arXiv: 2605.29307 · PDF
作者: Alireza Salemi, Chang Zeng, Atharva Nijasure, Jui-Hui Chung, Razieh Rahimi, Fernando Diaz, Hamed Zamani
单位: University of Massachusetts Amherst, Princeton University, Carnegie Mellon University
主分类: cs.CL · 全部: cs.AI, cs.CL, cs.IR, cs.LG
命中关键词: large language model, llm, agent, retrieval, reasoning, serving
TL;DR
GrepSeek 让紧凑型 LLM 通过可执行 shell 命令(如 rg/grep)直接搜索原始语料库,绕过预计算检索索引,在 7 个开放域 QA 基准上取得最强 F₁ 和 Exact Match,且端到端延迟约 8.6 秒/查询。
Motivation
现有 LLM 搜索 agent(如 Search-R1 系列)依赖预计算的倒排或稠密向量索引,存在三个根本限制:文本分块粒度固定(索引建立前必须确定 chunk 边界,无法事后调整);语义混淆与实体歧义(稠密检索在多跳推理时会把不同实体的相关文档混为一谈);运营成本高(需要存储和维护大型向量索引,内存占用随语料规模线性增长)。
直接与原始语料交互(DCI)的思路虽然存在(同期工作 Li et al. 2026、Sen et al. 2026),但这些方案依赖 Claude 等大型闭源模型在推理时提示驱动搜索,单条查询有时需要超过一小时,对生产场景完全不可行。
受苦的主要是需要精确实体匹配、符号模式搜索或跨文档桥接实体的多跳 QA 团队和知识密集型 agent runtime。他们今天的 workaround 是用稠密检索 + 多轮 RAG 凑合,但在 2WikiMultihopQA、MuSiQue 这类需要精确词法过滤的数据集上效果明显受限。让这件事现在值得做的前置条件是:RL 训练小模型的技术(GRPO)已足够成熟,可用来教会紧凑模型学会正确的 shell 命令搜索策略,而不依赖超大闭源模型。
