arXiv: 2604.09557 · PDF
Authors: Talor Abramovich, Maor Ashkenazi, Izzy Putterman, Benjamin Chislett, Tiyasa Mitra, Bita Darvish Rouhani, Ran Zilberstein, Yonatan Geifman
Affiliations: Microsoft
Primary category: cs.DC · all: cs.AI, cs.DC
Matched keywords: large language model, llm, inference, serving, speculative decoding, throughput, latency
TL;DR
SPEED-Bench 是一个专为投机解码(Speculative Decoding)设计的综合评测套件,通过语义多样性驱动的数据策划与生产级引擎集成,解决现有基准在多样性、吞吐量评估和真实环境代表性上的系统性缺陷。
Motivation
SD 加速率本质上依赖数据域和输入熵,但现有评测工具无法准确反映这一特性。MT-Bench 每类别仅10个样本,SpecBench 约15%数据来自单一翻译模板(WMT14 DE-EN),多数类别平均输入长度不足100 tokens。研究社区普遍在 BS=1 下使用 HuggingFace 高层库评测,而生产部署中 vLLM/TensorRT-LLM 等引擎引入了额外优化,且真实多用户服务需以高并发最大化吞吐——高并发使系统从 memory-bound 切换为 compute-bound,SD 加速收益显著下降甚至变为减速。此外,随着长上下文应用普及,现有基准对长 ISL 场景几乎空白。这些缺陷导致不同论文的跨方法比较结论不具可比性。
Key Ideas
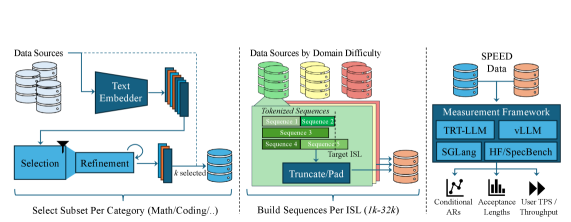
- 双分支数据集:Qualitative Split(18个公开数据集、11类别、80样本/类,880个总样本)最大化语义多样性;Throughput Split(ISL 1k–32k 固定桶、三档难度)支持批大小扩展至512
- 贪心+局部交换精炼算法(Algorithm 1),最小化样本间余弦相似度,以 NP-hard 问题的近似解实现高效代表性采样
- 统一测量框架原生集成 vLLM、TensorRT-LLM、SGLang,文本处理在框架层完成,隔离算法效果与引擎差异
- 实证揭示:合成输入高估真实吞吐量、最优 Draft Length(DL)随批大小变化、低多样性数据引入评测偏差、词汇表剪枝的跨域副作用、训练 ISL 不匹配导致精度崩溃
Method
