arXiv: 2604.13519 · PDF
作者: Heming Xia, Yongqi Li, Cunxiao Du, Mingbo Song, Wenjie Li
单位: The Hong Kong Polytechnic University, Peking University
主分类: cs.CL · 全部: cs.CL
命中关键词: large language model, llm, tool use, retrieval, serving, speculative decoding, latency
TL;DR
ToolSpec 针对 LLM tool calling 的推理延迟瓶颈,利用工具调用的 schema 约束结构 + 历史调用检索,在无需额外训练的情况下实现最高 4.2× 的加速。
Motivation
多步、多轮 tool calling 已成为复杂任务 LLM agent 的标准工作流,但每次工具调用都需要 LLM 生成格式严格的 JSON 序列,导致推理延迟急剧上升。现有加速研究主要针对工具执行侧(通过 DAG 并行化独立工具、或提前执行工具重叠 IO),而对工具调用生成侧几乎没有关注。
作者在 ToolBench 上对 Qwen2.5-Instruct 系列实测发现:工具执行延迟随模型规模基本不变,而生成延迟随模型规模线性增长——对 Qwen2.5-72B-Instruct,工具调用生成已占端到端延迟的 96%,是工具执行时间的约 4 倍(Figure 2)。这意味着过去所有执行侧优化的上限已经非常有限,生成侧才是真正的瓶颈。
进一步分析发现两个被忽视的规律:① tool calling 输出高度结构化,绝大多数 token 是 schema 固定内容,只有参数值是"变量";② 同一工具在实际 benchmark 中被反复调用(API-Bank 每个工具平均被调用 10.95 次)。这两点性质使得 speculative decoding 在 tool calling 场景下可以做得远比通用文本生成更激进,而现有通用 SD 方法完全没有利用 schema 约束信息,因此存在明显效率缺口。
核心观点
工具调用生成延迟占端到端推理的绝大多数比例,这一点通过分析 Qwen2.5-Instruct 不同规模模型在 ToolBench 上的延迟分布得到证实。随着模型规模增大,生成延迟比例持续上升至 96%,如图所示:
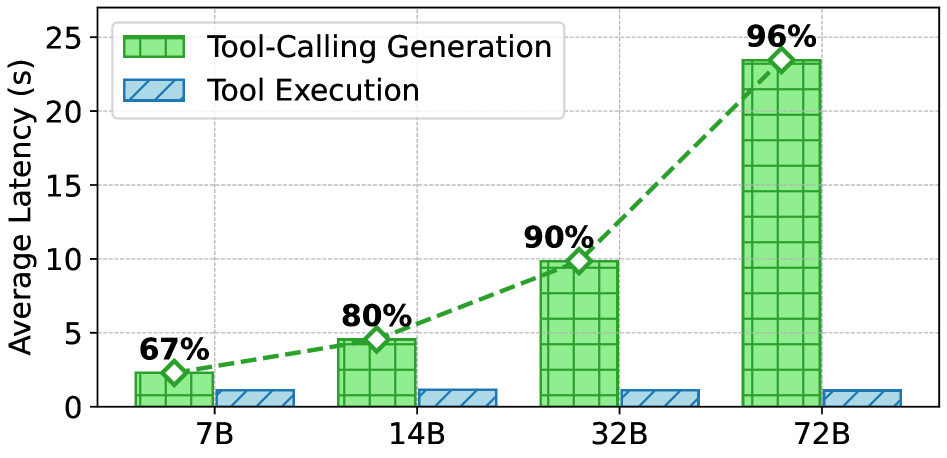
该图中,工具执行延迟(蓝色)在各模型规模下几乎持平,而生成延迟(橙色)随模型增大急剧升高,直接支撑了"生成是瓶颈"这一核心论点。
- 提出 ToolSpec:首个专门针对 tool calling 结构性的、免训练的 speculative decoding 方案。