核心观点
下图直观对比了传统 RAG 与 DCI 两种范式的架构差异——左侧 RAG 依赖预计算索引,右侧 DCI 通过 shell 命令直接在分片语料上并行搜索。
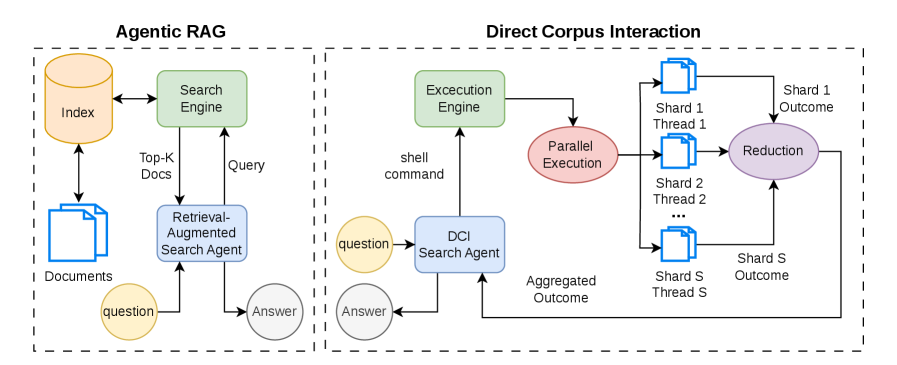
- 无索引直接搜索:agent 把语料库视为环境,通过可执行 shell 命令(
rg、grep、awk等)任意粒度检索,无需预计算文档表示。 - 两阶段训练流水线:冷启动 SFT(Tutor + Planner 生成已验证轨迹)+ GRPO 强化学习,解决直接在大语料上做 RL 的不稳定问题。
- 语义保持分片并行执行引擎:将 shell pipeline 分发到多个语料分片并行执行,与顺序执行保持 byte-exact 等价,加速达 7.6×。
- 紧凑模型:将 DCI 从推理时大模型提示策略转变为小型 agent 的学习能力,端到端延迟约 8.6 秒/查询(A100 80GB)。
- 7 基准最强综合表现:在 NQ、HotpotQA、2WikiMultihopQA、MuSiQue 4 个数据集上取得最佳 F₁。
方法
GrepSeek 基于 ReAct 框架运行,agent 策略 πθ 在每步根据问题 q 和历史轨迹 τ<i 生成推理链 tᵢ 和 shell 命令动作 aᵢ,执行引擎返回观测 oᵢ,循环直至输出答案。动作空间为 Unix 工具(rg、grep、find、sed、awk、head、tail 等),实际主要依赖 rg 和 head。
下图展示了 GrepSeek 的完整迭代搜索工作流——agent 多轮发出 shell 命令、接收语料返回片段、逐步缩小证据范围、最终生成答案,整个过程不经过任何检索索引。
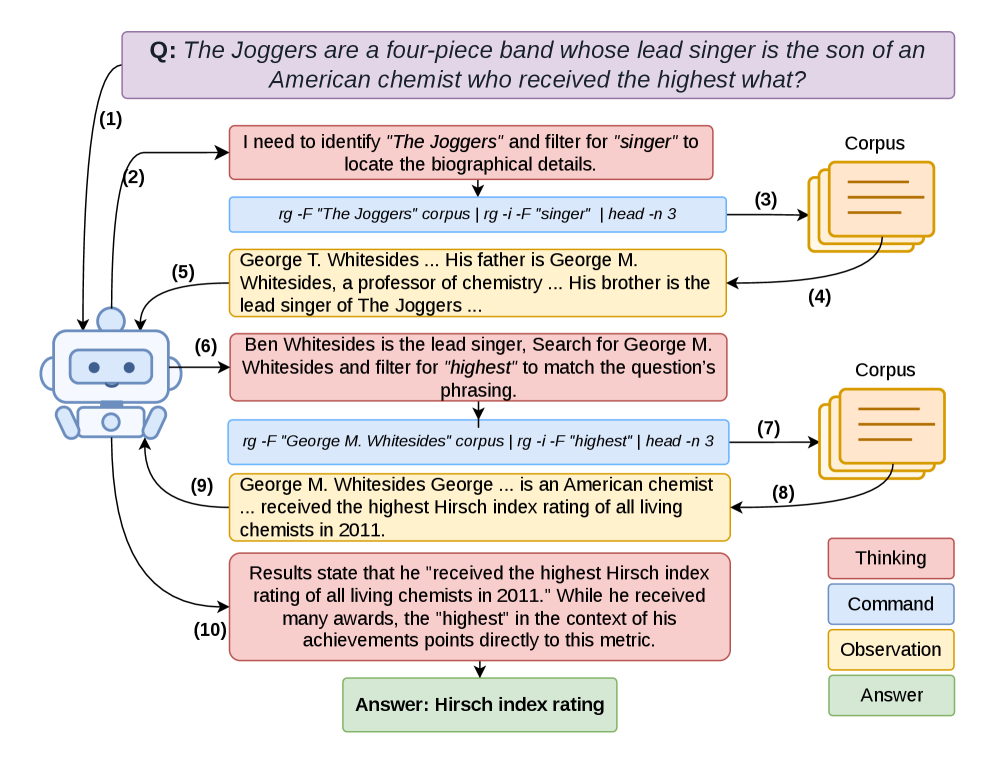
冷启动数据生成(两阶段):
