arXiv: 2604.13519 · PDF
Authors: Heming Xia, Yongqi Li, Cunxiao Du, Mingbo Song, Wenjie Li
Affiliations: The Hong Kong Polytechnic University, Peking University
Primary category: cs.CL · all: cs.CL
Matched keywords: large language model, llm, tool use, retrieval, serving, speculative decoding, latency
TL;DR
ToolSpec 是一种免训练的推测解码方法,通过有限状态机利用预定义工具 schema 确定性地生成草稿 token,并结合历史调用检索,将工具调用生成速度提升最高 4.2×。
Motivation
大型语言模型在多步骤、多轮工具调用场景下,生成延迟已成为实时服务的主要瓶颈。现有加速工作(Kim et al., 2024;Zhu et al., 2025;Xu et al., 2024;Nichols et al., 2025)聚焦于并行工具执行或将执行与生成重叠,但工具调用生成本身的效率被忽视。
作者在 ToolBench 上实测发现,Qwen2.5-14B-Instruct 的工具调用生成延迟约占端到端延迟的 80%,是工具执行时间的约 4×;随模型规模增大,该比例进一步上升至 96%(Qwen2.5-72B-Instruct)。工具执行延迟在固定环境下基本恒定,而生成延迟随模型规模和输出序列长度线性增长,使生成成为最大瓶颈。
现有通用推测解码方法(如 Token Recycling、SAM-Decoding、Eagle 系列)未利用工具调用输出高度结构化(严格 JSON schema)以及重复调用同一工具的特性,因此草稿接受率不高。ToolSpec 针对这两个特性分别设计了机制,填补了"为工具调用生成定制推测解码"这一空白。
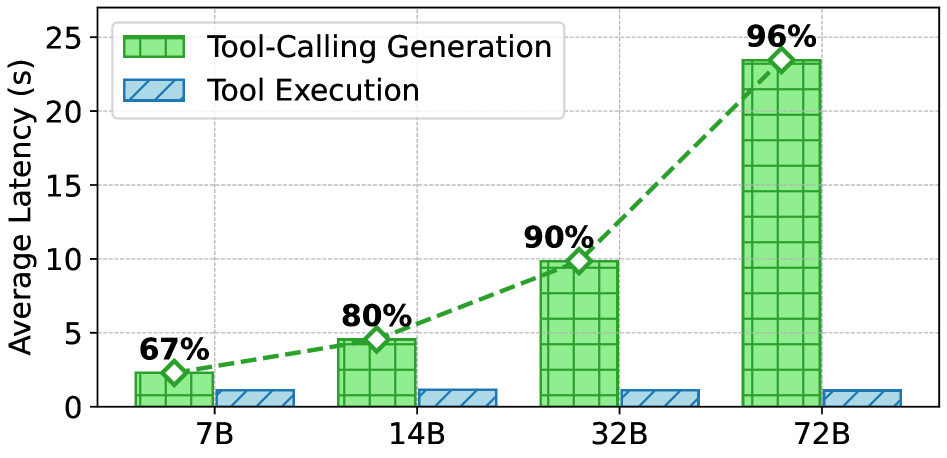
图 2 展示了 Qwen2.5-Instruct 系列在 ToolBench 上的延迟分解:工具执行延迟跨模型尺度几乎不变,而工具调用生成延迟随规模急剧增长,在 Qwen2.5-72B-Instruct 上占端到端延迟的 96%,直接量化了本文攻克的瓶颈。
Key Ideas
- 工具调用输出高度结构化:输出为 JSON,大量 token 由 schema 预先确定,仅参数值为可变字段;LLM 的 schema 遵循率超过 99%(Table 1)。