Qualitative Split 使用 OpenAI text-embedding-3-large 将 prompt 映射为单位向量,通过最小化全对余弦相似度目标 $\mathcal{L}(S)$(公式2)选取80样本/类;约20%样本含多轮交互(2–5轮),难度字段偏向难题(~80%),GPT-4 验证平均输出约650 tokens。
Throughput Split 将真实数据按 ISL 桶(1k/2k/4k/8k/16k/32k)和三档难度聚合,每桶最多512样本,用于绘制稳定的吞吐-延迟 Pareto 曲线。
测量框架 在框架层完成 tokenization,确保所有引擎处理完全相同的 token 序列,标准化跨引擎比较。
SPEED-Bench 的整体 pipeline 如下图所示:左侧为 embedding 驱动的多样性策划算法,中间展示 Throughput Split 按 ISL 桶构建过程,右侧为统一指标报告框架,三组件共同支持从单请求延迟到高并发吞吐的完整评测场景。
Experiments
目标模型:GPT-OSS 120B(MoE)、Llama 3.3 70B;草稿器:EAGLE3(全词汇/剪枝变体)、Vanilla SD、Qwen3-Next 原生 MTP;推理引擎:vLLM、TensorRT-LLM;评测场景:Qualitative Split(DL 1–7,BS=1)、Throughput Split(ISL 2k/8k,BS 2–256/1–128);指标:Acceptance Length(AL)、Output TPS、User TPS。
Results
语义多样性验证:SPEED-Bench 选择算法在所有类别上的平均样本间语义相似度均低于随机选择和 SpecBench(更低=更多样),Local Swap Refinement(LSR)进一步收窄相似度,确认算法有效性(Figure 2)。
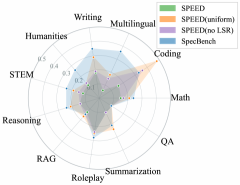
图2展示三种方法在各类别的平均相似度柱状图;SPEED-Bench(含LSR)在全部类别均最低,即使无LSR也优于随机选择,说明贪心初始化本身已筛选出更多样的子集。
草稿器精度与加速比:外部草稿器(如EAGLE3)随 DL 增加 AL 扩展性更好;Figure 3 对应数据行显示 Mean AL 范围 1.27–2.68,Mean Speedup 范围 0.27×–1.75×,部分高并发配置出现 <1× 减速(最低 0.27×),直接说明 SD 并非总能加速。
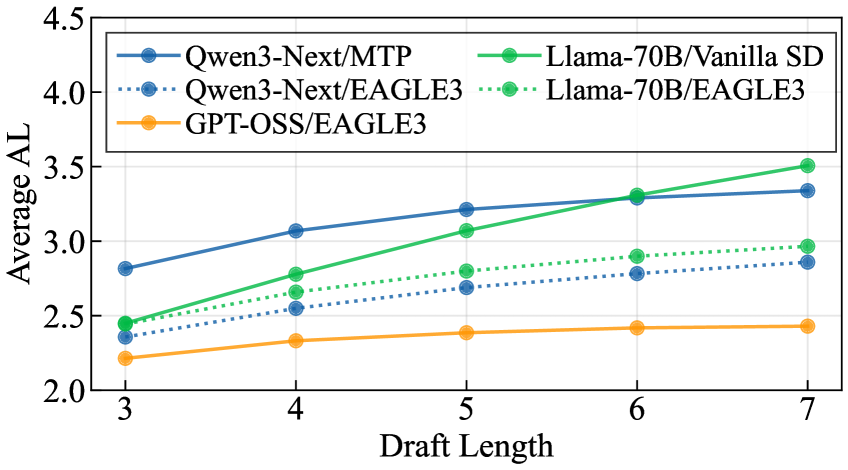
图3展示不同草稿方法在 Qualitative Split 上 AL 随 DL 的变化曲线;外部草稿器持续增长,原生 MTP 在较低 DL 趋于平稳;配合数据行中 0.85× 和 0.27× 的减速案例,强调了多 BS 覆盖的必要性。
词汇表剪枝跨域方差:GPT-OSS 120B + EAGLE3,DL=3 时,全词汇与剪枝词汇在不同类别的 AL 差异极大(Figure 4);论文指出存在"高方差",说明剪枝收益高度依赖数据域,在低多样性基准上得出的剪枝结论可能严重失真。