- Schema-aware Drafting:用有限状态机(FSM)确定性地填充 schema token,仅对变量字段做推测生成,极大提升草稿接受率。
- Retrieval-augmented Speculation:检索历史相似 tool call,直接复用作为高质量草稿,进一步提升重复调用场景效率。
- Plug-and-play:无需微调目标模型或额外训练,可直接接入现有 LLM serving 流程。
- 实证效率提升:在 API-Bank、ToolAlpaca、BFCLv2、ToolBench 四个 benchmark 上达到 3.5×~4.2× 加速,比现有最优 SD 基线提升最高 71%。
方法
ToolSpec 的核心是将 tool calling 建模为受约束的 speculative decoding问题,由两套互补的草稿生成策略组成:
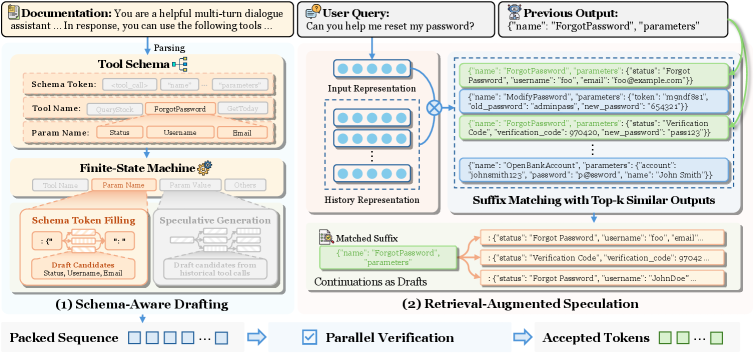
图 5 同时展示了 schema-aware drafting(左,FSM 引导下的确定性 schema token 填充 + 并行候选工具名验证)和 retrieval-augmented speculation(右,从历史 tool call 库中检索并复用完整草稿序列),两个策略分别覆盖结构化字段和重复调用场景,协同工作。
Schema-aware Drafting:构建 FSM $\mathcal{F} = (\mathcal{Q}, \Sigma_{\text{schema}}, \delta, q_0)$,状态集合 $\mathcal{Q}$ 包含:工具名状态 $q_t$、参数名状态 $q_p$、参数值状态 $q_v$、自然语言状态 $q_o$。<tool_call> token 触发后,FSM 进入 $q_t$,通过约束解码枚举所有合法工具名作为候选草稿,再由目标模型单次前向传播用 tree-structured attention mask 并行验证全部候选。验证通过后 FSM 转入 $q_p$,同样并行验证该工具的合法参数名;进入 $q_v$ 后参数值不受约束,退回通用 SD 算法生成。

该状态机图明确展示了 FSM 在三类 token 之间的切换逻辑:schema token 由 FSM 确定性填充,工具名和参数名由并行验证确定,只有参数值才走推测生成——这是 ToolSpec 相比通用 SD 方法效率更高的关键设计。
Retrieval-augmented Speculation:维护历史 tool call 库,对当前生成请求检索相似历史调用,将整条历史记录作为草稿序列候选,目标模型再做并行验证。此策略专门应对工具被重复调用的场景(Table 2 显示 API-Bank 平均每工具调用 10.95 次),可跨越参数值阶段直接提供完整的高质量草稿。
