arXiv: 2603.18859 · PDF
Authors: Xiao Feng, Bo Han, Zhanke Zhou, Jiaqi Fan, Jiangchao Yao, Ka Ho Li, Dahai Yu, Michael Kwok-Po Ng
Affiliations: TMLR Group, Hong Kong Baptist University, TCL Corporate Research (HK) Co Ltd, Cooperative Medianet Innovation Center, Shanghai Jiao Tong University, Department of Mathematics, Hong Kong Baptist University
Primary category: cs.AI · all: cs.AI, cs.CL, cs.LG
Matched keywords: large language model, llm, agent, agentic, rag, reasoning
TL;DR
RewardFlow builds a state graph from sampled agentic trajectories and propagates BFS-based rewards from success nodes to intermediate states, providing annotation-free dense process rewards that improve RL training across four agentic benchmarks without any reward model.
Motivation
Agentic RL training for LLMs suffers from sparse terminal rewards: the agent completes an entire multi-step trajectory and receives only a single binary outcome signal. This coarse signal makes credit assignment difficult—early missteps receive the same zero reward as genuinely neutral actions, compounding errors over long horizons. The standard fix, process reward modeling (PRM), requires separately trained reward models with human-annotated step labels, introducing data bottlenecks, substantial compute overhead, and reward hacking: once the policy updates, the static scorer drifts out-of-distribution and assigns inflated rewards to novel outputs. Existing group-sampling RL methods like GRPO and RLOO assign the same terminal reward uniformly to every token in a trajectory, and even the closest prior work, GiGPO, propagates rewards along individual trajectories without exploiting shared topological structure across rollouts. The missing insight is that LLMs sample overlapping state sequences: across a group of rollouts, the number of unique states is substantially smaller than total state visits (confirmed empirically on ALFWorld, WebShop, Sokoban, and DeepResearch). This redundancy enables a consolidated state graph that reveals reachability and proximity to success—information no single trajectory exposes—making principled, annotation-free dense reward estimation tractable.
Key Ideas
The state graph motivating RewardFlow—trajectories merged into unique nodes with directed action edges, colored by distance to success—illustrates how topology encodes reward signal that single-trajectory methods miss.
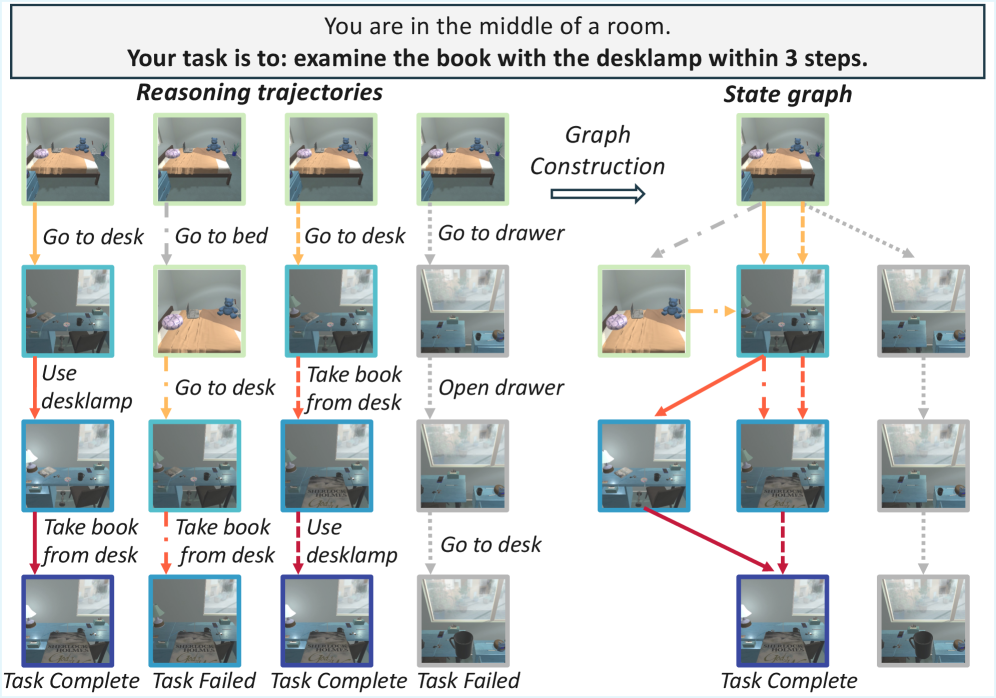 States closer to a success node (darker color) should receive higher rewards; grey nodes have no path to success and should be penalized. This topological signal is invisible in per-trajectory reward propagation.