- Backward Phase(Tutor):已知正确答案,从答案出发逆向构造 shell 命令链,确保每条命令都能在语料中找到支撑证据;对复杂多跳问题逐跳定位桥接实体。
- Forward Phase(Planner):将验证过的后向链转为 agent 可见历史驱动的前向轨迹,Planner 不知道答案,模拟推理时行为,Tutor 负责对齐。
- 质量过滤:自动过滤无法通过因果验证的轨迹。
GRPO 强化学习:SFT 初始化策略后,用 Group Relative Policy Optimization 进一步优化,奖励由正确性奖励(token-level F₁/EM)和格式奖励组合而成。
分片并行执行引擎:语料分成多个 shard,兼容的 shell pipeline(如纯过滤型 rg | head)在所有 shard 上并行执行,结果合并策略按 pipeline 类型(过滤/计数/排序)确定,通过 RAM 驻留语料和确定性执行标志保证 byte-exact 等价。
实验
数据集:7 个开放域 QA 基准:
- 单跳:Natural Questions (NQ)、TriviaQA、PopQA
- 多跳:HotpotQA、2WikiMultihopQA、MuSiQue、Bamboogle
Baseline:标准 RAG 系统、未训练 agentic 框架、以及用 RL 优化但使用稠密/稀疏检索器的搜索 agent(Search-R1 with E5、BM25、Qwen3-Emb-4B)。
指标:token-level F₁、Exact Match (EM)。
硬件:单卡 NVIDIA A100 80GB,32 CPU 核,32GB 系统 RAM。
结果
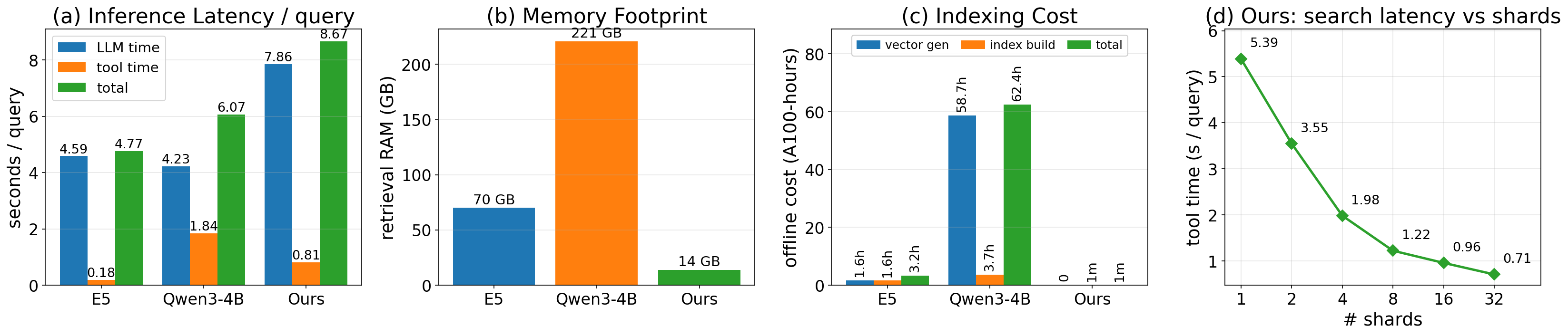
效率对比(Figure 3):
图 3 从四个维度量化了 GrepSeek 相对稠密检索 baseline(E5、Qwen3-4B)的效率优势:推理延迟分解(LLM 生成 vs 工具执行)、索引内存占用、离线建索引成本、运行期搜索成本。GrepSeek 的核心优势在于无需构建和存储向量索引,因此 RAM 占用和离线成本显著低于稠密检索;论文正文未在该图给出具体数值,但分片并行引擎将平均搜索延迟从顺序执行的 5.39 秒降至 0.71 秒(7.6× 加速),使端到端延迟降至约 8.6 秒/查询。
