arXiv: 2604.09557 · PDF
作者: Talor Abramovich, Maor Ashkenazi, Izzy Putterman, Benjamin Chislett, Tiyasa Mitra, Bita Darvish Rouhani, Ran Zilberstein, Yonatan Geifman
单位: Microsoft
主分类: cs.DC · 全部: cs.AI, cs.DC
命中关键词: large language model, llm, inference, serving, speculative decoding, throughput, latency
TL;DR
SPEED-Bench 是一个专为 Speculative Decoding(SD)设计的评测基准,通过语义多样性最大化的 Qualitative Split 和面向吞吐量的 Throughput Split,弥补现有基准在多样性、生产引擎集成和并发评测上的系统性缺口。
Motivation
SD 的加速效果高度依赖数据域和文本熵——同一个 drafter 在不同任务上 speedup 差异可超过 1.5×——然而现有基准在这一点上系统性失真。SpecBench 大多数类别直接来自 MT-Bench,每类仅 10 个样本,多语言子集约占总数据 15% 且全是同构的翻译句式;EAGLE3 的验证集用的是 HumanEval(仅限简单 Python)、Alpaca 训练集(无官方测试集)等偏简单分布。更关键的是,现有评测几乎清一色用 BS=1 + HuggingFace 高层库跑,而真实 serving 场景是多用户并发、vLLM/TensorRT-LLM 引擎,底层优化路径完全不同。输入序列长度也普遍偏短,对长上下文场景(如 coding assistant)缺乏覆盖。受影响的是 LLM serving 工程师和 SD 算法研究者——他们需要选 drafter、调 draft length、决定什么时候开 SD,这些决策在失真基准上全部不可信。作者认为现在值得做这件事,是因为 native MTP(DeepSeek-R1、Qwen3-Next 等)的兴起让 SD 进入生产环境,评测滞后的代价正在上升。
核心观点
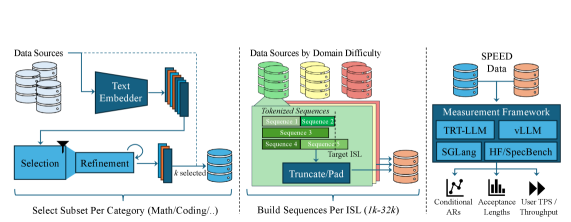
- 提出 SPEED-Bench 数据集:Qualitative Split(18 个公开数据集 → 11 类,每类 80 样本,共 880 样本,语义多样性最大化)+ Throughput Split(ISL 1k–32k 分桶,三档难度,最多 512 样本/ISL/难度)
- 语义多样性选择算法:用 OpenAI text-embedding-3-large 做嵌入,贪心选择 + Local Swap Refinement 最小化类内 pairwise cosine similarity