States closer to a success node (darker color) should receive higher rewards; grey nodes have no path to success and should be penalized. This topological signal is invisible in per-trajectory reward propagation.
- State graph construction: equivalent states across G sampled rollouts are merged into unique nodes; environment-invalid (hallucinated) actions are pruned to eliminate spurious edges.
The bar charts below confirm the compression that makes graph construction worthwhile: across all four benchmarks, unique states are substantially fewer than total state visits, so aggregating trajectories into a graph recovers far richer structure than any single rollout.
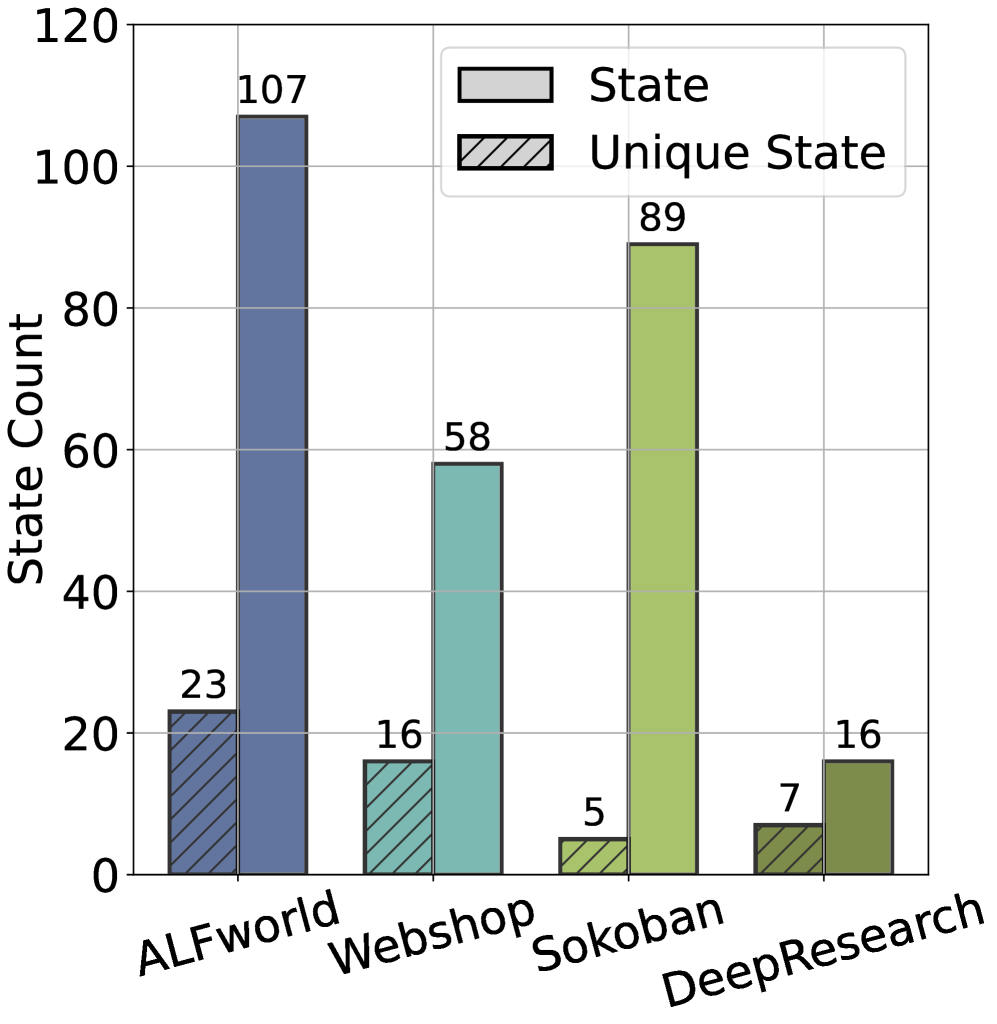 On ALFWorld, WebShop, Sokoban, and DeepResearch with Qwen2.5-(VL)-3B-Instruct, unique state and action counts compress significantly versus cumulative visit counts, validating that a shared graph captures the task structure no individual trajectory can.