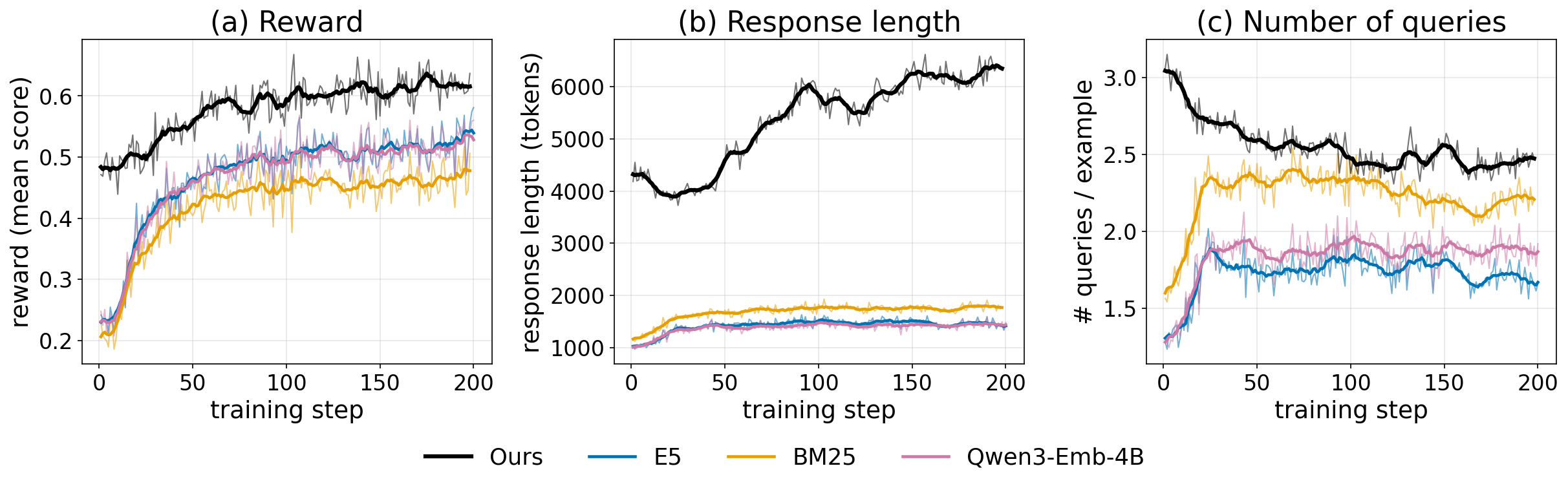
训练动态(Figure 5):
训练曲线显示,在 200 步 GRPO 训练中 GrepSeek 全程获得高于所有 Search-R1 baseline 变体(E5、BM25、Qwen3-Emb-4B)的平均奖励,同时 agent 搜索查询次数随训练趋于稳定,表明模型学会了更有目的性的命令策略。
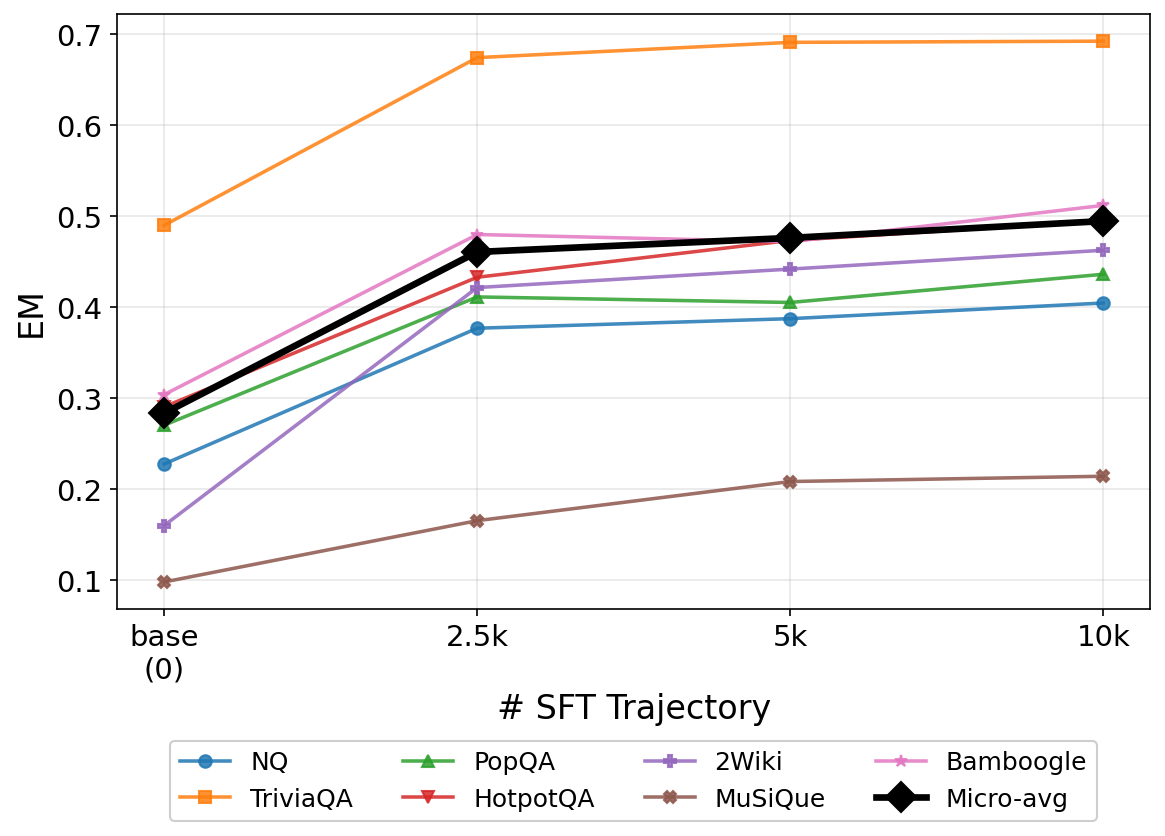
Ablation——SFT 轨迹数量(Figure 4):
去掉 GRPO(w/o GRPO)后,多数数据集 F₁ 下降(如某数据集从 0.6231 降至 0.3879);去掉 SFT 冷启动(w/o SFT)下降更明显(同数据集降至 0.2896),证明两阶段训练缺一不可。图 4 进一步显示 SFT 轨迹数量对 RL 后 F₁ 有单调正影响,但边际收益递减。
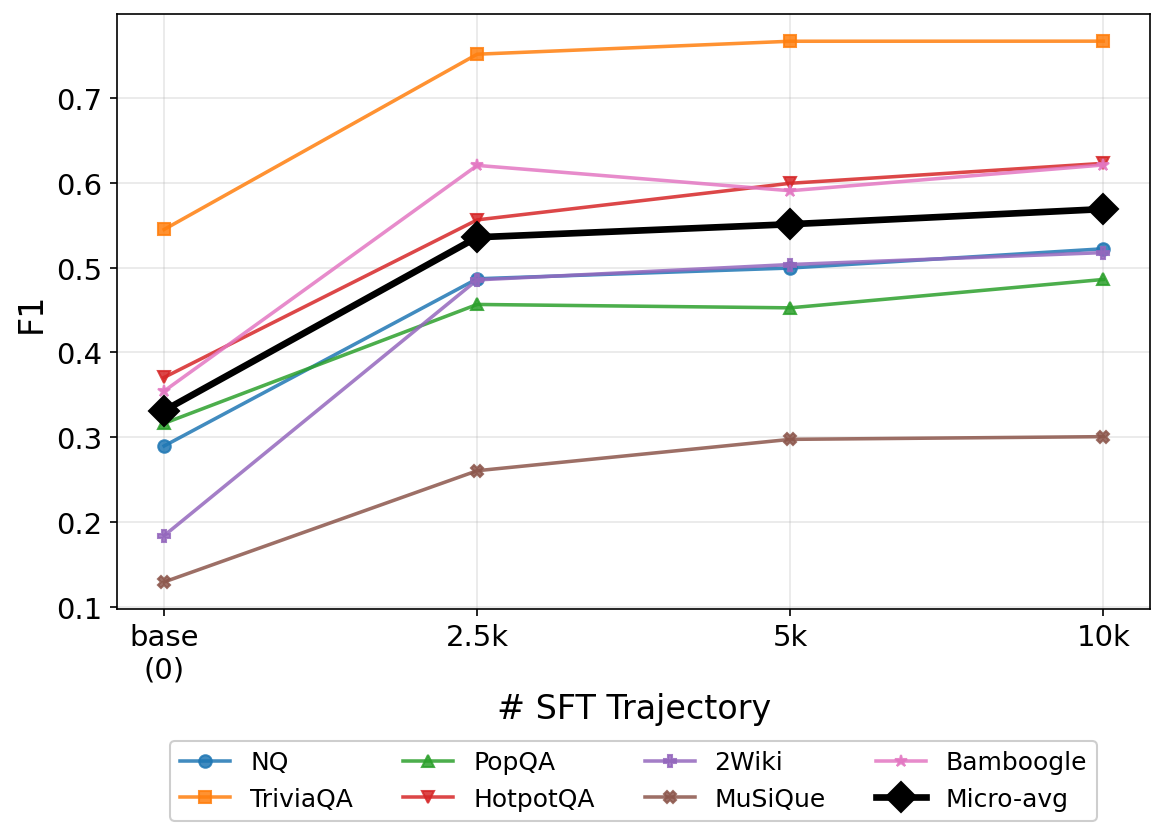
SFT 轨迹对 EM 的影响(Figure 17):
与 F₁ 趋势一致,更多 SFT 轨迹在 RL 后同样带来更高 EM,具体数值详见附录 Figure 17。
主表:GrepSeek 在 7 个基准中的 4 个(NQ、HotpotQA、2WikiMultihopQA、MuSiQue)上取得最佳 token-level F₁,多跳数据集上提升最显著(论文正文因截断未给出完整对比数字,上述排名来自 abstract 及 Introduction 明确陈述)。
结论
核心 takeaway:在精确实体匹配和多跳推理场景下,训练紧凑 LLM 通过 shell 命令直接操作原始语料是切实可行且极具竞争力的检索范式,7.6× 加速引擎使其端到端延迟降至约 8.6 秒,已接近生产可用门槛。
