arXiv: 2605.29307 · PDF
Authors: Alireza Salemi, Chang Zeng, Atharva Nijasure, Jui-Hui Chung, Razieh Rahimi, Fernando Diaz, Hamed Zamani
Affiliations: University of Massachusetts Amherst, Princeton University, Carnegie Mellon University
Primary category: cs.CL · all: cs.AI, cs.CL, cs.IR, cs.LG
Matched keywords: large language model, llm, agent, retrieval, reasoning, serving
TL;DR
GrepSeek trains a compact LLM to search large text corpora by issuing shell commands (rg, grep) directly against raw text, bypassing pre-computed indices, using a cold-start SFT + GRPO two-stage pipeline and a 7.6× sharded-parallel execution engine.
Motivation
Existing RAG systems retrieve from pre-built indices over fixed text chunks, constraining retrieval granularity and forcing all queries through the same pre-determined document boundaries. Multi-hop reasoning is especially hurt: retrievers conflate entity semantics across bridge documents, degrading precision. Contemporary DCI work (Li et al. 2026; Sen et al. 2026) showed shell-command-based corpus access can bypass these constraints, but those systems prompt large proprietary models like Claude at inference time, sometimes requiring over one hour per query—operationally infeasible. The gap is the absence of a trained compact model that has internalized DCI as a capability. A second blocker is training instability: the authors report that naive RL on a large raw corpus caused out-of-memory failures even on systems with up to 1,024 GB of RAM, because the agent learns to retrieve excessively large corpus segments. These two barriers—prohibitive inference cost and RL instability—motivate GrepSeek’s two-stage pipeline and parallel execution engine.
Key Ideas
The figure below contrasts the two paradigms: left shows index-based RAG returning fixed document chunks; right shows GrepSeek issuing shell commands against the raw corpus and aggregating results through a parallel engine—no index required.
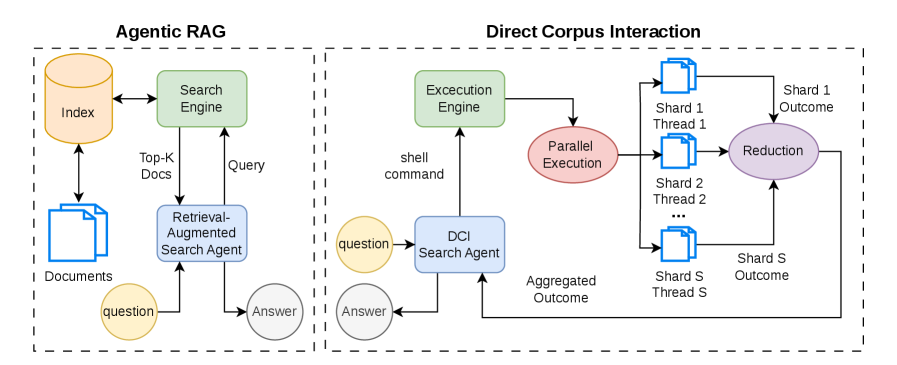
This side-by-side makes concrete the key architectural claim: DCI eliminates index construction and RAM overhead entirely while enabling arbitrary-granularity retrieval via exact string matching.
- DCI as a learned capability: trains a compact LLM on shell-command search rather than prompting a large proprietary model.
- Two-stage training: cold-start SFT stabilizes initial behavior; GRPO RL refines task-oriented search strategy.
- Answer-aware Tutor + answer-blind Planner: Tutor constructs verified backward evidence chains; Planner converts them into causally valid forward trajectories.
- 7.6× sharded-parallel engine: reduces average search latency from 5.39s to 0.71s with byte-exact output equivalence.
- Best overall F1/EM across 7 QA benchmarks, with top F1 on 4 of 7 datasets.
Method
The DCI agent operates in the ReAct framework: each step emits a shell command (primarily rg and head) via <tool_call>, the execution engine returns corpus output via <tool_response>, and the loop runs for at most T steps before a final <answer> tag.
