arXiv: 2605.29639 · PDF
Authors: Boyu Tan, Jiarui Guo, Zongwei Lv, Hanbo Sun, Tong Yang, Kan Liu, Xinfei Shi, Zetao Hu, Yaxin Yu, Chi Zhang, Jianning Zhang, Xi Yang, Wei Zhang, Bo Cai, Silu Zhou, Xiyu Wang, Na He, Yinghao Yu, Wending Bao, Guiyang Huang, Yuxing Yuan, Juncheng Yin, Nan Wang, Lin Yang, Zechao Zhang, Lu Chen, Guoding Li, Tao Lan, Lin Qu
Affiliations: Alibaba Group, Peking University, Zhejiang University
Primary category: cs.OS · all: cs.OS
Matched keywords: large language model, llm, inference, serving, kv cache, parallelism, quantization, speculative decoding, throughput, latency
TL;DR
RTP-LLM is Alibaba’s production LLM inference engine, serving 100M+ users, that integrates prefill-decode disaggregation, multi-tiered KV cache, speculative decoding, and model-loading optimizations to deliver 4.7×–6.3× faster loading, 35–40% latency reduction, and substantial throughput gains over vLLM and SGLang.
Motivation
Industrial LLM deployment at scale faces four concrete bottlenecks that no single existing system fully addresses. First, GPU utilization collapses under dynamic workloads: input lengths range from short queries to 128K+ tokens, and the memory-bound nature of autoregressive decode leaves compute idle. Second, KV cache grows linearly with sequence and batch size and quickly dominates VRAM, blocking concurrency. Third, architectural heterogeneity—dense models up to 235B, MoE models over 600B, and multimodal ViT+LLM combos—requires coordinated execution that frameworks like vLLM (single-node, homogeneous focus) were not designed for. Fourth, operational fragility: enterprises need minute-level 600B+ model reloading for continuous updates, but existing systems require hours. Teams operating Taobao, Tmall, and Cainiao-scale traffic currently must over-provision prefill machines and accept high tail latency because prefill and decode phases share resources and cannot scale independently. vLLM introduced PagedAttention and TensorRT-LLM delivered kernel optimizations, but both treat components in isolation. The authors argue the gap is systemic: no open production system integrates disaggregation, hierarchical cross-tier caching, multimodal decoupling, and fast model loading into a single coherent stack.
Key Ideas
- Optimized model loading via file-order-driven I/O, shared memory reuse, and parallel I/O–communication overlap, targeting minute-level deployment of 600B+ models.
- Prefill-Decode (PD) Disaggregation decouples compute-intensive prefill from memory-bound decode onto dedicated nodes, enabling independent scaling.
- Hierarchical multi-tiered KV cache spanning GPU → CPU → remote CPU (RDMA) → distributed storage, with hash-based prefix matching for cache reuse across requests.
- Modular speculative decoding supporting Medusa, Eagle, and Prompt Lookup algorithms within a unified propose/score/verify framework.
- EPD (Encode-Prefill-Decode) disaggregation for multimodal models, separating ViT encoding from LLM prefill and decode to match their different compute profiles.
- Adaptive KV cache quantization (weight-only and KV cache quantization) reducing memory footprint while maintaining precision.
Method
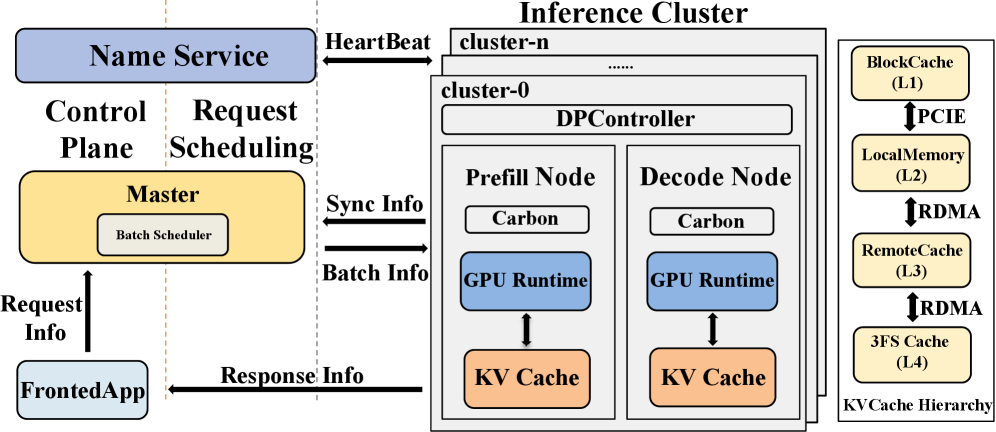
RTP-LLM’s architecture (Figure 1) comprises a Frontend Application, Master, Prefill Nodes, Decode Nodes, Multi-Tiered Cache, Name Service, and DP-Controller. The master orchestrates traffic scheduling with load balancing that continuously reprioritizes requests based on queue state, KV cache footprint, and latency targets.