成立范围:在单卡 A100(80GB)+ 32GB RAM 的配置下、英文开放域 QA 语料上验证;语料以每行一个文档的格式存储,未在其他语言或结构化/多模态语料上测试。
标题暗示但实验未证明:标题称"Direct Corpus Interaction"为通用范式,但实验仅在 Wikipedia 风格的英文文本语料和 decoder-only 紧凑模型上验证;对代码库、多语言或实时更新语料的适用性未涉及。
缺失 ablation:未对比不同 shell 命令集合(如仅用 grep vs 完整工具箱)的影响;未报告 GrepSeek 完整主表的具体数字与各 baseline 的逐行 delta(正文被截断);对语义变体查询(surface-form variation)的降级程度未做系统量化。
是否新瓶装旧酒
论文自述最相近前人工作:
- Li et al. (2026) 和 Sen et al. (2026):同期独立提出 DCI,用提示大型闭源模型(Claude)驱动 shell 搜索,但未训练小模型,延迟可达一小时以上。GrepSeek 的 delta 是训练紧凑模型 + 高效并行引擎,将其从"研究演示"推向"生产可行"。
- Search-R1 系列(稠密/稀疏检索器 + GRPO):GrepSeek 将相同 RL 优化范式应用于无索引直接搜索,区别在于检索接口。
独立判断:DCI 思路(用 grep 等工具直接搜索原始文本)在代码搜索领域早有先例(如 Wang et al. 2026 的代码 agent),GrepSeek 的真实创新点在于将其系统化地移植到开放域文本 QA 并配套解决了训练不稳定和搜索延迟两大工程问题。不是换名重做,有明确工程贡献,但核心概念的"首次"归属应属 Li et al. / Sen et al.,作者也明确承认了这一点。
尚未回答的问题
- 语料规模上限:实验使用 Wikipedia 量级语料,更大语料(万亿 token 级)下分片并行引擎是否仍能维持 7.6× 加速比和 byte-exact 等价?