Cold-start (Algorithm 1): For each training question, the answer-aware Tutor decomposes it into sub-queries and builds a backward chain from answer to question, verifying that each shell command retrieves supporting corpus evidence. The answer-blind Planner replays this chain forward, generating causal reasoning traces as if solving the task at inference time. Automatic quality filtering removes failed trajectories.
GRPO: The SFT-initialized policy is refined with Group Relative Policy Optimization using a combined correctness (token-level F1/EM) and format reward.
Efficient execution: The sharded-parallel engine partitions the corpus across shards, fans out compatible pipelines in parallel, and merges results deterministically. A persistent daemon eliminates per-query startup overhead.
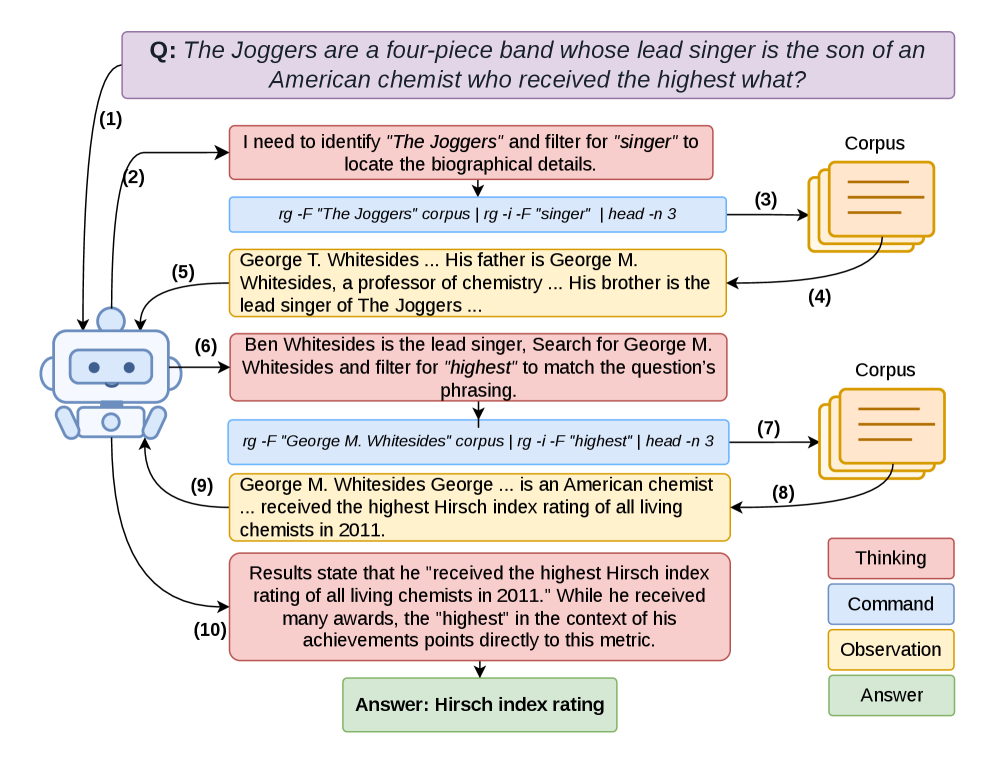
Figure 2 shows a representative trajectory: the agent iteratively refines rg commands, inspects partial results, and synthesizes a final answer—illustrating the multi-turn corpus interaction loop and how the Planner’s forward reasoning structure plays out at inference time.
Experiments
Datasets: 7 open-domain QA benchmarks — single-hop: NQ, TriviaQA, PopQA; multi-hop: HotpotQA, 2WikiMultihopQA, MuSiQue, Bamboogle.
Baselines: Search-R1 variants with E5, BM25, Qwen3-Emb-4B retrievers; untrained agentic frameworks; dense RAG (E5, Qwen3-4B).
Hardware: Single NVIDIA A100 80GB GPU, 32 CPU cores, 32GB RAM.
