arXiv: 2603.18859 · PDF
作者: Xiao Feng, Bo Han, Zhanke Zhou, Jiaqi Fan, Jiangchao Yao, Ka Ho Li, Dahai Yu, Michael Kwok-Po Ng
单位: TMLR Group, Hong Kong Baptist University, TCL Corporate Research (HK) Co Ltd, Cooperative Medianet Innovation Center, Shanghai Jiao Tong University, Department of Mathematics, Hong Kong Baptist University
主分类: cs.AI · 全部: cs.AI, cs.CL, cs.LG
命中关键词: large language model, llm, agent, agentic, rag, reasoning
TL;DR
RewardFlow 通过构建轨迹状态图并在其上进行拓扑感知的奖励传播,无需人工标注即可为 LLM agentic 推理提供稠密过程奖励,在四个 benchmark 上大幅超越现有 RL baseline。
Motivation
LLM agent 在长 horizon 顺序决策任务(如家庭控制、网页购物、深度研究)中表现不稳定——早期错误会沿着交互链快速放大,最终导致任务失败。agentic RL 理论上可以解决这个问题,但现实是:绝大多数环境只在终止状态给出一个 0/1 奖励,整条轨迹的中间步骤得不到任何信号。这种稀疏奖励结构使 credit assignment 极其困难,模型难以知道哪些中间动作是有价值的。
现有的 process reward model(PRM)方案虽然能提供中间步骤的奖励,但代价高昂:需要人工标注数据(Lightman et al., 2023)、要单独训练一个 reward model,而且策略更新后 reward model 迅速 out-of-distribution,引发 reward hacking。每一步都调用 reward model 在大规模部署时又变得极端昂贵。更重要的是,现有 PRM 通常是任务特定的,跨环境泛化性差。