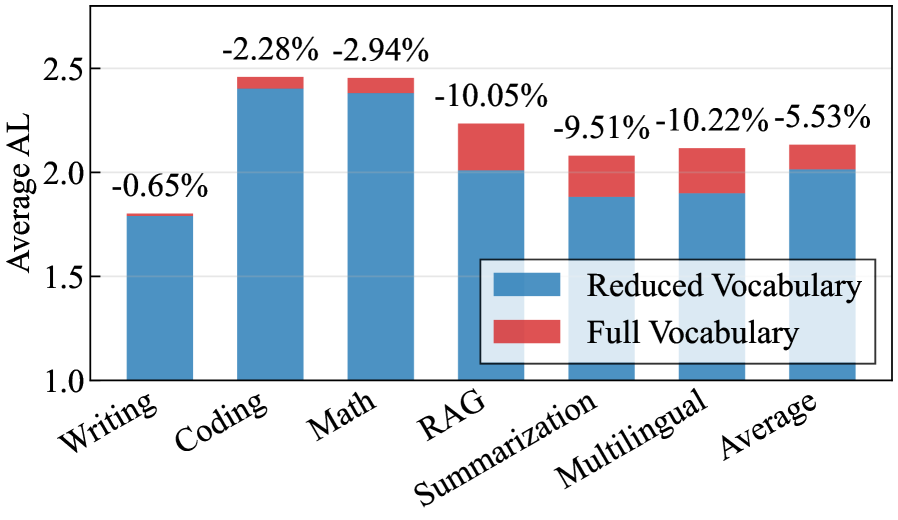
图4对比各类别全/剪枝词汇的 AL 柱状图,某些类别剪枝几乎无损失,另一些类别 AL 显著下降,无法用单一数字描述剪枝代价。
SpecBench 评测偏差:SpecBench 的 Coding 和 Reasoning 各仅10个样本,统计噪声使轻量 EAGLE3 看似与 Vanilla SD 持平;在 SPEED-Bench 更大多样性数据上(Llama 3.3 70B,DL=7),两者差距清晰可见(Figure 5)。
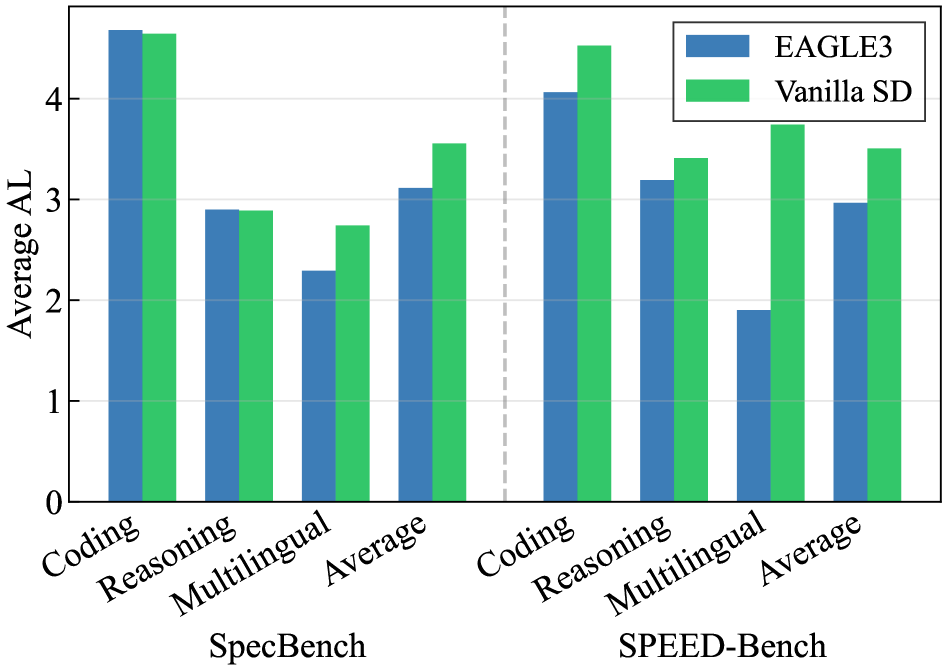
图5对比两个基准各类别 AL 柱状图;SpecBench 中轻量草稿器性能被夸大,SPEED-Bench 还原了方法间的真实相对排序,支持了"小样本低多样性引入评测偏差"这一核心论点。
合成输入高估真实吞吐量:GPT-OSS 120B + EAGLE3,TensorRT-LLM,DL=3,BS 1–128 时,随机输入与8k Throughput Split 的吞吐-User TPS 曲线存在明显偏离,合成输入系统性高估真实吞吐(Figure 6)。
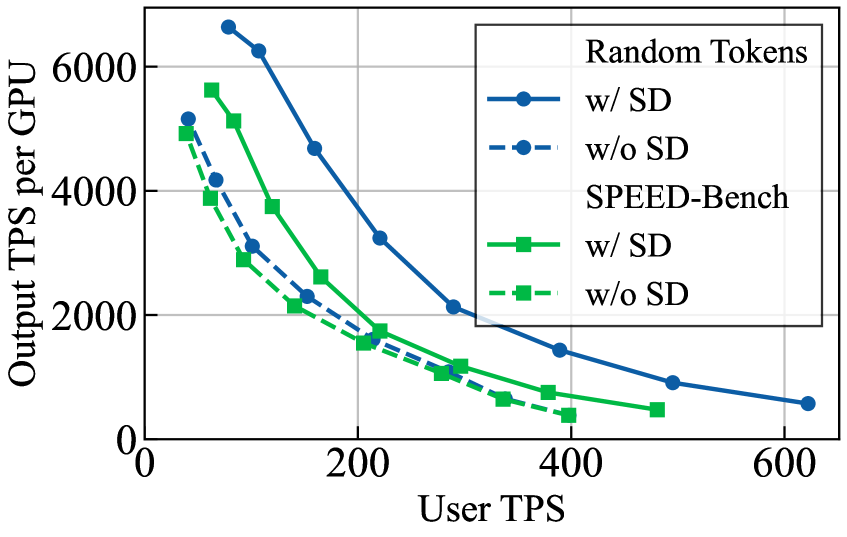
图6展示两条曲线在 BS 1–128 上的偏差;随机输入的 Pareto 前沿明显高于真实数据曲线,量化了依赖合成数据进行吞吐评测的核心误导风险。
批大小依赖的最优 DL:DL=1 在高并发下吞吐更高,DL=3 在低并发下更优,存在明确交叉点(GPT-OSS 120B + EAGLE3,vLLM,2k ISL,BS 2–256);MoE 架构即使在高 BS 下仍受益于 SD(Figure 7)。
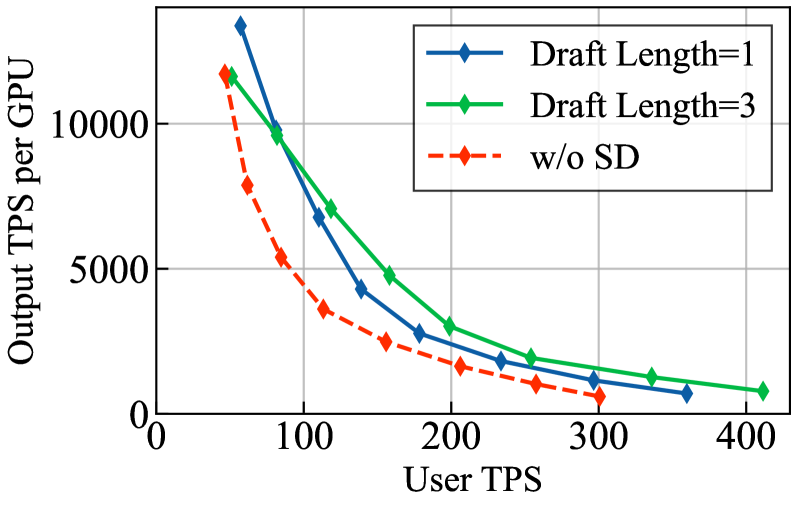
图7给出 DL=1/3 在不同 BS 下的 Pareto 曲线;两线交叉点为部署中动态选择 DL 提供了直接依据,也验证了论文关于 MoE 模型 SD 收益持续性的论点。
训练 ISL 不匹配:推理 ISL 超过训练 ISL 时 AL 急剧下降;YaRN 缩放(虚线)部分缓解但无法消除该问题(GPT-OSS 120B + EAGLE3,vLLM,DL=3,训练 ISL 1k/2k/4k)(Figure 8)。
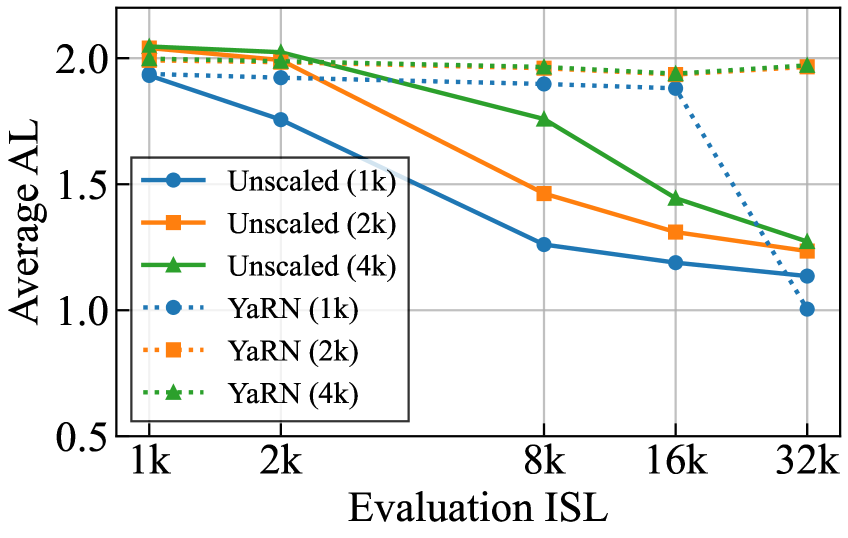
图8量化了外推精度崩溃:训练于1k ISL 的草稿器在 2k+ 推理序列上 AL 大幅下降,训练于4k 的版本维持更高 AL;该发现揭示了现有 EAGLE3 模型的长上下文系统性缺陷。
Conclusion