On ALFWorld, WebShop, Sokoban, and DeepResearch with Qwen2.5-(VL)-3B-Instruct, unique state and action counts compress significantly versus cumulative visit counts, validating that a shared graph captures the task structure no individual trajectory can.
- Topology-aware propagation: BFS backward from success nodes assigns each state a reward proportional to its shortest-path distance to success; unreachable states receive no positive reward.
- Action-level reward shaping: per-action reward is the gain (difference) between post-action and pre-action state rewards, giving dense step-level supervision.
- Synergistic advantage: policy is updated with a combined objective integrating action-level rewards and trajectory-level group normalization.
Invalid actions must be filtered before graph construction; without pruning, LLM hallucinations create spurious edges that distort reachability and centrality estimates.
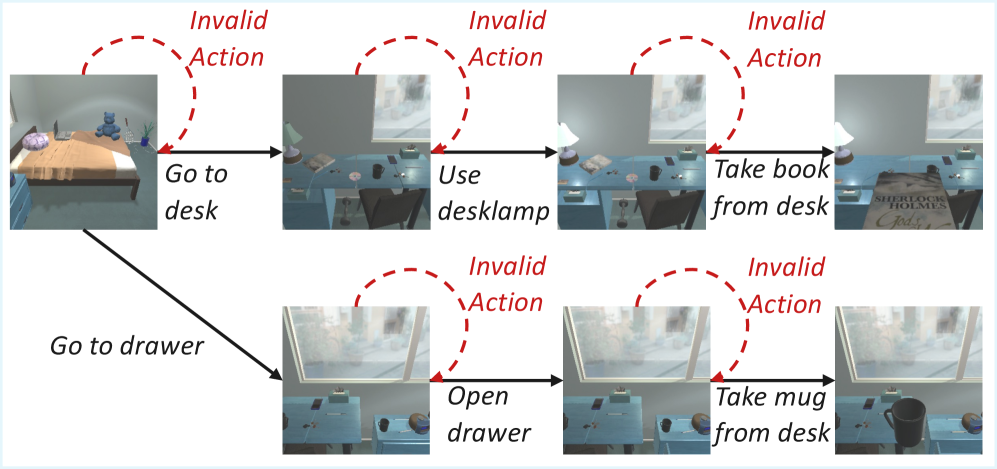 The figure shows how a hallucinated action creates a phantom edge connecting states that are not actually reachable from each other—omitting this step would corrupt both reward propagation and the resulting policy gradient.
The figure shows how a hallucinated action creates a phantom edge connecting states that are not actually reachable from each other—omitting this step would corrupt both reward propagation and the resulting policy gradient.
Method
RewardFlow operates in three stages, illustrated end-to-end below.
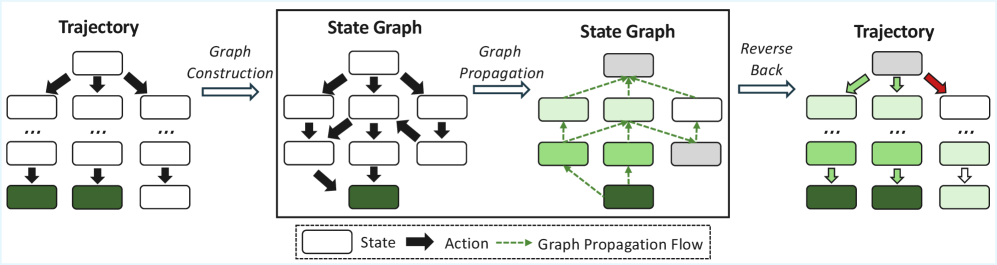 The pipeline covers (1) graph construction from G sampled trajectories, (2) backward BFS propagation from success terminal states assigning reward levels to intermediate nodes, and (3) mapping propagated state rewards back to raw trajectories as action-wise reward gains.
The pipeline covers (1) graph construction from G sampled trajectories, (2) backward BFS propagation from success terminal states assigning reward levels to intermediate nodes, and (3) mapping propagated state rewards back to raw trajectories as action-wise reward gains.
Graph construction: states are canonicalized via a normalization function f (exact string matching for structured environments; embedding-based cosine-similarity clustering with threshold τ for open-ended environments like DeepResearch). Invalid actions are filtered by checking whether the environment transition actually occurred. The graph G_state = (S, A, T) is the union of all valid transitions across all G rollouts.
Reachability and centrality (Fig. 5) are the two structural properties extracted: reachability flags whether any observed path leads to a success terminal; centrality (in/out degree) identifies bottleneck states.