The overall system architecture shows how prefill and decode nodes are physically separated, with the multi-tiered cache connecting them. The master layer handles request routing between nodes, while the name service enables dynamic node discovery. This disaggregation is the core topology enabling independent scaling of the two computationally distinct phases.
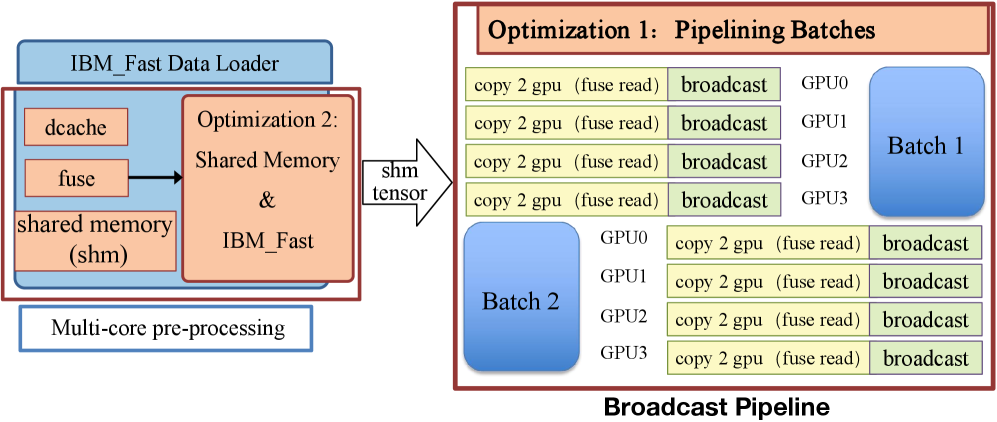
Model Loading (Figure 2): Three techniques combine—file-order-driven I/O aligns disk reads to filesystem layout, parallel I/O-communication overlapping hides network transfer latency behind disk reads, and shared memory reuse avoids redundant allocation during hot updates.
The model loading optimizations address the operational fragility challenge (Challenge IV). File-order I/O, overlapped parallel transfers, and shared memory reuse together reduce the serialized loading bottleneck that forces long cold-start times on 600B+ models.
KV Cache: A local manager handles GPU/CPU paging; prefix matching uses sampled prefix hashing to avoid full-key comparison overhead; a remote KV cache manager server handles RDMA-based cross-node transfers. Scheduling integrates cache match scores with load signals to co-route requests to nodes that already hold their prefix cache.
Speculative Decoding: A propose model $M_q$ generates $k$ candidate tokens; a score model $M_p$ evaluates all $k$ in parallel; a verification stage accepts tokens based on probability distributions. This transforms sequential decode into parallel verification.
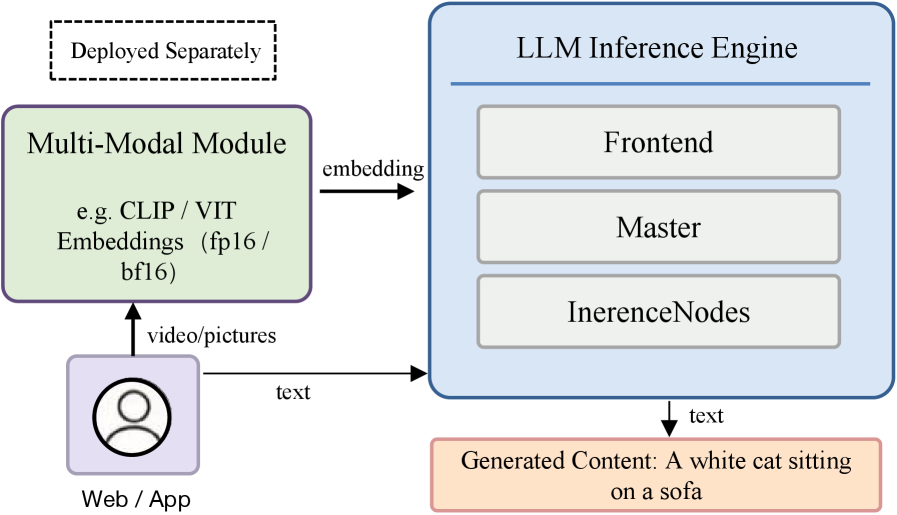
EPD Disaggregation (Figure 3): For multimodal models, the ViT encoder runs on dedicated encode nodes, passing visual embeddings to prefill nodes, which then hand off KV cache to decode nodes. This separates the vision encoder’s compute pattern from the LLM’s.