Metrics: Token-level F1 and Exact Match (EM).
Results
GrepSeek achieves best token-level F1 on 4 of 7 benchmarks (NQ, HotpotQA, 2WikiMultihopQA, MuSiQue) with statistically significant improvements on several datasets (Introduction). The sharded-parallel engine cuts average search latency from 5.39s → 0.71s (7.6×), bringing end-to-end per-query latency to ~8.6s on a single A100 (Introduction).
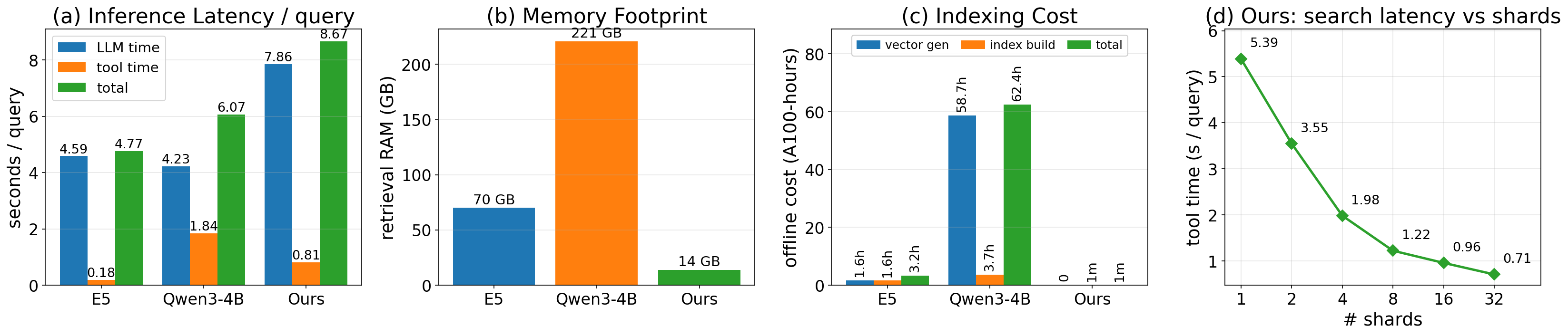
Figure 3 (a–c) compares inference latency, RAM footprint, and offline indexing cost against E5 and Qwen3-4B dense baselines. GrepSeek eliminates index RAM and construction cost entirely; its latency disadvantage relative to dense retrieval is in LLM generation time, not tool execution—which the 7.6× engine already brings to 0.71s average.