- 统一测量框架,外部预处理文本后送入引擎,确保 vLLM、TensorRT-LLM、SGLang 三者处理完全相同序列,隔离算法与系统差异
- 实证发现:合成随机输入高估真实吞吐量;最优 draft length 随 batch size 变化;低多样性数据掩盖 drafter 间的真实差距;词汇裁剪的代价因域高度不均
方法
SPEED-Bench 包含三个层次的设计。
Qualitative Split 构建时,先从 18 个公开数据集聚合候选样本,分成 11 个类别(受 SpecBench 启发并有改进),然后在每个类别内运行多样性选择算法:将所有候选映射到 text-embedding-3-large 的归一化嵌入空间,通过最小化 $\mathcal{L}(S)=\sum_{i,j\in S}x_i^\top x_j$ 来选出最优子集;由于该优化是 NP-hard,采用贪心初始化 + Local Swap Refinement 逃离局部极值。最终每类 80 样本,约 20% 为多轮对话(2–5 轮),约 80% 为难题,GPT-4 平均生成 ~650 tokens。
Throughput Split 将样本按 ISL 分桶(1k/2k/4k/8k/16k/32k),按三种难度组织,支持 batch size 2–512,用于绘制 Throughput vs. User TPS 的 Pareto 曲线。
测量框架 在引擎外统一做 tokenization 和序列处理,保证各引擎接收完全相同输入,使算法比较与引擎实现解耦。
下图展示了整个 SPEED-Bench 生态系统的构建流程,左侧语义多样性选择、中间 Throughput Split 的 ISL 分桶组装、右侧统一指标体系三个组件一目了然:
实验
- 目标模型:Llama 3.3 70B(dense)、GPT-OSS 120B(MoE,NVIDIA Nemotron 系列)
- Drafter:EAGLE3(full / pruned 词汇两种变体)、Vanilla SD(standalone smaller model)、Qwen3-Next native MTP
- 引擎:vLLM、TensorRT-LLM
- 对比基准:SpecBench(Xia et al., 2024)
- 指标:Acceptance Rate(AR)、Acceptance Length(AL)、Output TPS(吞吐量)、User TPS(单请求延迟代理)
- Draft length(DL)变化范围:DL = 1, 3, 7
结果
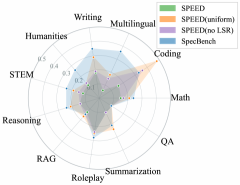