直接受苦的是需要训练 LLM agent 的研究者和工程师——他们现在只能靠终止奖励做 GRPO/RLOO 之类的算法将就,或者投入巨量资源标注 PRM 数据。RewardFlow 的出发点是:多条 sampled 轨迹本身已经隐含了状态的拓扑关系——相同的状态会被多条轨迹反复经过,这种重现结构可以作为 process reward 的代理信号,无需任何外部标注。
核心观点
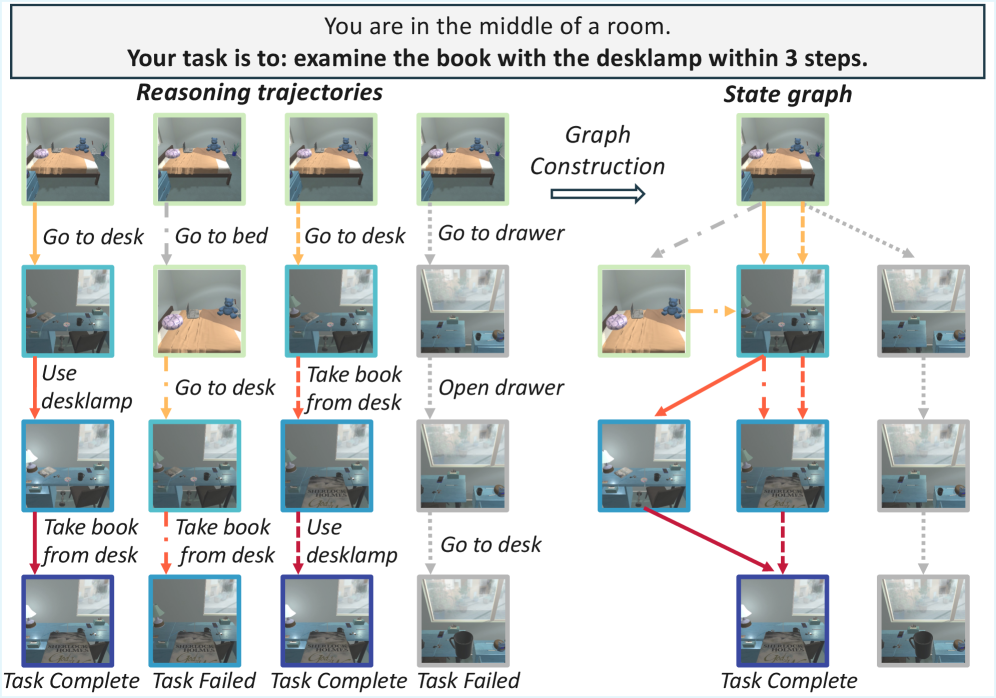
上图将多条轨迹合并为状态节点 + 动作边的有向图,颜色深浅表示到成功节点的距离(越深越近),灰色节点为不可达。这一可视化直接支撑了 RewardFlow 的核心主张:轨迹的拓扑结构本身已经编码了每个状态对任务成功的贡献程度,无需外部 reward model 即可读出。
- 状态图建模:将 agentic 推理中的多条采样轨迹聚合为状态图,等价状态合并为同一节点,消除表示冗余
- 拓扑感知奖励传播:利用图上最短路径距离从成功节点向后传播奖励,近成功节点得高奖励,不可达节点得零奖励
- 无标注稠密奖励:整个过程不依赖人工标注和单独训练的 reward model,annotation-free
- 动作级奖励整形:将传播后的状态奖励映射回轨迹,用"到达状态奖励 − 出发状态奖励"作为每个动作的细粒度奖励
- 双层优势估计:结合局部 action-level 奖励与全局 trajectory-level 优势,提供稳定的策略更新
方法
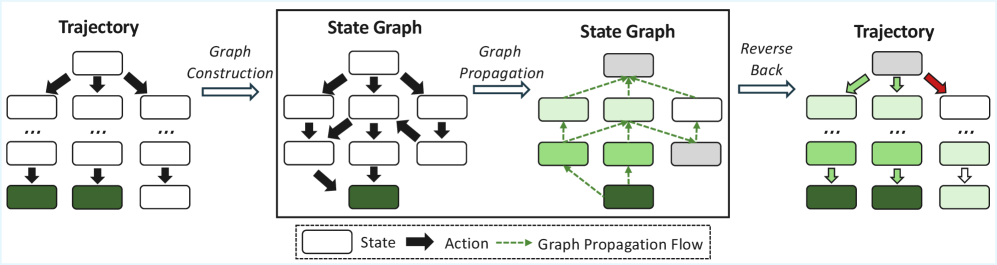
上图展示了 RewardFlow 的完整 pipeline,三阶段设计清晰:左侧构图、中间传播、右侧映射回轨迹。每个矩形节点代表一个状态,颜色代表奖励等级,从图中可以直接看到奖励如何从成功节点(亮色)逐步向上游扩散。