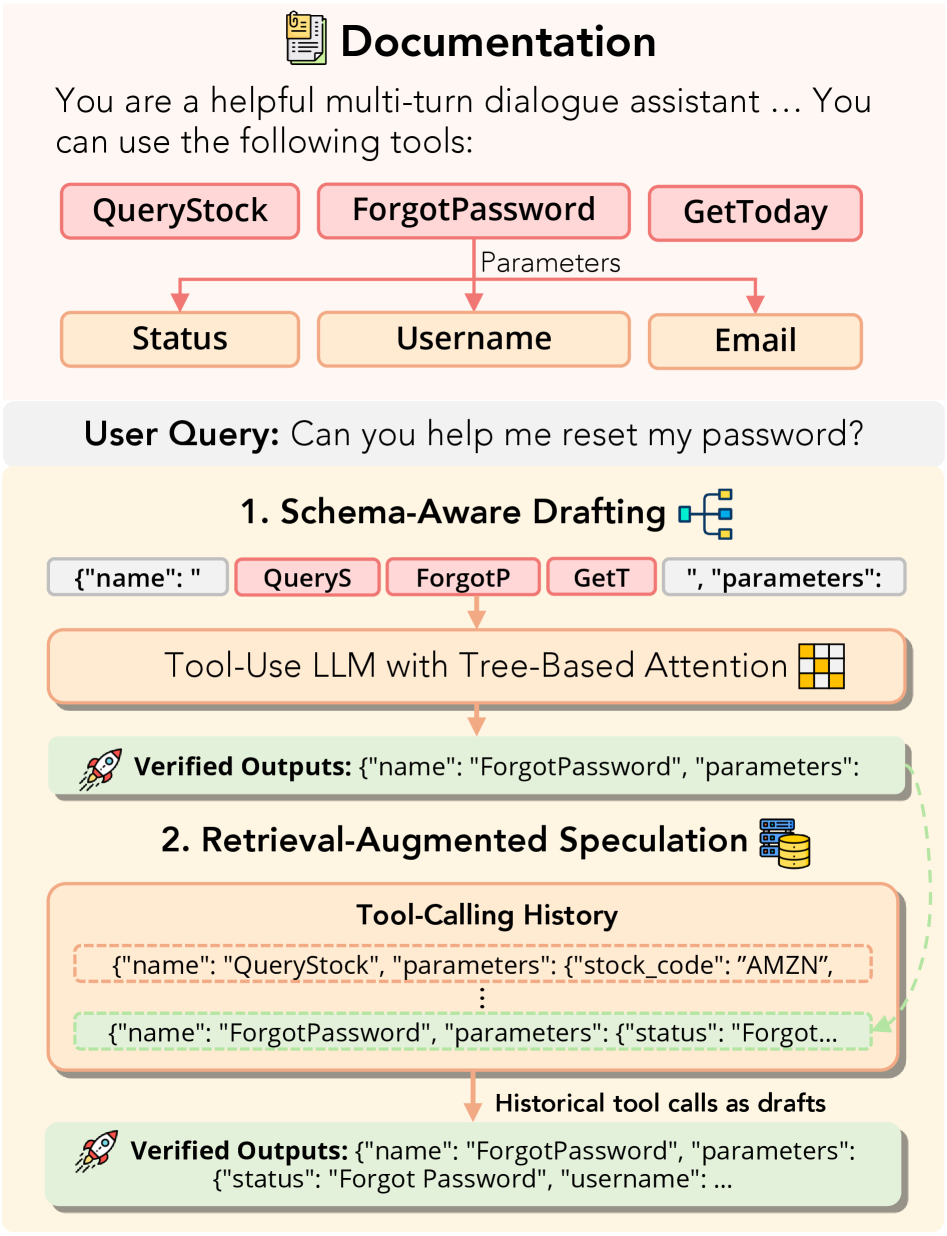
整体系统 overview 图进一步直观确认:schema-aware 侧负责 schema 固定字段的高精度草稿,retrieval 侧负责历史语义复用,两者并行接入目标模型验证。
实验
数据集:API-Bank(2138 工具,5221 实例)、ToolAlpaca(426 工具,3938 实例)、BFCLv2(739 工具,2251 实例)、ToolBench。
模型:LLaMA-3.1-8B-Instruct、LLaMA-3.2-3B-Instruct、Qwen2.5-7B-Instruct、Qwen2.5-14B-Instruct、Qwen2.5-32B-Instruct,以及 ToolLLaMA 系列。
Baseline:Token Recycling(Luo et al., 2025)、SAM-Decoding(Hu et al., 2025)、Eagle 系列(Li et al., 2024/2025)等现有 SD 方法。
评估指标:推理加速比(Speedup)、平均接受 token 数(#MAT)、format adherence。
工具调用 schema adherence 分析(Table 1):LLaMA-Instruct 和 Qwen2.5-Instruct 系列均达到 99%+ 的格式遵从率,验证了 schema-aware drafting 的可行性前提。

该示例 trace 以颜色标注 schema token(固定)、工具名/参数名(有限集合)、参数值(变量),直观说明了为何大多数 token 可以确定性地草拟,只有参数值需要推测生成。
结果
主要加速结果(Figure 6):与现有 plug-and-play SD 方法(Token Recycling、SAM-Decoding 等)相比,ToolSpec 在 ToolBench 上的加速比显著更高。
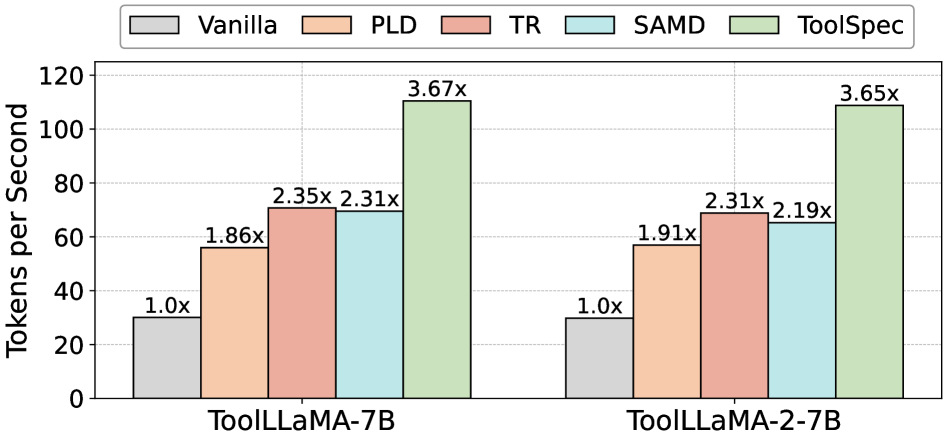
该对比柱状图显示 ToolSpec 全面超越所有先前免训练 SD baseline,整体 speedup 范围为 3.5×~4.2×,比现有最优 SD 方法相对提升最高 71%(Introduction 中明确陈述)。
接受长度分析(Figure 7):在 LLaMA-3.1-8B-Instruct + API-Bank 上,前两个解码步骤(对应 FSM 的 $q_t$ 和第一个 $q_p$ 状态)的接受 token 长度分布。
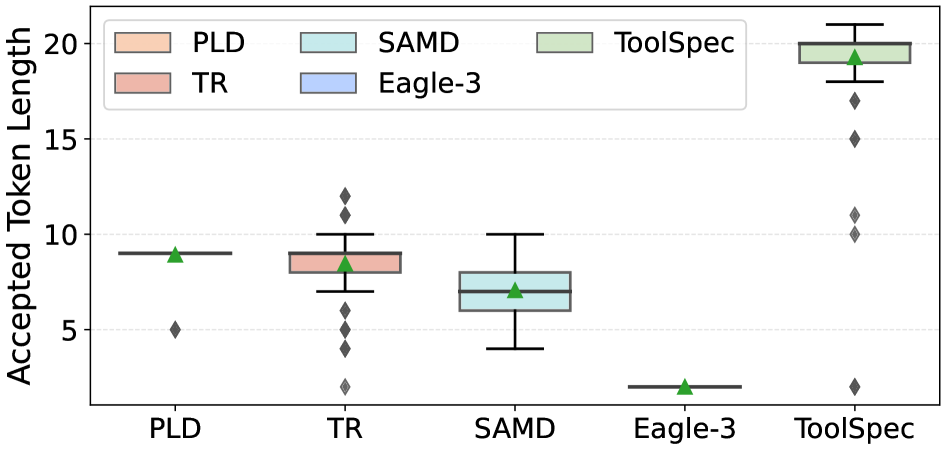