The ablation table (body text, near Figure 3 mention) shows removing GRPO yields F1 scores of ~0.39/0.64 on two datasets, and removing SFT drops further to ~0.29/0.55, confirming both training stages contribute.
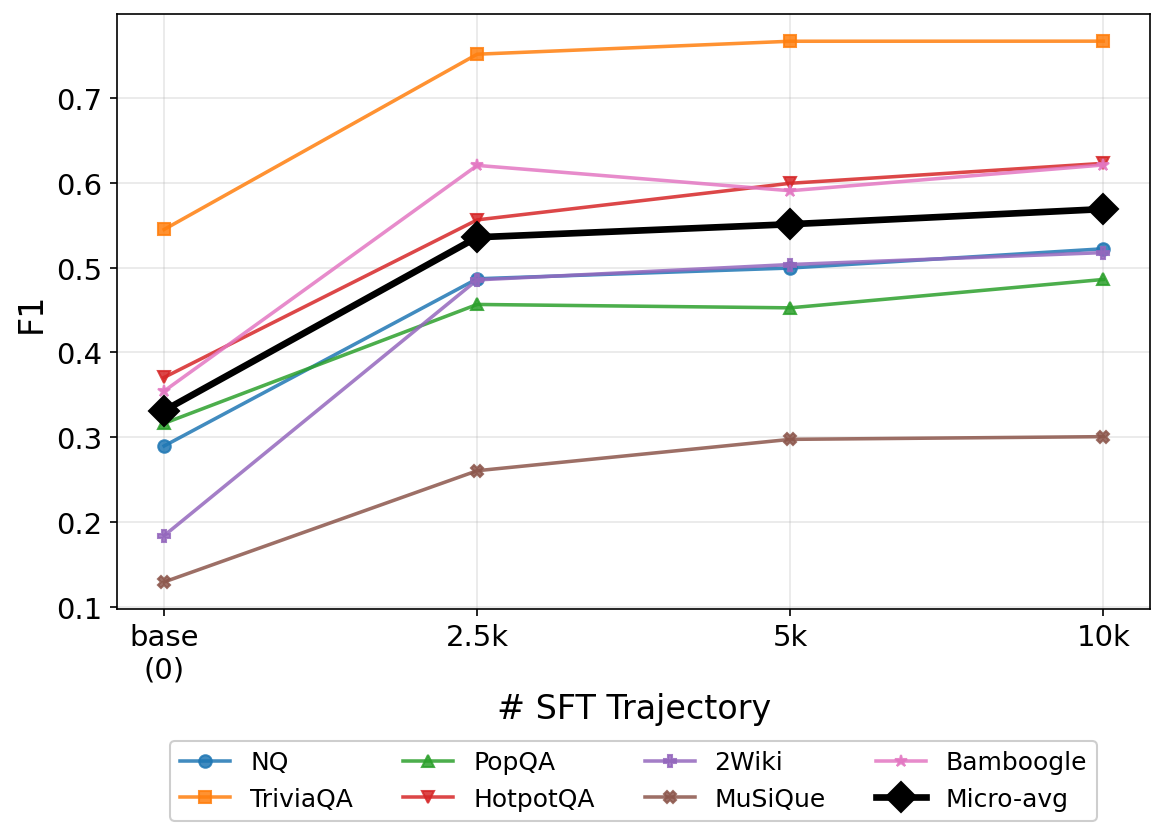
Figure 4 plots post-RL F1 as a function of SFT cold-start trajectory count. More cold-start data yields higher post-RL F1, meaning the quality of the GRPO starting point directly governs final performance—the two stages are interdependent, not independently additive.
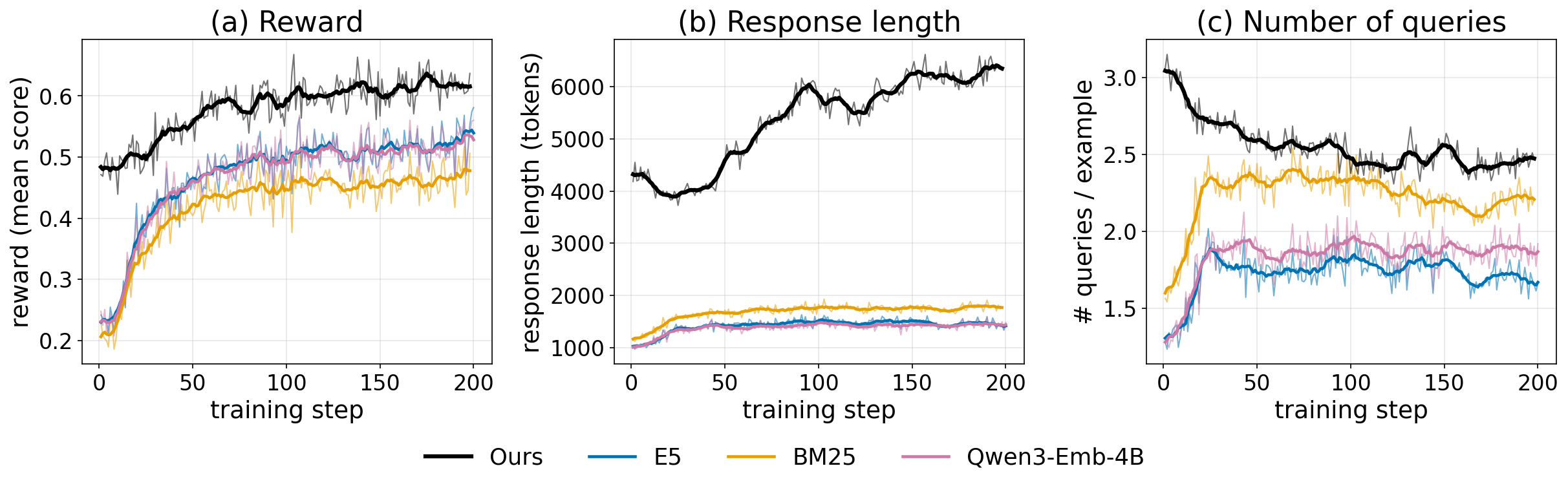
Figure 5 tracks 200 GRPO training steps: GrepSeek achieves higher mean reward throughout training than all Search-R1 variants (E5, BM25, Qwen3-Emb-4B). Response length and query count stabilize, confirming the two-stage pipeline suppresses the degenerate over-retrieval behavior that caused OOM failures under direct RL.