- 历史调用复现性:相同工具在不同请求中被反复调用(API-Bank 平均每工具调用 10.95 次,Table 2),历史记录可作为高质量草稿来源。
- Schema 感知草稿:有限状态机(FSM)驱动确定性 schema token 填充,并对工具名和参数名进行并行验证。
- 检索增强推测:从历史调用中检索相似记录并复用为草稿候选,进一步提升重复调用场景的效率。
- 免训练、即插即用:无需修改目标模型,可无缝集成到现有 LLM 推理流程。
Method
ToolSpec 在标准推测解码框架上构建,核心是两个互补的草稿生成策略:
Schema 感知草稿(Schema-aware Drafting):解析工具文档提取 schema,构造 FSM $\mathcal{F} = (\mathcal{Q}, \Sigma_{\text{schema}}, \delta, q_0)$,状态包括工具名状态 $q_t$、参数名状态 $q_p$、参数值状态 $q_v$ 和自然语言状态 $q_o$。触发 <tool_call> 后,FSM 进入 $q_t$,将所有候选工具名拼接 schema 前后缀构成草稿树,经目标模型单次前向传播(树状 attention mask)并行验证。验证通过后转入 $q_p$ 并行验证参数名,进入 $q_v$ 则切换为通用推测解码生成参数值。
检索增强推测(Retrieval-augmented Speculation):维护历史工具调用数据库,利用 BM25 检索与当前请求相似的历史记录,将其作为额外草稿候选,专门加速重复调用场景。

图 4 展示 FSM 的状态转移:<tool_call> 触发后进入工具名状态 $q_t$,验证通过后在参数名状态 $q_p$ 和参数值状态 $q_v$ 之间交替,参数值阶段退出 schema 约束改用通用推测解码,体现了确定性填充与自由生成的分工。
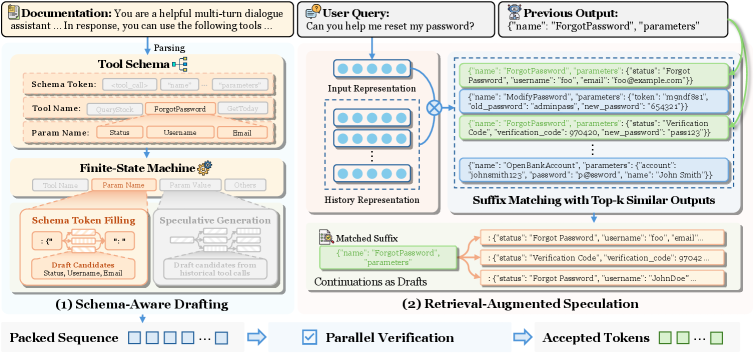
图 5 并列展示两条草稿路径:左侧 schema 感知草稿通过 FSM 枚举 schema 候选并行验证;右侧检索增强推测从历史库中召回相似调用作为草稿,二者在不同场景下互补,共同构成 ToolSpec 的完整草稿生成机制。
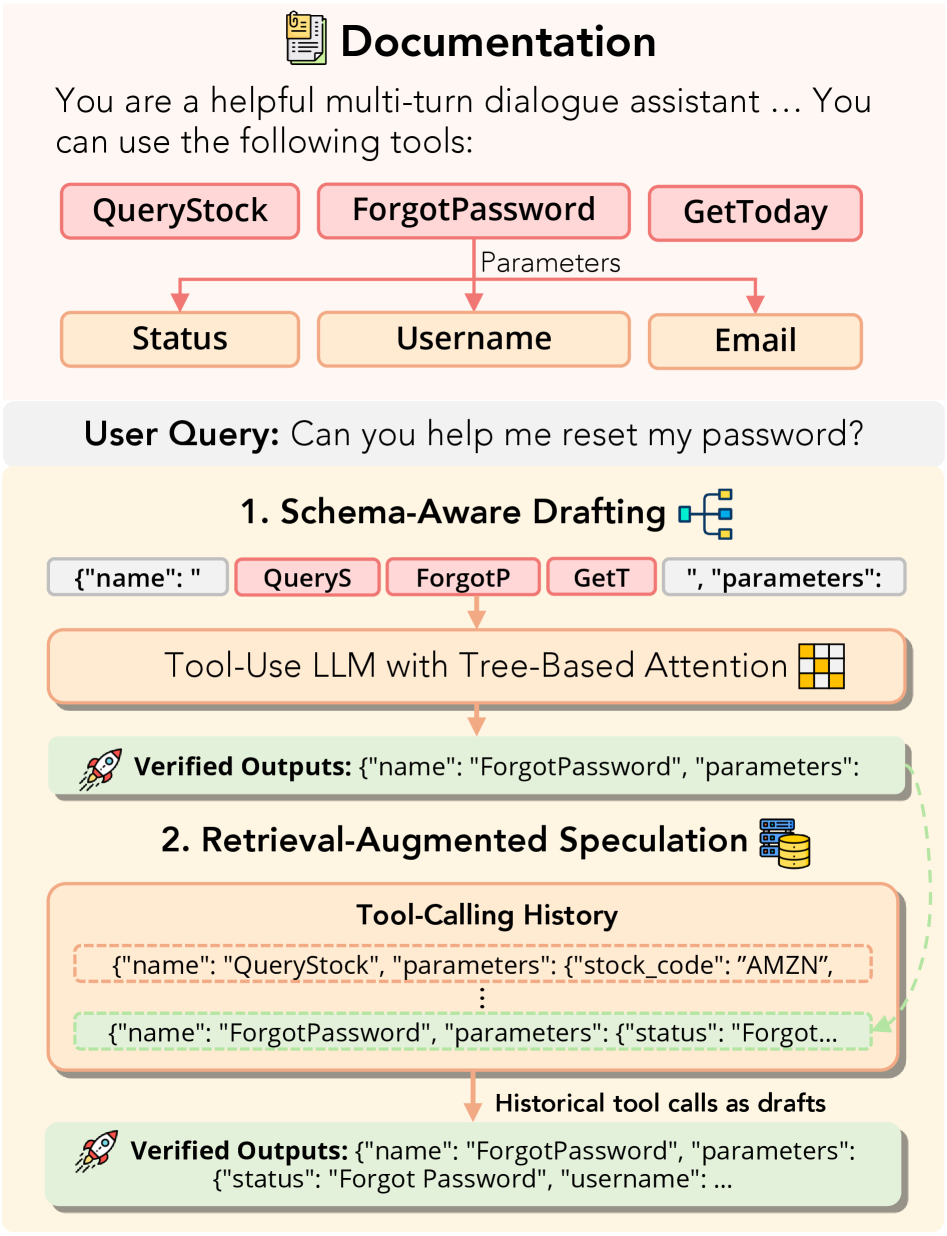
图 1 给出系统整体示意:schema 感知草稿侧重结构化字段的高精度草稿,检索增强推测侧重历史模式的复用;两者共用目标模型的并行验证步骤,草稿质量越高,每次验证接受的 token 数越多,加速比越大。
Experiments