SPEED-Bench 的核心贡献是填补了 SD 评测在数据多样性、吞吐测量和生产环境代表性三方面的空白。最重要的实证发现是:合成输入会系统性高估真实吞吐量,而最优 DL 随批大小动态变化——这两点对生产部署决策有直接影响。结果建立在 GPT-OSS 120B 和 Llama 3.3 70B 上,硬件为 NVIDIA GPU;超过 32k ISL、非 NVIDIA 硬件及 dense 小模型(<70B)场景未被覆盖。词汇表剪枝分析揭示了高方差现象,但未提供何时整体有益的定量判断标准。作者来自 NVIDIA(文中已披露),TensorRT-LLM 相关实验的独立性需读者注意。
Novelty Check
论文自身 Related Work 定位:作者将 SpecBench(Xia et al., 2024)列为最接近的前驱,明确指出其继承 MT-Bench 的低多样性、缺乏吞吐导向评估的局限。SPEED-Bench 的 delta 是:算法驱动的多样性策划、Throughput Split、生产引擎集成三者的组合。
独立评估:这是一篇 benchmark 论文,核心贡献是工程性与实证性的,而非新 SD 算法。在该范畴内,多样性策划算法与生产引擎集成的组合具有实质区别,不属于简单重标签。主要限制在于整体规模仍相对有限(880 Qualitative 样本),且与 SpecBench 不同,SPEED-Bench 目前不含开放排行榜机制,其"统一标准"定位尚需社区采纳验证。
Open Questions
- 最优 DL 随 BS 变化的交叉点能否在推理时动态预测,实现自适应 DL 调度?
- 词汇表剪枝在何种域/模型配置下整体有益——是否存在可量化的判断标准?
- 训练 ISL 与 YaRN 扩展的最优配比:对于目标推理 ISL X,何种训练 ISL + YaRN 组合最具性价比?
- SPEED-Bench ISL 桶上限为 32k,超长上下文(128k+)场景是否存在类似系统性评测偏差?
- 对于 dense 小模型(7B–13B),Throughput Split 的最优 DL 模式是否与 MoE 120B 有显著差异?
Original abstract
arXiv:2604.09557v2 Announce Type: replace-cross Abstract: Speculative Decoding (SD) has emerged as a critical technique for accelerating Large Language Model (LLM) inference. Unlike deterministic system optimizations, SD performance is inherently data-dependent, meaning that diverse and representative workloads are essential for accurately measuring its effectiveness. Existing benchmarks suffer from limited task diversity, inadequate support for throughput-oriented evaluation, and a reliance on high-level implementations that fail to reflect production environments. To address this, we introduce SPEED-Bench, a comprehensive suite designed to standardize SD evaluation across diverse semantic domains and realistic serving regimes. SPEED-Bench offers a carefully curated Qualitative data split, selected by prioritizing semantic diversity across the data samples. Additionally, it includes a Throughput data split, allowing speedup evaluation across a range of concurrencies, from latency-sensitive low-batch settings to throughput-oriented high-load scenarios. By integrating with production engines like vLLM and TensorRT-LLM, SPEED-Bench allows practitioners to analyze system behaviors often masked by other benchmarks. We highlight this by quantifying how synthetic inputs overestimate real-world throughput, identifying batch-size dependent optimal draft lengths and biases in low-diversity data, and analyzing the caveats of vocabulary pruning in state-of-the-art drafters. We release SPEED-Bench to establish a unified evaluation standard for practical comparisons of SD algorithms.