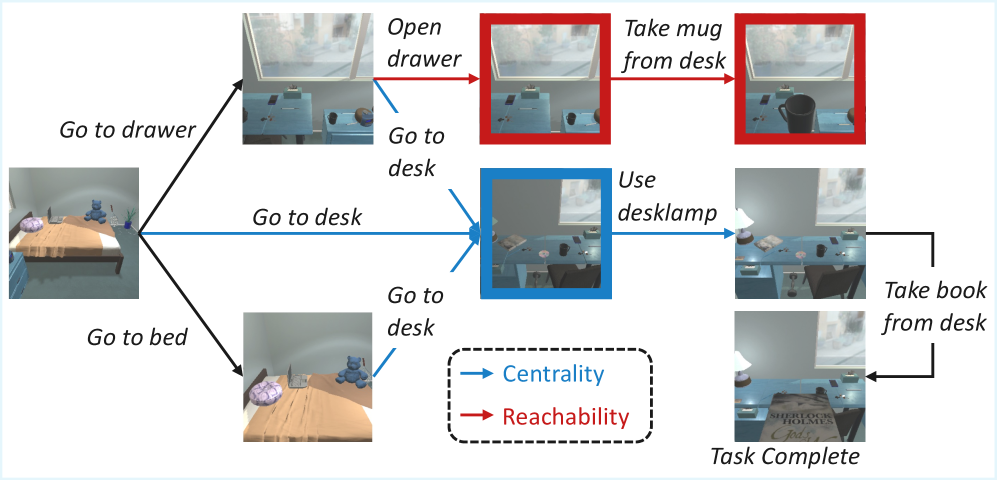 The “Go to desk” state has high out-degree—it provides access to both a desklamp and a book needed for task success—making it a high-centrality node that should receive elevated reward regardless of which downstream trajectory succeeded.
The “Go to desk” state has high out-degree—it provides access to both a desklamp and a book needed for task success—making it a high-centrality node that should receive elevated reward regardless of which downstream trajectory succeeded.
Reward propagation: BFS assigns reward r(s) = 1/(1+d(s, S_succ)) for reachable states, where d is shortest-path distance. Action reward: r_action(a_t) = r(s_{t+1}) − r(s_t). Policy update: clipped surrogate objective (PPO-style) using advantages that blend action-level and trajectory-level signals via mixing weights α_action and α_traj.
Experiments
Benchmarks: ALFWorld (text-based household tasks), WebShop (web shopping), Sokoban (visual puzzle), DeepResearch (multi-hop web research). Baselines: GRPO, RLOO, GiGPO (strongest RL baseline); PRM-based methods; Search-R1 (on DeepResearch). Models: Qwen2.5-1.5B, Qwen2.5-3B, Qwen2.5-VL-3B-Instruct (three scales as stated in abstract). Hardware/scale: not quantified in the paper text.
Results
RewardFlow gains +6.2% average success rate on text-based tasks (ALFWorld, WebShop, Sokoban) and +29.7% on visual reasoning (Sokoban with VL model) over GiGPO, the strongest RL baseline, across three model scales (abstract). On DeepResearch it surpasses Search-R1 by over 10% across model sizes (introduction).
Rollout-budget robustness (Fig. 9): at only 4 rollouts on ALFWorld (Qwen2.5-1.5B), RewardFlow beats GiGPO by +13.3%, and maintains a substantial advantage as the budget grows to 8.