- 数据集:API-Bank(2138 工具,5221 样本)、ToolAlpaca(426 工具,3938 样本)、BFCLv2(739 工具,2251 样本)、ToolBench(Qin et al., 2024b)(Table 2)
- 模型:LLaMA-3.1-8B-Instruct、LLaMA-3.2-3B-Instruct、Qwen2.5-7B/14B-Instruct、Qwen2.5-32B-Instruct、ToolLLaMA
- 基线:Token Recycling(Luo et al., 2025)、SAM-Decoding(Hu et al., 2025)、Eagle 系列(Li et al., 2024b/a/2025)等训练自由及训练型 SD 方法(Figure 6 对比)
- 指标:端到端加速比(Speedup)、平均接受 token 数(#MAT)、格式遵循率

图 3 展示 API-Bank 中一条真实工具调用 trace 的字段着色图,直观说明 schema token(固定脚手架)、工具/参数名(有限集合)与参数值(自由字段)的三类 token 分布——这正是实验数据集选取和指标设计的基础。
Results
ToolSpec 在多个基准上一致取得 3.5× ∼ 4.2× 加速比(摘要 / Introduction),相对前一 SOTA 训练自由 SD 方法提升最高 71%(Introduction)。
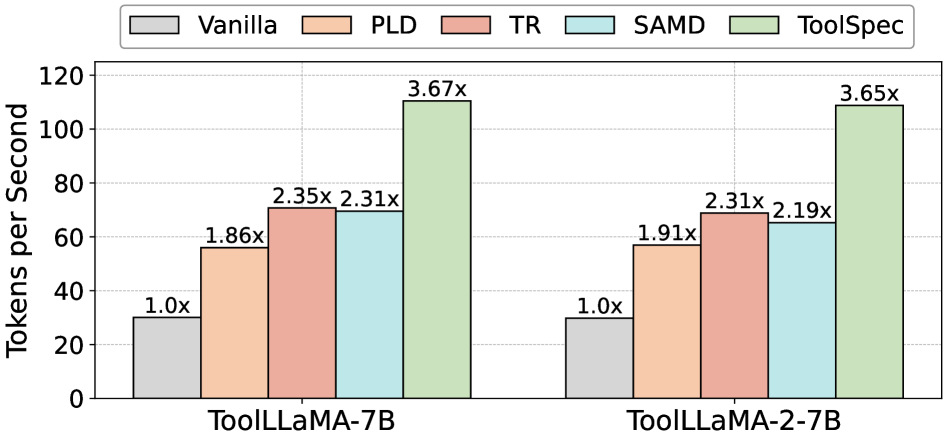
图 6 在 ToolBench 上对比 ToolSpec 与现有插件式 SD 方法的加速比:ToolSpec 明显高于所有训练自由基线(Token Recycling、SAM-Decoding 等),验证了利用工具调用结构性的核心收益;具体数值论文正文中有报告但本摘取文本截断,图中趋势明确。
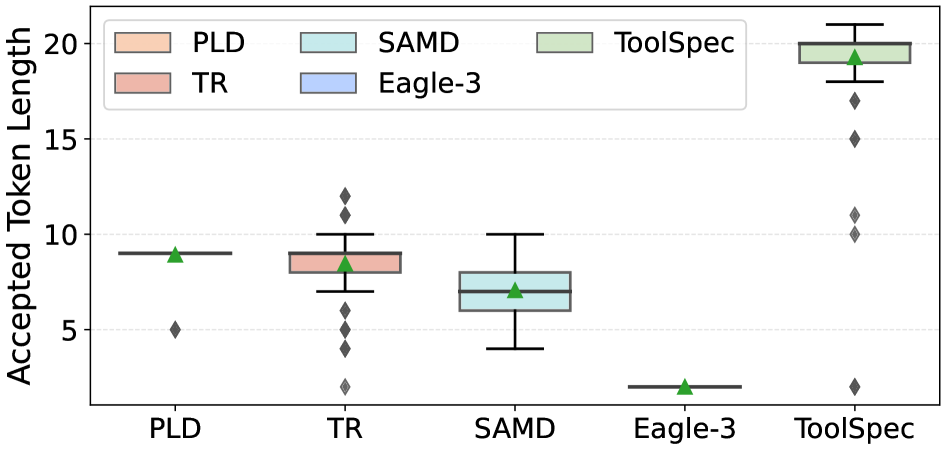
图 7 报告 LLaMA-3.1-8B-Instruct 在 API-Bank 上前两个解码步骤的接受 token 长度分布:前两步对应 FSM 的工具名状态 $q_t$ 和首个参数名状态 $q_p$,绿色三角为均值,说明 schema 感知草稿在这两个确定性状态下接受率极高,是整体加速的主要来源。
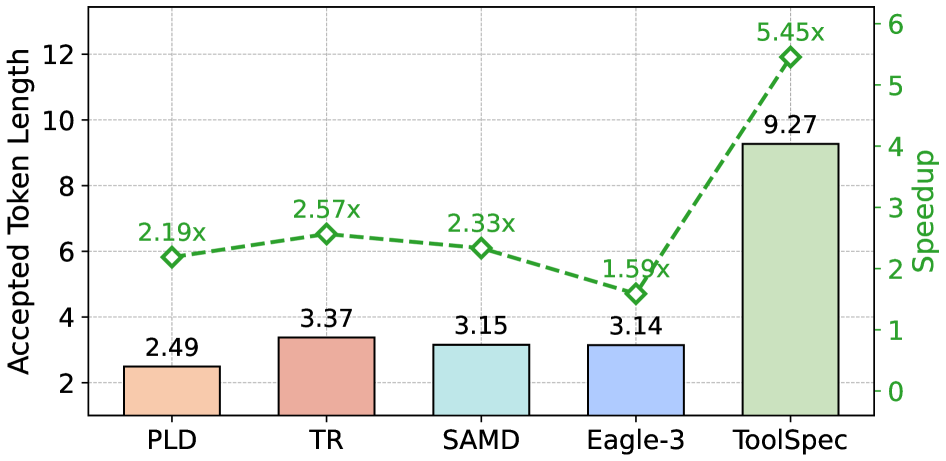
图 8 展示重复工具调用场景下的 #MAT 与加速比(LLaMA-3.1-8B-Instruct,API-Bank):检索增强推测在历史调用高度重复时进一步提升接受长度,体现两条草稿策略的互补性;具体数值论文正文截断,论文称此分析验证了检索组件的有效性。
Conclusion