- 语义变体的定量边界:论文定性指出 DCI 在 surface-form variation 查询上有降级,但未给出不同 OOV/paraphrase 程度下的系统性曲线。
- 混合检索策略:DCI 与稠密检索互补,但缺少将两者路由融合的 ablation(何时用 DCI,何时用向量检索?)。
- 多语言 / 多模态:全部实验限于英文文本语料,其他语言或含表格 / 代码的混合语料上的泛化性未验证。
- GRPO 样本效率:仅 200 步训练即收敛,但冷启动数据集的生成成本(Tutor + Planner API 调用数量)未披露,影响对可复现性的判断。
原始摘要(中文翻译)
大型语言模型(LLM)搜索 agent 通过多轮推理和信息检索,在知识密集型语言任务上展现出强大潜力。现有系统大多通过检索器访问信息:检索器接受关键词或自然语言查询,并利用预计算文档表示构建的索引返回排序文档列表。本文探索了一种互补视角——搜索 agent 将语料库本身视为搜索环境,通过发出可执行 shell 命令在其中寻找证据。我们提出 GrepSeek,一种经过优化的直接语料交互(DCI)搜索 agent,训练紧凑型搜索 agent 从大型文本语料库中查找、过滤并组合证据。为解决在大型语料上直接用强化学习学习行为的不稳定性,我们提出两阶段训练流水线:首先,利用感知答案的 Tutor 和不感知答案的 Planner 构建冷启动数据集,生成经验证的、因果一致的搜索轨迹;其次,使用群体相对策略优化(GRPO)对初始化策略进行精化,使 agent 能够通过与语料库的直接交互改进其面向任务的搜索行为。为使 DCI 在规模上切实可用,我们进一步采用语义保持的分片并行执行引擎,在保持与顺序 shell 命令执行字节级等价的同时,将基于 shell 的检索加速最多 7.6 倍。在七个开放域问答基准上的实验表明,GrepSeek 达到最强的整体 token 级 F₁ 和 Exact Match。我们的分析同时指出了纯词法交互在存在大量表面形式变体的查询上的局限性,表明 DCI 是一种实用且极具竞争力的搜索 agent 方法,可在现实场景中对现有检索范式形成有效补充。