步骤一:状态图构建。给定 G 条采样轨迹,先对状态做归一化(f(s)),将语义等价的状态映射到同一 canonical 表示——对文本环境用精确匹配,对 DeepResearch 等复杂环境用 embedding 余弦相似度(阈值 τ)。然后过滤 LLM 幻觉出的环境无效动作(valid(s, a, s')=0 的边),防止伪边污染图结构(Fig. 4)。最终建立状态图 G_state = (S, A, T),节点是唯一状态,有向边是有效动作转移。
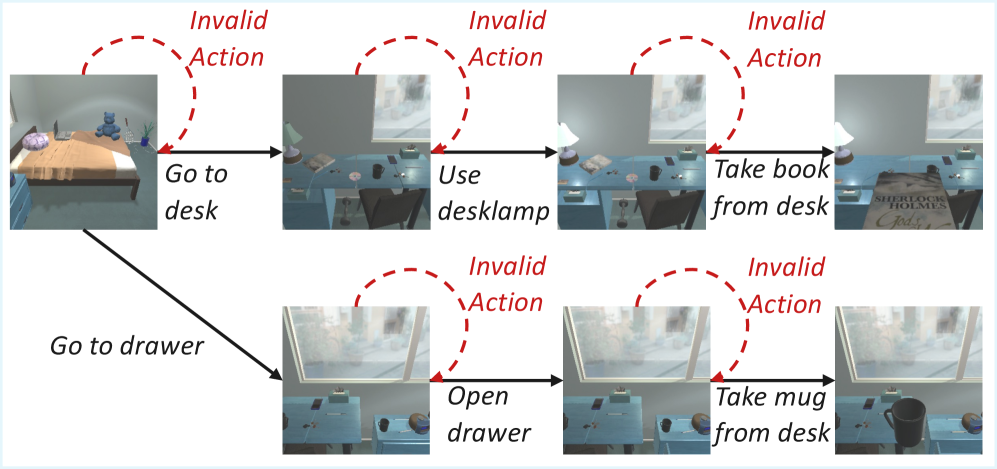
LLM 会生成语法合理但环境不接受的动作(如"pick up nonexistent object"),这类无效动作在图中产生虚假的边,干扰可达性分析。图 4 说明了过滤这类伪边的必要性——不过滤则状态间的拓扑关系被污染,传播出的奖励失去意义。
步骤二:图上奖励传播。以 BFS 为主要传播策略,从成功终止状态集 S_succ 出发,反向传播奖励:距离成功节点 d 步的状态获得衰减后的奖励(实现为 r_max · γ^d 形式)。两个关键属性驱动传播:可达性(该状态是否有路径通往成功)和中心性(状态的入/出度,高中心度状态往往是任务关键节点),见 Fig. 5。
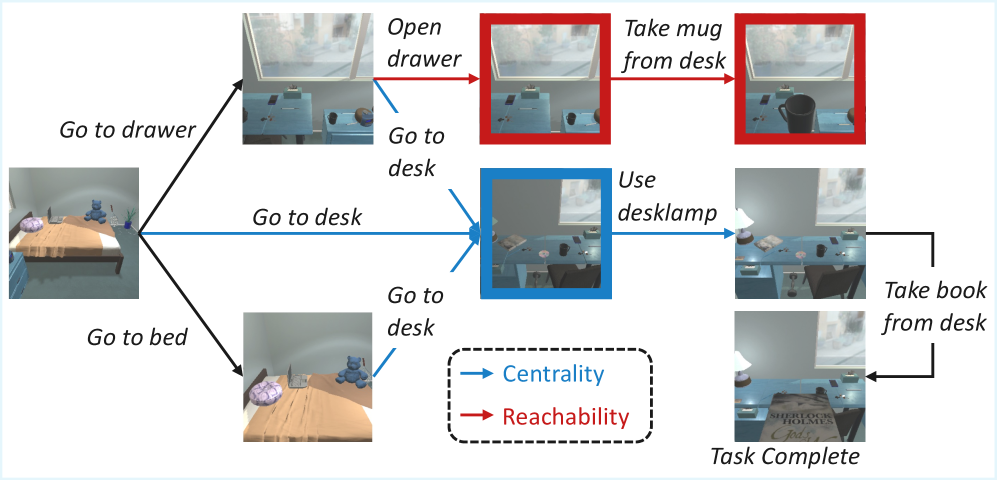
图 5 用一个具体例子标注了可达性与中心性:红色节点为不可达(无路径到达成功状态),“Go to desk"对应的节点出度高,是通往多个必要物品的关键枢纽,因此获得较高奖励。这两种属性共同决定了每个状态对任务成功的贡献值。
步骤三:动作级奖励整形与策略优化。将传播后的节点奖励 V(s) 映射回原始轨迹:动作 a_t 的奖励定义为 r_action = V(s_{t+1}) - V(s_t),即前后状态价值的差(增量奖励)。最终优势估计结合动作级奖励(α_action 加权)与轨迹级组归一化优势(α_traj 加权),通过 PPO clip 目标更新策略。
实验
数据集:ALFWorld(室内家务文本 agent)、WebShop(网页购物文本 agent)、Sokoban(视觉推箱子)、DeepResearch(多步搜索研究,视觉+文本)
Baseline:
- 稀疏奖励 RL:GRPO、RLOO、GiGPO(最强 baseline)
- PRM 方法:Math-Shepherd、MCTS-based PRM、LLM-as-PRM
模型规模:Qwen2.5-1.5B、Qwen2.5-3B、Qwen2.5-7B(文本);Qwen2.5-VL-3B(视觉)
硬件:论文未在正文中详细说明具体 GPU 配置
结果
主要性能提升:与最强 baseline GiGPO 相比,RewardFlow 在文本 benchmark(ALFWorld + WebShop + Sokoban)上平均成功率提升 +6.2%,在视觉推理(Sokoban 视觉版)上跨三种模型规模提升 +29.7%(abstract 数据)。在 DeepResearch 上超越 Search-R1 +10%(abstract 数据)。
样本效率(Figure 9):
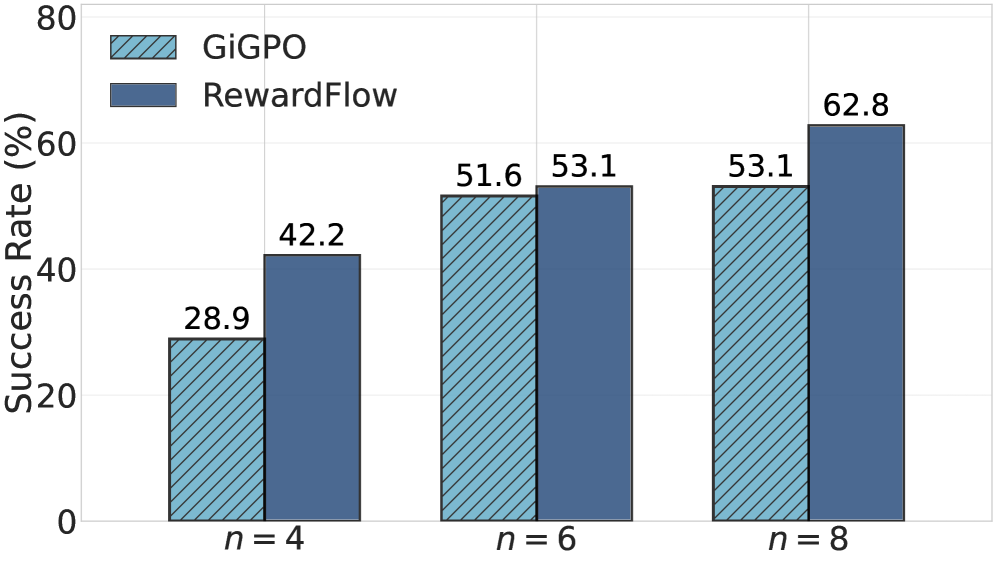
图 9 在 ALFWorld 上用 Qwen2.5-1.5B 测试了 rollout budget 从 4 到 8 时的表现。RewardFlow 在所有 budget 下均优于 GiGPO,在 budget=4 时差距最大,达到 +13.3%,随着 budget 增大优势仍持续存在。这说明 RewardFlow 在样本极度受限时尤其有效,对需要控制推理成本的实际部署有直接意义。
OOD 泛化(Table 3,即图 6):
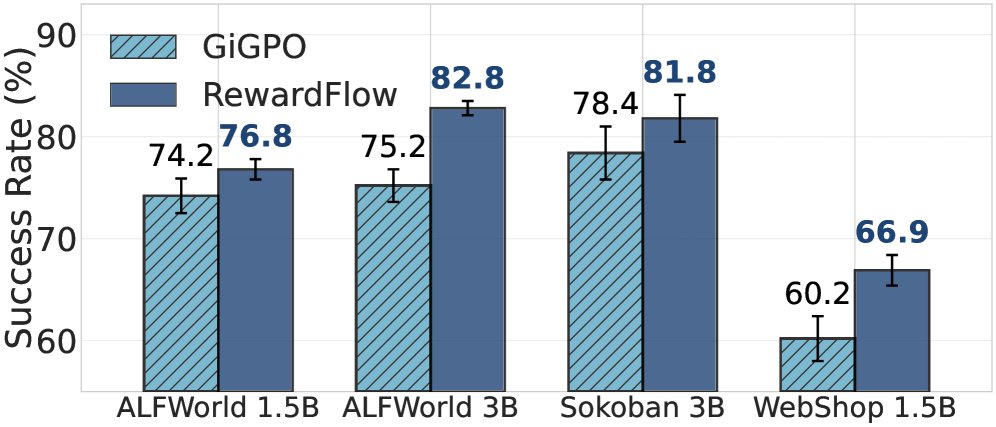
Table 3 报告了在 ALFWorld 上完全陌生的新环境(不同房间布局、家具)下的 OOD 泛化结果(平均成功率,越高越好)。RewardFlow 在无需训练 reward model 的情况下超越了所有 PRM-based baseline。具体数字论文正文在截断部分,完整数值参见原文 Table 3。
超参数鲁棒性(Figure 10):
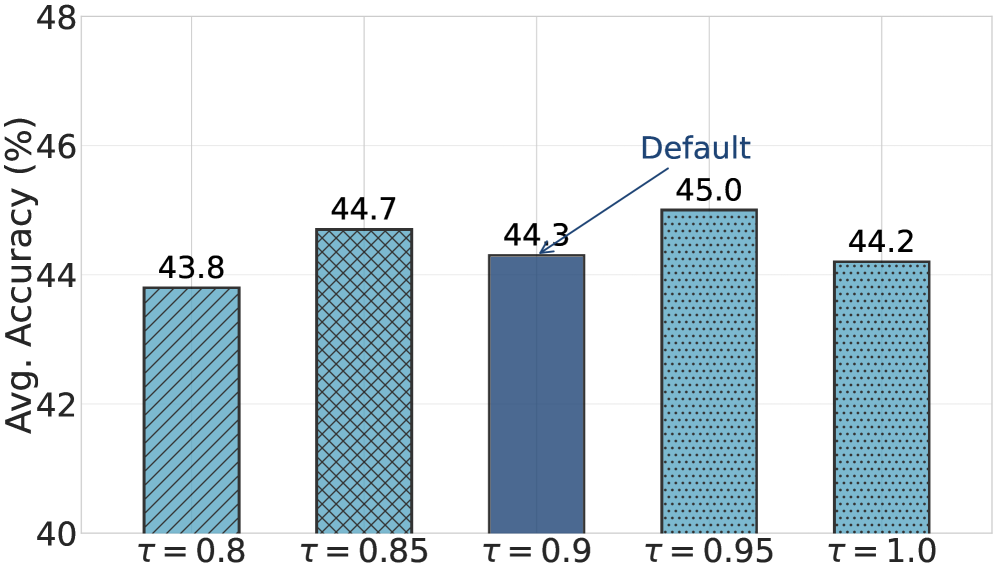
