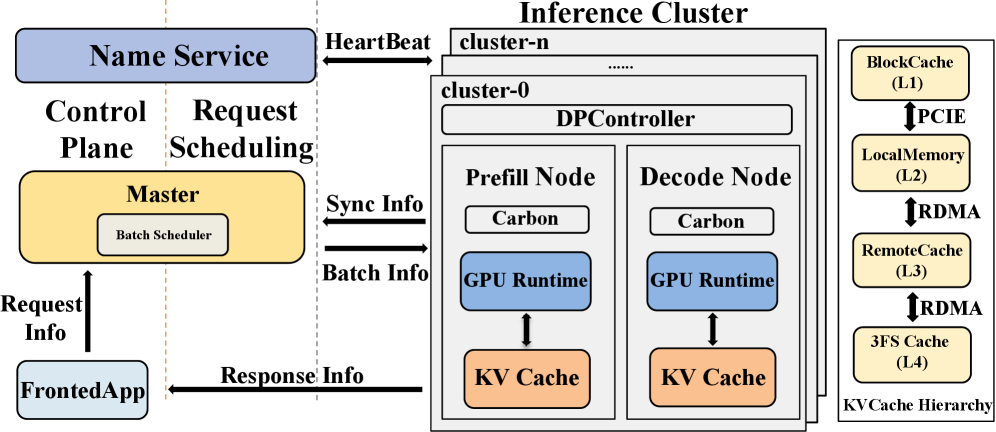
Master 负责全局流量调度与负载均衡,根据队列状态、KV Cache 占用和延迟目标动态分派请求;Prefill Node 以大 batch 最大化吞吐,Decode Node 以低延迟优化内存访问,两类节点独立扩缩。Name Service 维护节点注册与发现,DP-Controller 协调数据并行切分。
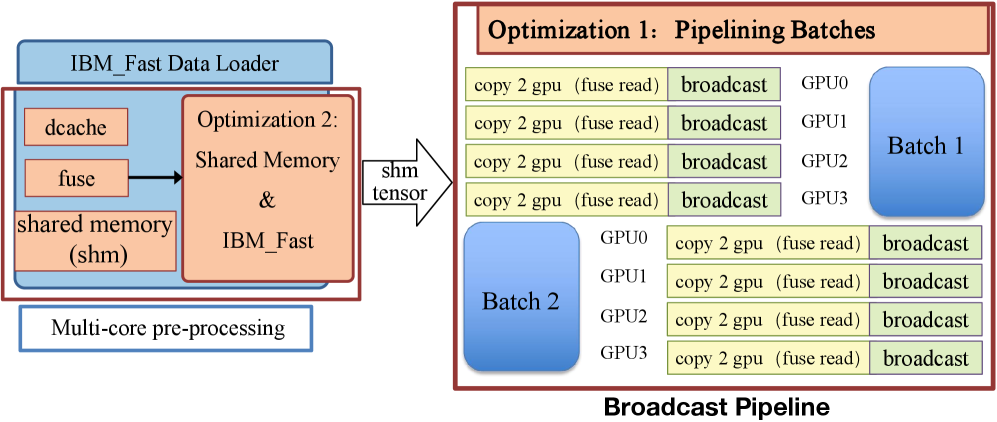
模型加载优化:如下图所示,RTP-LLM 采用文件顺序驱动 I/O(按存储顺序读取以减少随机寻道)、共享内存复用(多进程共享已加载权重,避免重复拷贝)、以及并行 I/O-通信重叠(权重加载与张量并行通信流水线化),三者共同将模型加载耗时从小时级压缩到分钟级。
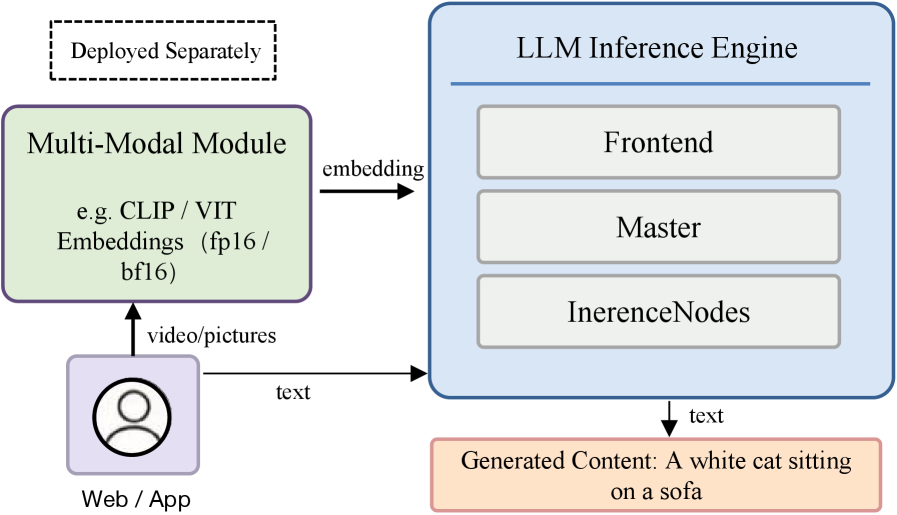
EPD 分离:对多模态模型,ViT 编码(Encode)、prefill 和 decode 被进一步拆分为三个独立阶段(EPD Disaggregation)。视觉编码器与 LLM 推理在独立资源上并行执行,消除串行等待。下图展示了实际部署中 ViT 模型的 EPD 物理拓扑,Encode 节点专门承载视觉特征提取,Prefill/Decode 节点专注语言部分。
流量调度与 KV Cache 管理:调度层实现本地 KV Cache 管理器(LRU 淘汰 + 前缀哈希匹配)、采样前缀哈希(避免全量哈希开销)、远程 KV Cache Manager(通过 RDMA 访问跨节点 cache)四级结构,配合前缀感知路由,将具有相同系统提示或 RAG 段落的请求优先调度到持有对应 cache 的节点。
量化:支持 Weight-Only 量化(AWQ)和 KV Cache 量化(FP8),在精度损失(PPL)可控前提下降低显存占用并提升 batch 吞吐。多级并行支持 Tensor / Data / Pipeline / Expert Parallelism,覆盖从稠密模型到 600B+ MoE。
实验
- 模型规模:8B–235B 参数,涵盖 Qwen3-8B、Qwen3-32B、Qwen2.5-14B-Instruct、Moonlight-16B-A3B、Qwen2.5-VL-7B-Instruct 等。
- Baseline:vLLM、SGLang(版本号论文未给出)。
- 数据集 / 负载:受控 benchmark(GQA 数据集用于多模态)+ 真实生产流量。
- 指标:模型加载时间、TTFT(P95)、Tokens/s(吞吐)、Batch Latency、GPU 显存利用率、KV Cache reuse 率。
- 硬件:文中提及 TP=2 配置(多模态实验),具体 GPU 型号论文正文被截断,未给出完整信息。
结果
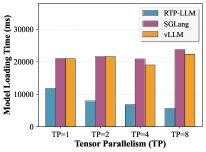
模型加载:如图 4 所示,针对 8B–32B 中等规模模型在不同 TP 配置下,RTP-LLM 相比 baseline 框架取得 1.4x–4.2x 加载加速,且 TP 越高加速越显著(更大 TP 时通信开销掩盖加载延迟的效果更明显)。结合 abstract,覆盖全部规模(8B–235B)时整体加速为 4.7x–6.3x(Figure 4 仅覆盖中等规模子集)。