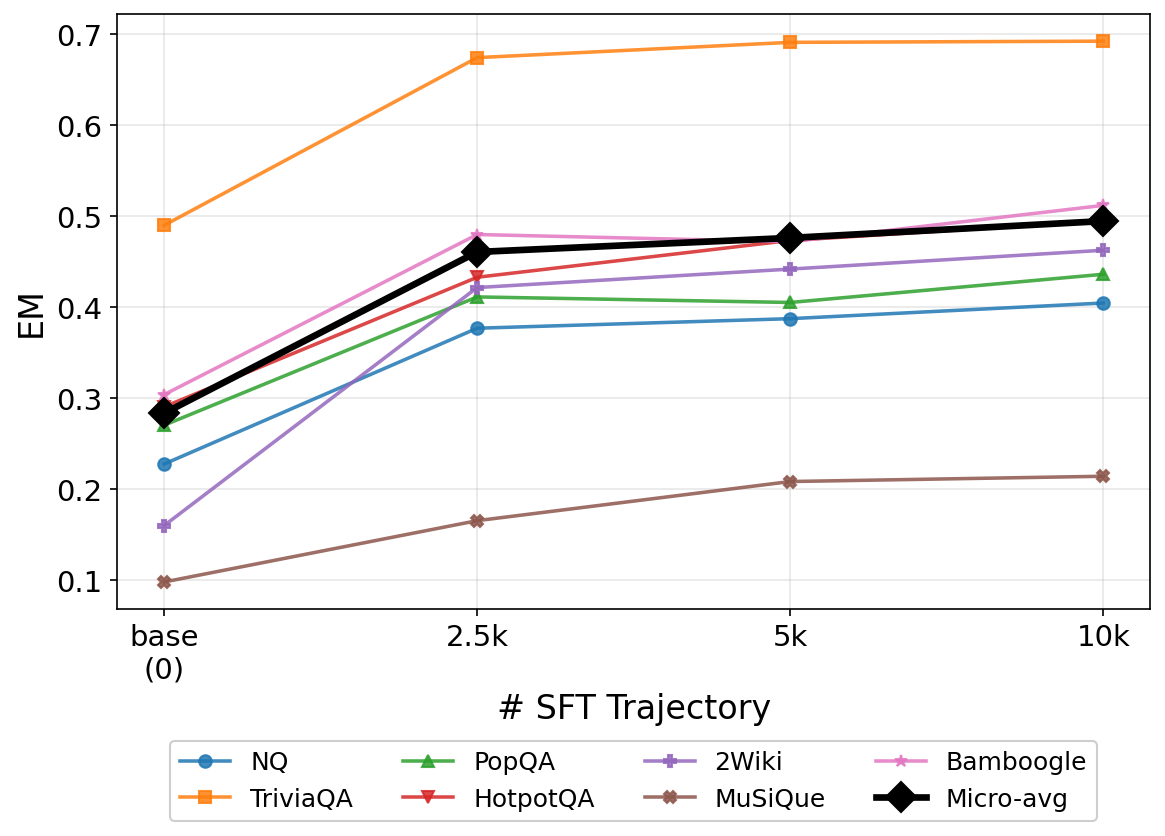
Figure 6 (Appendix Figure 17) shows EM after RL as a function of SFT trajectory count, mirroring Figure 4’s F1 trend. EM improves consistently with more cold-start data, confirming the trajectory-count sensitivity is not metric-specific.