多样性验证(Figure 2):SPEED-Bench 的平均样本间语义相似度在所有类别中均低于随机选择和 SpecBench,证明选择算法有效。无 Local Swap Refinement 时(“No LSR”)多样性下降,说明 refinement 步骤贡献显著。
SPEED-Bench 的样本间相似度在所有类别中均优于随机选择和 SpecBench,支撑了"最小化 pairwise similarity 能有效提升多样性"这一核心设计主张:
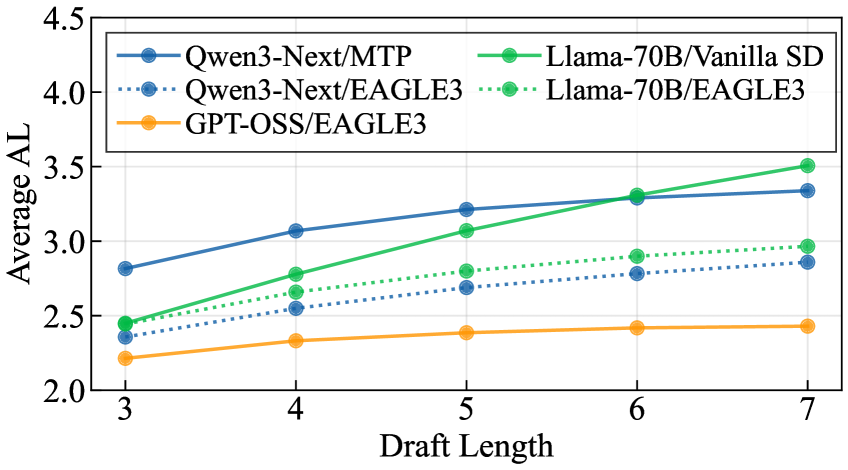
Drafter 精度与 Speedup(Figure 3):在 Qualitative Split、Temperature=1 下,external drafting 随 DL 增大扩展性优于 internal(post-trained)方法;Qwen3-Next native MTP 在不同 DL 下表现更稳健。表中数字显示,Mean AL 跨配置范围 1.27–2.68,对应 Mean Speedup 0.27×–1.75×,且部分高 batch 配置下出现低于 1× 的 speedup(0.85×,0.27×),说明 SD 在 compute-bound 区间可有负收益。
外部 drafter 在 DL 增大时 AL 扩展性显著好于 post-trained 的 EAGLE3 heads;Qwen3-Next native MTP 表现鲁棒;该图同时揭示某些配置下 speedup < 1×,验证了论文关于 compute-bound 区间 SD 负收益的论断:
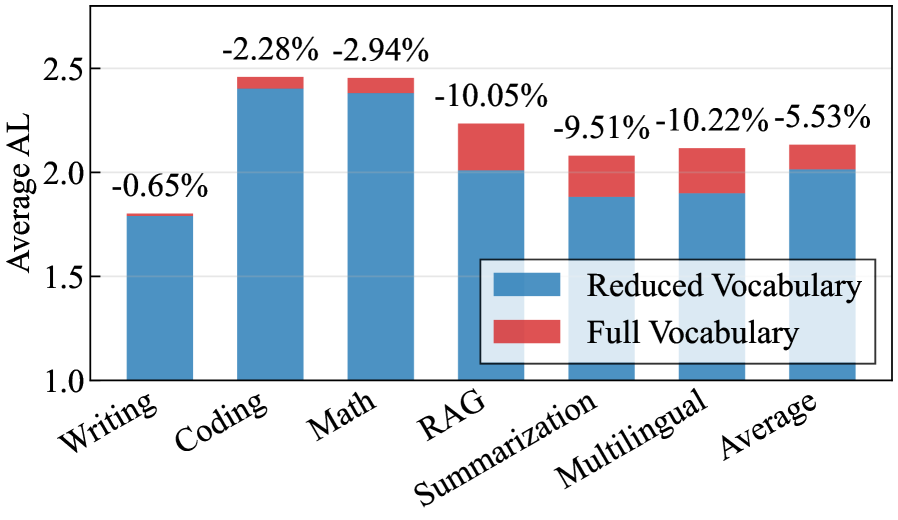
词汇裁剪效果(Figure 4):GPT-OSS 120B + EAGLE3 在 DL=3 下,full vs. pruned 词汇 drafter 的 AL 在不同任务类别间差异显著——部分域裁剪几乎无损,其他域 AL 明显下降,说明词汇裁剪效果高度域相关,不可一刀切。
词汇裁剪对不同域 AL 的影响差异悬殊,某些类别裁剪代价极小而另一些则不然——这一发现否定了"裁剪普遍安全"的假设:
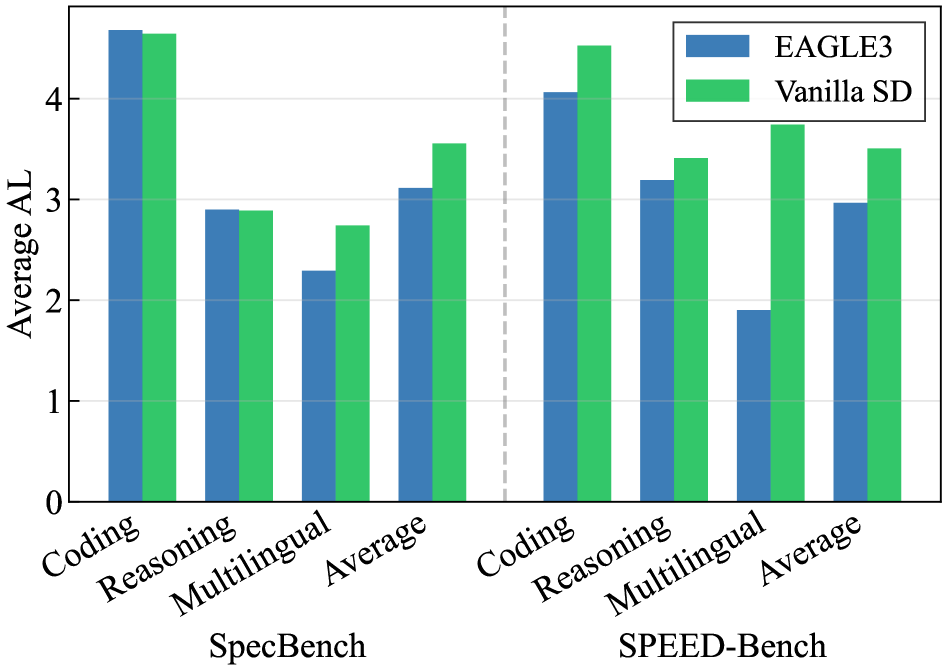
SpecBench 对比(Figure 5):SpecBench 的 Coding 和 Reasoning 类别各仅 10 个样本,导致轻量 EAGLE3 drafter 在统计上看似与更强的 Vanilla SD 方法相当——这是低样本量制造的噪声,而非真实性能。SPEED-Bench 下两者差距清晰可见。
SpecBench 每类仅 10 样本导致 EAGLE3 和 Vanilla SD 在 Coding/Reasoning 上看起来相近,这是纯粹的统计噪声;SPEED-Bench 的更大样本量使真实差距重新显现:
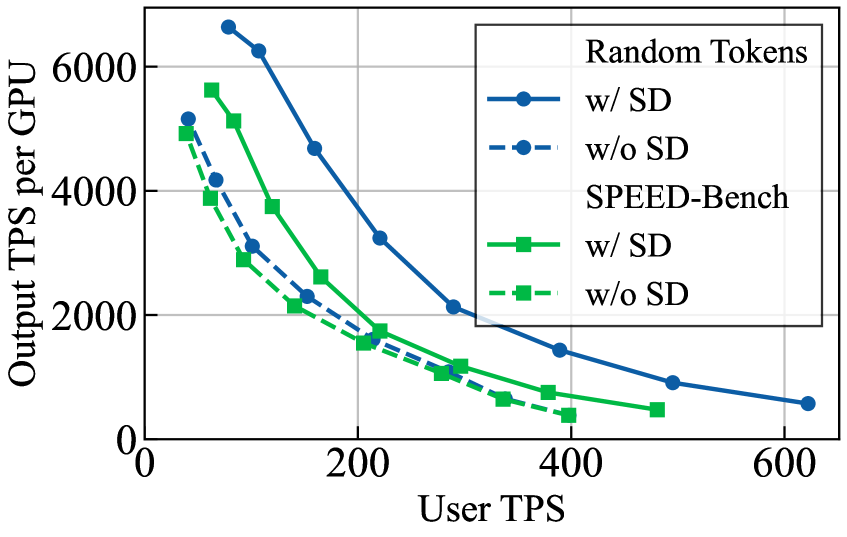