状态合并阈值 τ 在 [0.80, 1.00] 整个范围内变化时,DeepResearch 上的平均准确率(Qwen2.5-3B)波动仅 1.2 个百分点(Fig. 10)。这说明 RewardFlow 对这个关键超参数的选择不敏感,工程部署时无需仔细调参。
结论
最值得带走的一个结论是:利用多条轨迹聚合出的状态图拓扑结构,可以在无需任何外部标注的前提下估计出有效的过程奖励,且效果超越了需要大量资源训练的 PRM。支撑这一点最有力的数字是视觉推理上 +29.7% 的提升,以及仅 4 条 rollout 时 +13.3% 的优势(体现了在信号极稀疏时的增益最大这一规律)。
边界说明:
- 实验验证集中在相对小型模型(1.5B–7B),7B 以上的规模行为未知;
- 四个 benchmark 以家务、购物、推箱子、信息检索为主,尚未在代码生成、工具调用密集型 agent 或机器人控制上验证;
- 状态归一化方案(精确匹配 vs 嵌入聚合)在不同环境中差别较大,通用性取决于状态表示工程;
- 标题强调"annotation-free”,但构图过程仍需要环境能明确判断
valid(s,a,s'),这在黑盒或部分可观测环境中可能不成立; - 缺少对奖励冲突(同一状态在不同轨迹中奖励方向相反)的系统性 ablation,论文附录 C.6 有讨论但未提供定量结果。
是否新瓶装旧酒
论文自述最相近前人工作:
- GiGPO(Feng et al., 2025):同样做状态级别的优势估计,但沿单条轨迹反向传播,不跨轨迹聚合状态,也不利用图拓扑结构。RewardFlow 的 delta 是跨轨迹构图 + 可达性/中心性两个图属性驱动的传播。
- PRM with human annotation(Lightman et al., 2023; Wang et al., 2025a):需要人工标注,RewardFlow 完全无标注。
- GRPO/RLOO:仅使用终止奖励,无法做中间步骤的 credit assignment。
独立判断:
RewardFlow 的核心思路——把多条轨迹合并成状态图再做值传播——在概念上与 MCTS + 值估计有相似之处,也与图强化学习中的图构建方法存在关联。论文本身在附录 C.1 中讨论了与 Potential-Based Reward Shaping 和 Reward Machines 的关系,这说明作者有意识到这些关联。主要新颖之处在于将这套思路适配到 LLM agentic 场景(非预设的结构化环境),并结合 embedding 归一化处理高维文本状态。这是一项有实质工程和实验贡献的工作,但理论上并非全无先例。
尚未回答的问题
- 大模型规模外推:实验止步于 7B,70B 甚至更大模型下状态图规模会急剧膨胀,图构建和传播的计算代价以及奖励信号质量如何变化?
- 部分可观测环境:当环境不能提供明确的
valid信号时(如黑盒 API、网页 agent),无效动作过滤如何处理? - 奖励冲突的定量影响:同一状态出现在成功和失败轨迹中时奖励如何裁决,缺少系统的 ablation(论文附录 C.6 仅做了定性分析)。
- 跨任务迁移:每个任务单独构图意味着图只在单任务内有效——能否跨任务共享图结构,减少 cold-start 代价?
- 连续动作空间:当前实验均为离散动作环境,方法在连续动作(如机器人控制)下的可行性未验证。
原始摘要(中文翻译)
强化学习(RL)在增强 LLM agent 推理能力方面展现出良好前景,然而稀疏的终止奖励阻碍了细粒度优化。过程奖励建模提供了一种替代方案,但会带来高计算成本、奖励 hacking 风险和标注瓶颈。我们提出 RewardFlow,一种用于 agentic 推理中状态级奖励估计的轻量级方法。通过构建捕捉轨迹内在拓扑结构的状态图,RewardFlow 执行拓扑感知的传播,估计每个状态对成功的贡献,从而产生原则性的、无需标注的稠密奖励。用于 RL 优化时,RewardFlow 在四个 agentic benchmark 上大幅超越此前 baseline:在文本任务上平均成功率提升 +6.2%,在视觉推理上跨三种模型规模超越最强 baseline +29.7%,在 DeepResearch 上准确率提升 +10%,同时具有更优的鲁棒性和训练效率。RewardFlow 的实现已公开发布于 https://github.com/tmlr-group/RewardFlow。