The EPD architecture physically separates ViT encoding, LLM prefill, and LLM decode onto distinct node pools. This prevents the bursty, compute-heavy vision encoding from blocking the latency-sensitive decode pipeline, which is the mechanism behind the reported 1.86×–2.52× multimodal throughput improvement.
Experiments
- Models: Qwen3-32B, Qwen3-8B, Qwen2.5-14B-Instruct, Moonlight-16B-A3B (medium-scale, 8B–32B), up to 235B (abstract); Qwen2.5-VL-7B-Instruct (multimodal).
- Baselines: vLLM, SGLang.
- Metrics: Model loading time, TTFT (P95), tokens/s, batch latency, GPU memory usage, cache reuse ratio, prefill machine count reduction.
- Hardware: Multi-GPU (TP=1, 2, 4, 8 configurations); production traffic from Taobao/Tmall/Cainiao deployments.
- Quantization configs tested: AWQ (FP8), FP8 KV Cache, BF16 baseline.
Results
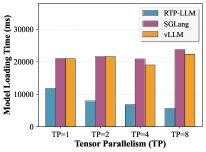
Model Loading (Figure 4): RTP-LLM achieves 1.4×–4.2× speedup over baseline frameworks for medium-scale models (8B–32B), with the gap widening at higher TP configurations. The abstract reports 4.7×–6.3× speedup across the full model range tested.
Figure 4 compares loading time in seconds for Qwen3-32B, Qwen3-8B, Qwen2.5-14B-Instruct, and Moonlight-16B-A3B across TP=1/2/4/8. RTP-LLM’s file-order I/O and parallel overlap are the mechanism; the figure shows that at higher TP (more GPUs loading simultaneously), RTP-LLM’s advantage grows, confirming that parallelism amplifies the I/O optimization.
Quantized Inference (Figures 5 & 6): For Qwen3-32B, quantized configurations (AWQ FP8 and FP8 KV Cache) show 35–40% batch latency reduction and 1.9×–3.0× TTFT improvement versus BF16 baseline, with precision loss (PPL) remaining within acceptable bounds.
Figure 5 shows batch latency (ms) and perplexity (PPL) for Qwen3-32B across AWQ(FP8), FP8 KV Cache, and BF16 baseline configurations. AWQ and FP8 KV Cache both reduce batch latency substantially while PPL degradation stays modest—validating that the adaptive quantization preserves output quality.
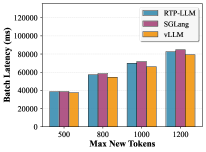
Figure 6 shows TTFT and tokens/s for the same Qwen3-32B configurations. Quantized variants consistently improve TTFT (the first-token latency) and tokens/s throughput, with the gains corroborating the 1.9×–3.0× TTFT improvement reported in the abstract.
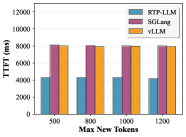
Multimodal (Figure 7): For Qwen2.5-VL-7B-Instruct on GQA with TP=2, RTP-LLM outperforms both SGLang and vLLM on batch latency, TTFT, and tokens/s, while GPU memory usage per GPU is also reported separately for GPU0 and GPU1.
Figure 7 compares RTP-LLM, SGLang, and vLLM across four metrics (batch latency, TTFT, tokens/s, GPU memory) for the 7B VL model. The EPD disaggregation mechanism drives the improvement; the abstract quantifies the overall multimodal gain as 1.86×–2.52× throughput improvement.