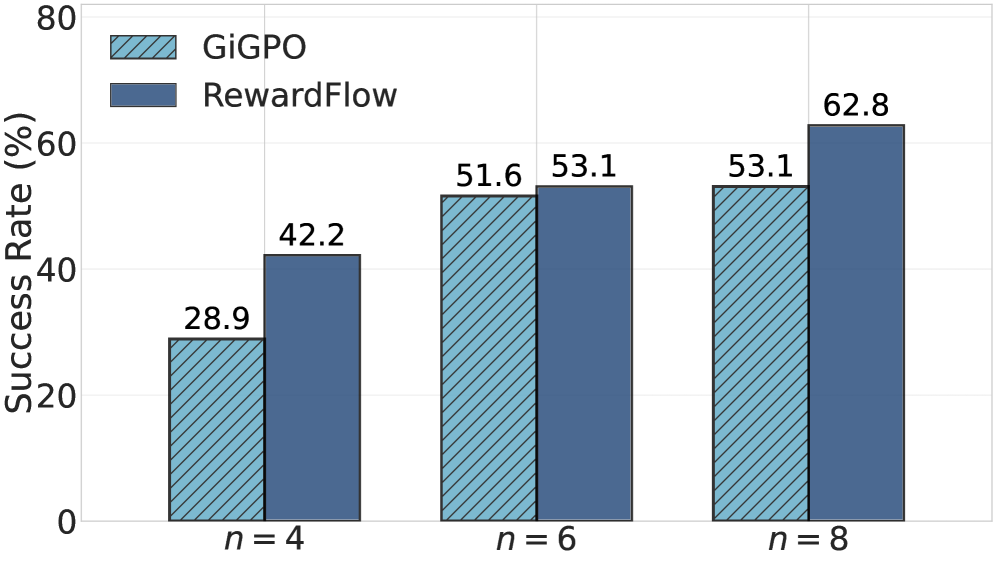 The line chart shows RewardFlow consistently above GiGPO at every rollout budget from 4 to 8; the largest gap (+13.3%) occurs at the smallest budget, indicating RewardFlow extracts more signal per rollout—important for compute-constrained training.
The line chart shows RewardFlow consistently above GiGPO at every rollout budget from 4 to 8; the largest gap (+13.3%) occurs at the smallest budget, indicating RewardFlow extracts more signal per rollout—important for compute-constrained training.
Out-of-distribution generalization (Table 3): RewardFlow outperforms all baselines including PRM-based methods on ALFWorld with novel room layouts; exact numbers from Table 3 are not available in the truncated full text.
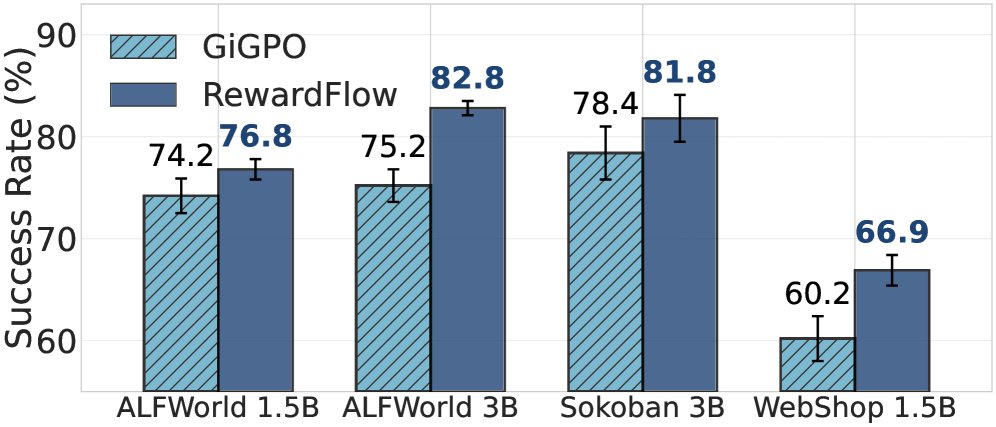 Table 3 reports average success rate (%) on held-out ALFWorld environments with unfamiliar rooms and furniture arrangements; RewardFlow without any reward model training surpasses PRM-based baselines, supporting the claim of better generalization.
Table 3 reports average success rate (%) on held-out ALFWorld environments with unfamiliar rooms and furniture arrangements; RewardFlow without any reward model training surpasses PRM-based baselines, supporting the claim of better generalization.
Hyperparameter sensitivity (Fig. 10): varying the cosine-similarity threshold τ across [0.80, 1.00] on DeepResearch (Qwen2.5-3B) changes average accuracy by only 1.2 percentage points, confirming robustness to this design choice.