该分布图展示了 schema-aware drafting 在工具名和参数名阶段的实际接受效果——绿色三角为均值,黑色菱形为离群点。论文正文未在此处单独给出均值数字,具体数值见图内标注。
重复调用加速(Figure 8):retrieval-augmented speculation 在重复调用场景下的效果,同样使用 LLaMA-3.1-8B-Instruct 在 API-Bank 上评估。
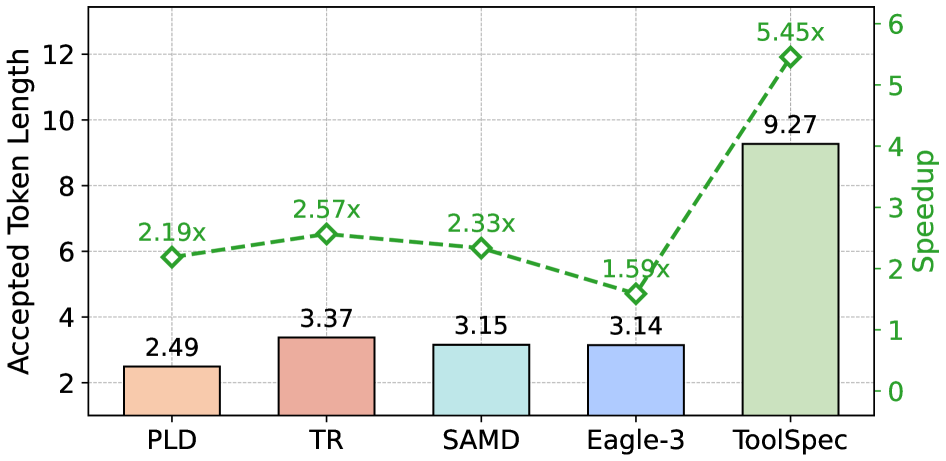
该图展示了随重复调用次数增加,#MAT(平均接受 token 数)和 speedup 的变化趋势,支持"历史检索草稿在重复场景下持续有效"这一主张。论文正文截断部分未给出具体数值,数字以图内标注为准。
结论
ToolSpec 最核心的 takeaway 是:tool calling 的结构约束性是可被 speculative decoding 深度利用的先验——schema 固定 token 可以确定性草拟、历史调用可以直接检索复用,从而在免训练条件下将 tool calling 推理加速至 4.2×,比通用 SD 方法高出最多 71%。
边界需要注意:① 实验主要覆盖 decoder-only 模型(LLaMA、Qwen2.5 系列),在其他架构或 encoder-decoder 上的泛化性未验证;② ToolSpec 的加速直接依赖模型的 format adherence,论文自己也指出,对于格式遵从率较低的模型(如 Llama-3.2-3B 在 ToolAlpaca 上仅 93.4%),效率增益会受到影响;③ retrieval 侧的有效性高度依赖历史库中存在相似调用,冷启动或工具集稀疏场景下效果有限;④ 论文未做与 Eagle 等需要训练的 SD 方法的公平比较(仅与免训练 baseline 对比),实际上 Eagle 系列在通用 SD 场景的绝对加速通常更高。
是否新瓶装旧酒
论文自述最近邻工作:
- Token Recycling(Luo et al., 2025):用邻接矩阵缓存历史 top-k 候选 token,BFS 构造草稿树——通用 SD,不感知 schema 结构。
- SAM-Decoding(Hu et al., 2025):用后缀自动机从上下文和静态语料库检索草稿——同样是通用 SD,未针对 tool calling 约束。
- Eagle 系列(Li et al., 2024/2025):需要训练轻量草稿模型,属于有训练 SD,作者将其列为参照上界。