ToolSpec 证明:将推测解码与工具调用的 schema 结构显式结合,可在不修改模型权重的前提下获得 3.5×–4.2× 的生成加速。最核心的发现是,工具调用生成(而非工具执行)才是多轮 agent 流水线的主要延迟瓶颈,且结构化草稿对该场景的加速效果远优于通用训练自由 SD 方法。实验在 LLaMA 和 Qwen2.5 系列(3B–32B 参数)的四个工具调用基准上建立,结论适用于遵循率高(>99%)的指令微调模型;对于格式遵循率较低的模型,论文指出加速增益会下降。论文未评估长上下文或推理型模型(如 o1 风格),也未测试 tool-calling 以外的结构化生成任务(如函数调用格式变种)。
Novelty Check
论文自引最近相关工作:Token Recycling(Luo et al., 2025)和 SAM-Decoding(Hu et al., 2025)是最近的训练自由 SD 基线;作者将 ToolSpec 定位为"首个专为工具调用结构化输出定制的推测解码方法",而非通用文本加速。
独立判断:将 FSM / 约束解码与推测解码结合在语法约束生成(如 JSON schema 采样)领域已有先例(Outlines 等库),但将其用于推测草稿生成并结合工具历史检索的组合是具体新颖的。Eagle 系列虽更快,但需要训练;ToolSpec 在免训练约束下的 4.2× 属于真实增量贡献。整体评价:是将已知技术(SD + FSM + BM25 检索)组合应用于新场景(工具调用生成),组合本身具有针对性,非简单重贴标签。
Open Questions
- 对格式遵循率低的模型(如未经专门工具微调的基础模型),FSM 误判率如何量化,加速-正确性权衡如何处理?
- 检索数据库规模增大时(真实生产中数百万历史调用),BM25 检索延迟是否仍可忽略?
- 论文分析了 schema 感知和检索增强的分别贡献,但未回答:当工具集非常大(数千工具)时,工具名并行验证的 batch 大小是否会使单次前向传播成本超过收益?
- ToolSpec 对推理型(chain-of-thought / thinking)模型的适用性未探讨——这类模型的工具调用间夹杂大量自然语言,FSM 状态切换的开销比例会显著变化。
Original abstract
arXiv:2604.13519v2 Announce Type: replace Abstract: Tool calling has greatly expanded the practical utility of large language models (LLMs) by enabling them to interact with external applications. As LLM capabilities advance, effective tool use increasingly involves multi-step, multi-turn interactions to solve complex tasks. However, the resulting growth in tool interactions incurs substantial latency, posing a key challenge for real-time LLM serving. Through empirical analysis, we find that tool-calling traces are highly structured, conform to constrained schemas, and often exhibit recurring invocation patterns. Motivated by this, we propose ToolSpec, a schema-aware, retrieval-augmented speculative decoding method for accelerating tool calling. ToolSpec exploits predefined tool schemas to generate accurate drafts, using a finite-state machine to alternate between deterministic schema token filling and speculative generation for variable fields. In addition, ToolSpec retrieves similar historical tool invocations and reuses them as drafts to further improve efficiency. ToolSpec presents a plug-and-play solution that can be seamlessly integrated into existing LLM workflows. Experiments across multiple benchmarks demonstrate that ToolSpec achieves up to a 4.2x speedup, substantially outperforming existing training-free speculative decoding methods.