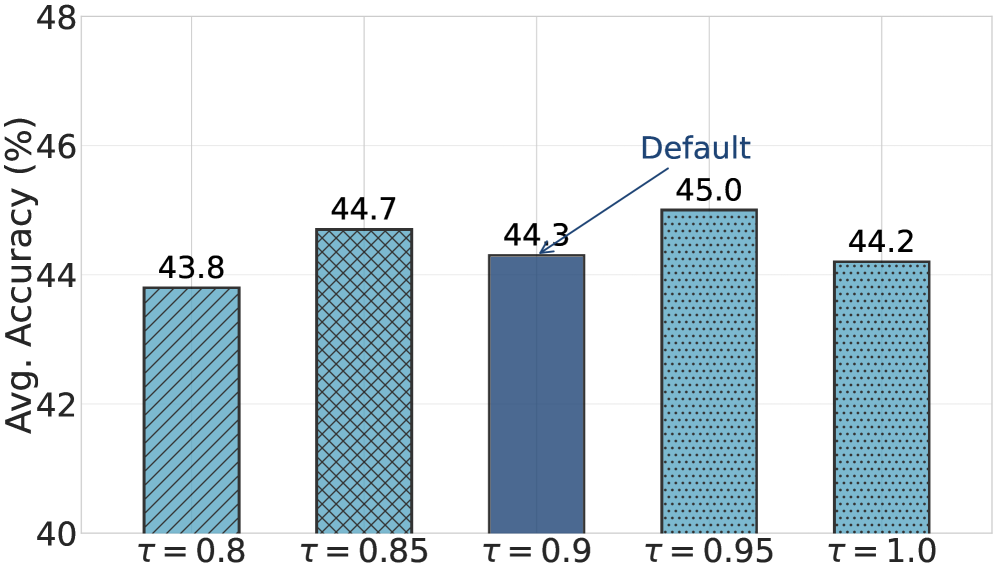 The flat accuracy curve across the full τ range means practitioners do not need to tune this threshold carefully—any value in [0.80, 1.00] yields near-identical results on DeepResearch.
The flat accuracy curve across the full τ range means practitioners do not need to tune this threshold carefully—any value in [0.80, 1.00] yields near-identical results on DeepResearch.
Conclusion
RewardFlow demonstrates that aggregating sampled trajectories into a state graph and running BFS from success nodes yields dense, annotation-free process rewards that substantially improve agentic RL—+6.2% on text tasks, +29.7% on visual reasoning, +10% on DeepResearch over strong baselines. The result is established at small model scales (1.5B–3B parameters) on four benchmarks; whether gains hold at 7B+ or in production-scale agentic systems is untested. The title’s claim of “topology-aware” propagation is accurate but simple BFS suffices—no GNN or learned propagation is used. Ablations on the BFS vs. PPR propagation strategy and mixing weights α are mentioned but their numbers are not available in the truncated text.
Novelty Check
The paper’s own Related Work identifies GiGPO (Feng et al., 2025b) as the closest prior work. The authors’ stated delta: GiGPO propagates rewards backward along individual trajectories without exploiting cross-trajectory topological structure; RewardFlow merges equivalent states across rollouts into a shared graph before propagating. This is a genuine structural distinction—multi-trajectory state aggregation before reward estimation is not present in GiGPO. The connection to potential-based reward shaping (acknowledged in Appendix C.1) is honest. The core graph construction idea has conceptual overlap with model-based RL and Monte Carlo Tree Search planning, but applying it specifically to LLM-sampled trajectory aggregation for annotation-free PRM replacement is a legitimate contribution at this scope.
Open Questions
- Do gains scale to models larger than 3B, where unique-state compression may be lower relative to trajectory length?
- BFS assigns reward by hop count; does a learned propagation (GNN, PPR) provide better credit assignment on tasks with non-uniform action costs?
- The method requires environment feedback to detect invalid actions—how does it degrade in environments where validity signals are noisy or absent?
- The +29.7% visual reasoning gain is large; ablations isolating whether it comes from the graph structure or simply from more diverse sampling across rollouts are not reported.
Original abstract
arXiv:2603.18859v2 Announce Type: replace Abstract: Reinforcement learning (RL) shows promise for enhancing LLM agentic reasoning, yet sparse terminal rewards hinder fine-grained optimization. Process reward modeling offers an alternative but incurs high computational costs, reward hacking risks, and annotation bottlenecks. We introduce RewardFlow, a lightweight method for estimating state-level rewards in agentic reasoning. By constructing state graphs that capture the intrinsic topological structure of trajectories, RewardFlow performs topology-aware propagation to estimate each state’s contribution to success, yielding principled, annotation-free dense rewards. Used for RL optimization, RewardFlow substantially outperforms prior baselines across four agentic benchmarks: +6.2% average success rate on text-based tasks, +29.7% on visual reasoning over the strongest baseline across three model scales, and +10% accuracy on DeepResearch, with superior robustness and training efficiency. The implementation of RewardFlow is publicly available at https://github.com/tmlr-group/RewardFlow.