合成输入高估吞吐量(Figure 6):以 GPT-OSS 120B + EAGLE3 在 TensorRT-LLM 上 DL=3 为例,random 随机 token 输入下的 Throughput vs. User TPS 曲线系统性地高于 Throughput Split(8k ISL)真实数据的曲线。这直接量化了"合成输入高估真实吞吐量"这一论断。
随机 token 与真实 8k ISL 数据在 TensorRT-LLM 上跑出的 Throughput–User TPS 曲线存在可见差距,说明用合成输入评测会系统性高估 SD 在实际服务负载下的吞吐量:
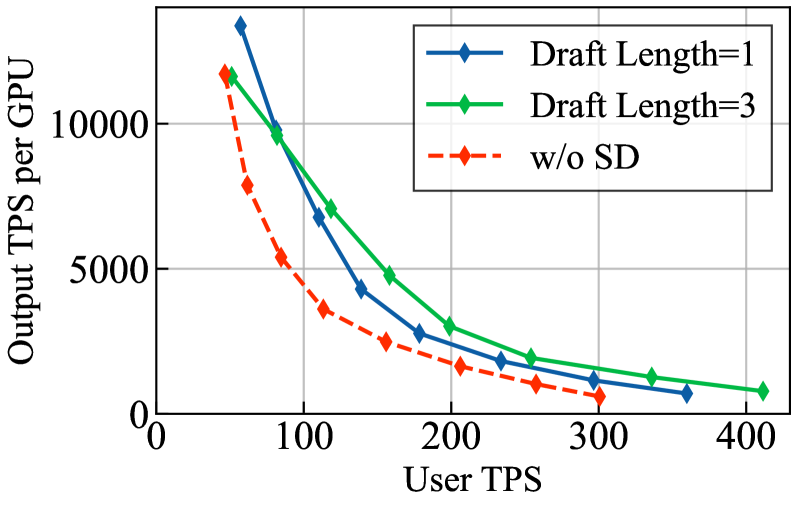
最优 Draft Length 随 Batch Size 变化(Figure 7):在 Throughput Split(2k)、vLLM 上,DL=3 在低 batch size 下吞吐量更高,但随 batch 增大,DL=1 开始占优;对 MoE 模型(GPT-OSS 120B)两条曲线的交叉点出现在较高 BS 处,体现 MoE 对 SD 的友好性。
DL=1 和 DL=3 的最优区间随 batch size 切换,实践者需要根据实际 concurrency 选择 draft length 而非固定使用最大 DL;MoE 模型的曲线交叉点比 dense 模型更晚,体现其 compute-bound 阈值更高:
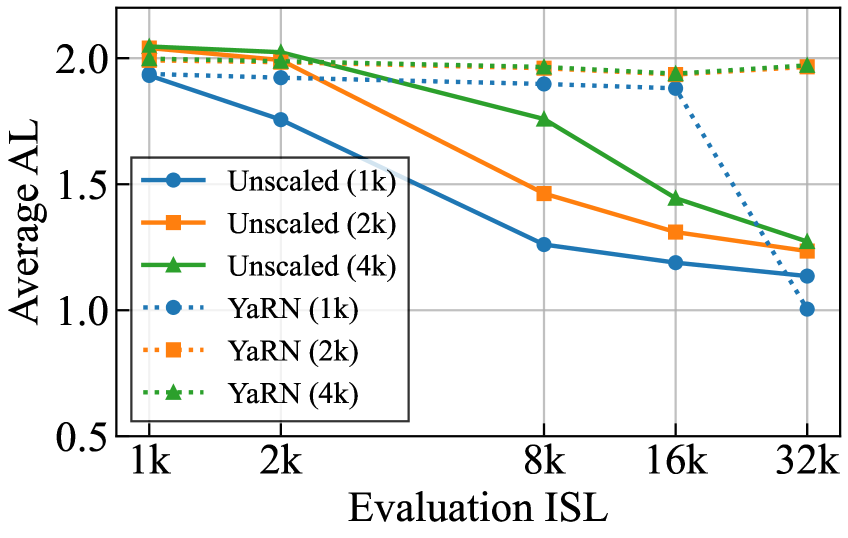
训练 ISL 的影响(Figure 8):EAGLE3 drafter 在推理 ISL 超过训练 ISL 时 AL 快速下降;通过 YaRN scaling(图中虚线)可以缓解但不能完全消除此问题;训练 ISL=4k 的模型在长上下文下退化速度最慢。
EAGLE3 drafter 的 AL 在推理 ISL 超出训练 ISL 时急剧下滑,说明现有 drafter 在长上下文部署时存在系统性精度缺陷,YaRN 只是部分缓解:
结论
SPEED-Bench 最核心的带走点是:评测基准的数据多样性和引擎真实性对 SD 结论有实质影响——SpecBench 的 10 样本/类设置足以制造虚假的性能等价,合成输入会系统性高估吞吐量,同一 drafter 在不同域 speedup 可差 6 倍以上。论文结论在 decoder-only dense/MoE 模型、NVIDIA GPU(vLLM/TensorRT-LLM)上成立;标题强调"统一",但目前仅在英文任务上验证;量化模型、encoder-decoder 架构未覆盖。缺失的 ablation 包括:不同 target 模型大小对基准有效性的影响;在 SGLang 上的全量对比(仅在框架支持层面提及);Throughput Split 的 ISL > 8k 场景。