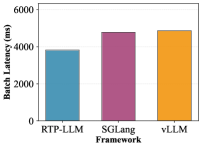
量化推理——Batch Latency:图 5 对比了 Qwen3-32B 在 AWQ(FP8)、FP8 KV Cache 和 Baseline 三种量化配置下的 batch 延迟与精度损失(PPL)。abstract 给出整体结论:量化推理下 batch latency 降低 35–40%,精度损失(PPL)处于可接受范围;图 5(d) 展示了各配置的 PPL 对比,支撑了"量化不显著损精度"的主张。
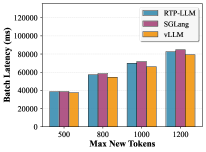
量化推理——TTFT 与 Tokens/s:图 6 展示相同 Qwen3-32B 配置下 TTFT 和吞吐对比,abstract 数字为量化推理 TTFT 改善 1.9x–3.0x。不同量化方案(AWQ vs FP8 KV Cache)在 TTFT 和 Tokens/s 上各有侧重,论文正文被截断,具体 per-config 数字未给出。
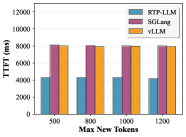
多模态推理:图 7 对比 Qwen2.5-VL-7B-Instruct 在 GQA 数据集上、TP=2 配置下,RTP-LLM vs SGLang vs vLLM 的 Batch Latency、TTFT、Tokens/s 及 GPU 显存利用率。abstract 给出整体结论:多模态吞吐提升 1.86x–2.52x,TTFT 降低 2.12x–2.36x;图 7 同时展示了 GPU 显存用量,RTP-LLM 分别显示 GPU0/GPU1 使用量,SGLang/vLLM 显示平均值,正文被截断,per-framework 具体数字未给出。
流量调度:生产流量下,相比基线调度策略,TTFT P95 延迟降低 35–37%,KV Cache reuse 率提升 215%,prefill 机器数减少 75%(abstract 数据,实验章节被截断)。
结论
RTP-LLM 最值得带走的 takeaway 是:在生产规模的 LLM serving 中,各优化技术的系统集成(调度 + Cache + PD 分离 + 加载)产生的协同收益,远超单点优化——215% cache reuse 提升背后是调度感知路由与分层 Cache 的联动,而非单独的前缀 Cache。这在 100M+ 用户的真实流量中得到验证,具有较强说服力。
边界:所有实验均在 Alibaba 自有业务场景和硬件配置上验证,具体 GPU 型号和网络拓扑未完整披露;模型覆盖 8B–235B 但以 Qwen 系列为主;开源版本与内部生产版本的功能差距未说明。abstract 称"4.7x–6.3x 加载加速",而图 4 显示中等规模模型为 1.4x–4.2x,两者不矛盾(前者覆盖更大模型),但读者需注意小模型(8B)的加速收益偏保守。缺少对长上下文(>128K)regime 下 KV Cache 分层策略的专项 ablation。
是否新瓶装旧酒
论文自述最相近前人工作:
- vLLM / PagedAttention(Kwon et al., 2023)——提供了 KV Cache 分页管理基础,RTP-LLM 在此之上扩展为分层多级(GPU→CPU→RDMA→分布式存储)并加入前缀感知调度。