独立评估:ToolSpec 的核心 delta 在于将"任务先验(tool schema + 历史调用库)“显式编码进 SD 的草稿生成环节,这是通用 SD 方法不做的事。FSM + 约束解码用于 tool calling 的思路在 constrained decoding 领域有先例(如 Guidance、Outlines 等),但将其与 SD 框架融合并专门针对 tool calling 加速,现有工作确实较少涉及,不属于换名微调。方法的有效性强依赖"tool calling 高度结构化"这一实证观察,该观察本身是可信的(Table 1 数据支撑)。
尚未回答的问题
- 检索库冷启动问题:retrieval-augmented speculation 在历史库为空或极小时的性能曲线未给出,实际部署时多少历史数据才能触发有效加速没有量化。
- 与有训练 SD 方法的正面比较:Eagle 系列在通用 SD 场景加速极强,ToolSpec 与其的对比仅作"讨论"处理,未做系统实验;若在 tool calling 专属数据上 fine-tune 一个小草稿模型,对比会如何。
- 参数值阶段的加速潜力:当前 $q_v$ 阶段退化为通用 SD,对于参数值本身也有规律性的场景(如日期格式、枚举值),是否有进一步结构化的空间未探讨。
- 多工具并发调用:论文分析的是单次 tool call 的生成加速,multi-tool 单次输出(一次生成多个 tool call)场景下 FSM 如何扩展未说明。
- 不同 batch size 下的 speedup 曲线:结果主要报告聚合加速比,未展示在不同 batch size / 并发度下 ToolSpec 与 baseline 的 speedup 走势差异。
原始摘要(中文翻译)
工具调用通过使大型语言模型(LLM)能够与外部应用程序交互,极大地拓展了其实际应用价值。随着 LLM 能力的持续提升,有效的工具使用越来越多地涉及多步骤、多轮次的交互,以解决复杂任务。然而,工具交互次数的增加带来了显著的延迟开销,这对实时 LLM 服务构成了重大挑战。通过实证分析,我们发现工具调用 trace 具有高度结构化的特点,严格遵循约束 schema,并且常常呈现出重复的调用模式。受此启发,我们提出了 ToolSpec——一种用于加速工具调用的 schema-aware 检索增强 speculative decoding 方法。ToolSpec 利用预定义的工具 schema 生成高质量草稿,并使用有限状态机在确定性 schema token 填充与变量字段的推测生成之间交替进行。此外,ToolSpec 还检索相似的历史工具调用并将其复用为草稿,以进一步提升效率。ToolSpec 提供了一种免训练的即插即用解决方案,可无缝集成到现有 LLM 工作流中。在多个基准测试上的实验结果表明,ToolSpec 实现了最高 4.2 倍的加速,大幅超越现有的免训练 speculative decoding 方法。