是否新瓶装旧酒
论文自述最相近前人工作:SpecBench(Xia et al., 2024)——作者认为自己的 delta 是:更大的类内样本量(80 vs 10)、语义多样性选择算法、Throughput Split 和生产引擎集成。
独立判断:这是一篇实质性的工程贡献论文,不是换名重包。SpecBench 存在的样本量、合成数据和 BS=1 问题是真实存在的,SPEED-Bench 的修复也是具体的。不过,benchmark paper 本身的贡献边界较窄——核心是"提供了更好的评测工具",而非新算法或新理论;论文的作者来自 NVIDIA,GPT-OSS 120B 和 TensorRT-LLM 均是 NVIDIA 产品,评测中对自家工具的覆盖更深,存在潜在偏向,论文也主动披露了利益冲突。
尚未回答的问题
- 词汇裁剪的域差异(Figure 4)有定性发现,但缺乏解释性分析——为什么某些域对裁剪免疫?是 token 分布的什么性质决定的?
- Throughput Split 仅覆盖 ISL 1k–32k 的输入端;输出长度分布的影响(尤其是 chain-of-thought 推理模型的超长输出)未评测。
- 在 quantized(如 FP8/INT4)目标模型上 SD 的基准表现未涉及,而量化是生产部署的标准配置。
- SPEED-Bench 的稳定性随类别增加如何变化?当前 11 类 × 80 样本的配置是否对所有 drafter 架构都足够?(Appendix C 有部分分析但正文未完整展开)
原始摘要(中文翻译)
Speculative Decoding(SD)已成为加速大型语言模型(LLM)推理的关键技术。与确定性系统优化不同,SD 的性能本质上依赖于数据,这意味着多样化且具有代表性的工作负载对于准确衡量其有效性至关重要。现有基准存在任务多样性有限、对面向吞吐量的评测支持不足、以及依赖高层实现而无法反映生产环境等问题。为此,我们提出 SPEED-Bench,一套旨在跨多样语义领域和真实服务场景标准化 SD 评测的综合套件。SPEED-Bench 提供了精心策划的 Qualitative 数据集,通过优先保证数据样本的语义多样性进行选取。此外,它还包含 Throughput 数据集,支持在从低延迟敏感小批次到高负载吞吐量优先等不同并发度场景下评测加速效果。通过与 vLLM 和 TensorRT-LLM 等生产级引擎集成,SPEED-Bench 使实践者能够分析那些在其他基准中常被掩盖的系统行为。我们通过量化合成输入对真实吞吐量的高估程度、识别依赖 batch size 的最优 draft length 以及低多样性数据中的偏差,并分析前沿 drafter 中词汇裁剪的注意事项,来展示这一点。我们发布 SPEED-Bench,以建立 SD 算法实用比较的统一评测标准。