- PD Disaggregation(Patel et al., 2024;Zhong et al., 2024;Qin et al., 2025)——RTP-LLM 直接复用了 PD 分离思想,进一步扩展为 EPD 三阶段以支持多模态。
- Speculative Decoding(Spector & Re, 2023;Xia et al., 2024)——RTP-LLM 贡献的是统一框架(Medusa/Eagle/Prompt Lookup 多算法集成),而非新解码算法本身。
独立判断:本文的核心价值是工业级系统集成,而非算法创新。PD 分离、投机解码、prefix caching、量化均有先例;RTP-LLM 的增量在于将这些技术打包进一个经过亿级流量验证的生产系统,并提供跨组件协同的调优经验。这与 SGLang、TensorRT-LLM 等系统论文的定位相近,属于"系统工程论文"而非"算法突破论文"——这不是缺点,但读者应对此定位有清晰预期。
尚未回答的问题
- PD 分离的网络开销 ablation 缺失:KV Cache 在 prefill→decode 节点间传输的带宽代价是否在长序列(>32K)下成为新瓶颈?论文未给出不同序列长度下的 PD 通信延迟分解。
- 分层 KV Cache 的 RDMA 层实测数据缺失:论文提及 GPU→CPU→RDMA→分布式存储四级,但实验中只验证了 cache reuse 总体提升,未给出各层命中率及延迟分解。
- 非 Qwen 系列模型的泛化性:所有 benchmark 以 Qwen 系列为主,对 LLaMA / Mixtral / Gemma 等架构的性能未报告。
- 投机解码在高并发下的退化曲线:论文正文提到"随并发增加,投机解码收益递减",但缺少具体的并发-吞吐曲线,无法判断实际生产中何时应关闭投机解码。
- 开源版与生产版差距:serving 超 1 亿用户的内部版本与开源发布版本的功能差异未说明,社区用户可复现的性能范围不明确。
原始摘要(中文翻译)
大型语言模型(LLM)已彻底变革了 AI 应用,但在规模化部署时面临重大挑战。我们提出 RTP-LLM——一款面向工业级 LLM 部署的高性能推理引擎,已在阿里巴巴集团全面落地,服务超过 1 亿用户。RTP-LLM 通过集成化设计解决了若干根本性瓶颈:借助文件顺序驱动 I/O 与并行 I/O-通信重叠优化模型加载;Prefill-Decode 分离架构将计算密集型 prefill 与内存受限型 decode 阶段物理解耦,结合分层多级 KV Cache 管理实现高效 cache 复用;此外,RTP-LLM 还集成了支持多种算法的模块化投机解码、自适应 KV Cache 量化、解耦多模态处理,以及多级并行支持。我们在涵盖 8B–235B 参数的多样模型架构上进行了全面评估,同时采用受控 benchmark 与真实生产负载。结果表明,RTP-LLM 全面优于 vLLM 和 SGLang:模型加载加速 4.7x–6.3x;生产流量调度中 TTFT P95 延迟降低 35–37%,cache reuse 提升 215%;投机解码与多模态推理吞吐分别提升 1.12x–2.48x 和 1.86x–2.52x;量化推理下 batch latency 降低 35–40%,TTFT 改善 1.9x–3.0x。RTP-LLM 经生产验证的架构与开源可用性,使其成为工业级 LLM 部署的综合解决方案。