Conclusion
GrepSeek shows that a compact LLM can learn DCI as a trained skill—not an inference-time prompting strategy—and reach top F1/EM across 7 English open-domain QA benchmarks at ~8.6s/query on a single A100. The 7.6× parallel engine is the key enabler for practical latency. Limits: results are English-only decoder QA; performance degrades on queries with substantial surface-form variation (acknowledged, not quantified per dataset); the paper does not evaluate on non-English corpora, structured data, or multi-machine distributed corpora. The “strongest overall” claim holds in aggregate across 7 benchmarks but GrepSeek is not top on all three single-hop datasets.
Novelty Check
From Related Work: The paper explicitly acknowledges Li et al. (2026) and Sen et al. (2026) as concurrent independent DCI work. GrepSeek’s stated delta: (1) training a compact model vs. prompting a large proprietary one, and (2) the sharded-parallel execution engine. Search-R1 is the closest RL-for-search prior work, operating over dense/sparse indices rather than raw corpora.
Independent assessment: The Tutor/Planner backward-then-forward cold-start construction for shell-command agents appears genuinely novel. The acknowledgment of concurrent DCI work is appropriately explicit. The ReAct + GRPO combination is precedented (Search-R1, ToolRL), but the DCI-specific instability diagnosis and two-phase cold-start design are meaningful contributions within that template.
Open Questions
- How much does surface-form variation actually cost per benchmark? The paper acknowledges degradation but does not quantify it by dataset.
- Can a hybrid DCI + dense retrieval agent recover semantic recall while preserving lexical precision? The paper suggests complementarity but does not experiment.
- How does the sharded-parallel engine scale beyond single-machine RAM-resident corpora to distributed multi-node setups?
- How sensitive is final performance to the capability of the Tutor LLM used for cold-start generation?
Original abstract
arXiv:2605.29307v1 Announce Type: cross Abstract: Large Language Model (LLM) search agents have shown strong promise for knowledge-intensive language tasks through multiple rounds of reasoning and information retrieval. Most existing systems access information using a retriever that takes a keyword or natural language query and returns a ranked list of documents using an index of pre-computed document representations. In this work, we explore a complementary perspective in which the search agent treats the corpus itself as the search environment and finds evidence by issuing executable shell commands. We introduce GrepSeek, an optimized direct corpus interaction (DCI) search agent that trains a compact search agent to find, filter, and compose evidence from large text corpora. To address the instability of learning behavior directly with reinforcement learning on large corpora, we propose a two-stage training pipeline. First, we construct a cold-start dataset using an answer-aware Tutor and answer-blind Planner to generate verified, causally grounded search trajectories. Second, we refine the initialized policy with Group Relative Policy Optimization (GRPO), allowing the agent to improve its task-oriented search behavior through direct interaction with the corpus. To make DCI practical at scale, we further use a semantics-preserving sharded-parallel execution engine that accelerates shell-based retrieval by up to $7.6\times$ while preserving byte-exact equivalence with sequential execution of the shell command. Experiments across seven open-domain question answering benchmarks show that GrepSeek achieves the strongest overall token-level $F_1$ and Exact Match. Our analysis also highlights the limitations of purely lexical interaction on queries with substantial surface-form variation, suggesting DCI as a practical and competitive method for search agents that can complement existing retrieval paradigms in the real world.