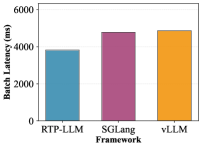
Production Traffic Scheduling: 35–37% TTFT P95 latency reduction, 215% cache reuse improvement, and 75% reduction in prefill machine count (abstract-only; full text describes mechanism but does not reproduce a table for these numbers).
Conclusion
RTP-LLM demonstrates that integrating disaggregation, hierarchical caching, speculative decoding, and I/O optimization into a single coherent system yields compounding gains that isolated component optimizations miss. The most compelling single finding is the 75% reduction in prefill machine count from hierarchical prefix caching, which translates directly to infrastructure cost at Alibaba scale. Honest limits: the evaluations cover Alibaba’s own hardware and traffic profiles (Taobao/Tmall/Cainiao); generalizability to other cloud providers or latency SLO regimes is untested. Model scale tops out at 235B in benchmarks; the 600B+ loading claims are stated but not benchmarked in the paper. Multimodal experiments cover only one model family (Qwen2.5-VL-7B). No ablation isolates the contribution of individual components (e.g., what fraction of TTFT gain comes from disaggregation alone versus prefix caching).
Novelty Check
Authors’ own framing: The paper positions RTP-LLM as a systems integration contribution rather than an algorithmic novelty. Related work explicitly cites vLLM (PagedAttention), SGLang, TensorRT-LLM, Mooncake, and DistServe as closest prior work. The claimed delta is holistic production integration—no existing open system combines all five subsystems (PD disaggregation + multi-tier KV cache + speculative decoding + fast loading + multimodal EPD) with battle-tested reliability.
Independent assessment: Each individual component has clear prior art—PD disaggregation appears in Splitwise/DistServe/Mooncake; prefix caching in SGLang and vLLM; speculative decoding via Medusa/Eagle. The paper’s real contribution is the engineering integration and production validation at scale, not novel algorithms. This is closer to a systems paper in the MLSys tradition (like the original vLLM paper) than an algorithmic advance. That framing is honest and the production scale (100M users, measured prefill machine savings) lends genuine credibility.
Open Questions
- Component ablations: Which subsystem contributes most to the production TTFT reduction—disaggregation, prefix caching, or load balancing? No controlled ablation is provided.
- Non-Alibaba hardware: All production numbers come from Alibaba’s infrastructure; does the EPD design generalize to heterogeneous GPU clusters (e.g., mixed H100/A100)?
- 600B+ loading: The abstract and intro claim minute-level loading for 600B+ models, but no benchmark table covers this scale—only 8B–32B models appear in Figure 4.
- Speculative decoding at high concurrency: The paper acknowledges speculative decoding benefits diminish as concurrency increases; the exact crossover point is not quantified.
- Fault tolerance overhead: Enterprise-grade fault tolerance and rolling updates are mentioned but not evaluated for latency/throughput cost.
Original abstract
arXiv:2605.29639v1 Announce Type: new Abstract: Large Language Models (LLMs) have revolutionized AI applications, but deploying them at scale presents significant challenges. We present RTP-LLM, a high-performance inference engine for industrial-scale LLM deployment, successfully deployed across Alibaba Group serving over 100 million users. RTP-LLM addresses fundamental bottlenecks through integrated design. It optimizes model loading via file-order-driven I/O and parallel I/O-communication overlapping. The Prefill-Decode Disaggregation architecture decouples compute-intensive prefill from memory-bound decode phases, combined with hierarchical multi-tiered KV cache management enabling efficient cache reuse. In addition, RTP-LLM incorporates modular speculative decoding supporting multiple algorithms, adaptive KV cache quantization, and decoupled multimodal processing, with support for multi-level parallelism. Comprehensive evaluations across diverse model architectures (8B-235B parameters) have been conducted, where both controlled benchmarks and real production workloads are used. The results demonstrate RTP-LLM’s superior performance against vLLM and SGLang: 4.7x-6.3x model loading speedup, 35-37% TTFT P95 latency reduction with 215% cache reuse improvement in production traffic scheduling, 1.12x-2.48x and 1.86x-2.52x throughput improvements in speculative decoding and multimodal inference, respectively, and 35-40% batch latency reduction with 1.9x-3.0x TTFT improvement in quantized inference. RTP-LLM’s production-proven architecture and open-source availability make it a comprehensive solution for industrial LLM deployment.