arXiv: 2605.29796 · PDF
作者: Yunbo Tang, Chengyi Yang, Shiyu Liu, Zhishang Xiang, Zerui Chen, Qinggang Zhang, Jinsong Su
单位: School of Informatics, Xiamen University, Jilin University
主分类: cs.AI · 全部: cs.AI, cs.CL, cs.LG
命中关键词: llm, agent, agentic, rag, reasoning, inference, latency
TL;DR
SAAS 提出三组件 RL 框架,通过动态建模"搜索边界"抑制 agentic search 中的过搜索问题,在 7 个 QA benchmark 上保持精度的同时大幅削减冗余检索。
Motivation
LLM agentic search 通过迭代推理+外部检索处理复杂多跳问题效果显著,但存在严重的"过搜索"(over-search)痼疾:模型在参数知识已足够时仍触发搜索,或在已收集充分证据后仍持续检索。这两类浪费直接推高推理延迟和计算成本,同时引入噪声证据干扰最终答案——受影响的是任何在生产中部署 agentic RAG 系统的团队。
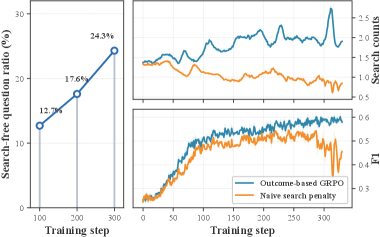
现有方案分两类:提示/路由类(DRAGIN、Adaptive-RAG)依赖静态启发规则,RL 类(StepSearch、HiPRAG)依赖固定惩罚阈值。两者的共同缺陷是"静态"——都无法感知模型能力的动态变化。关键数据:随着训练推进,不需要搜索就能答对的问题比例从 step 100 的 12.7% 上升到 step 300 的 24.3%(Figure 3)。搜索边界本身在移动,固定惩罚在 step 250 附近会引发 reward hacking 和性能崩溃。
前提条件的变化:RL 训练动态本身是可测量的——可以在每个训练步在线对比有搜索/无搜索 rollout,从而动态识别当前策略的搜索边界,这正是 SAAS 的切入点。
核心观点
下图展示了 SAAS 要解决的两类过搜索失效模式:左侧是"不必要搜索"(参数知识已足够却仍调用搜索工具),右侧是"冗余搜索"(外部证据已充分仍继续检索)。两者都造成推理成本浪费。
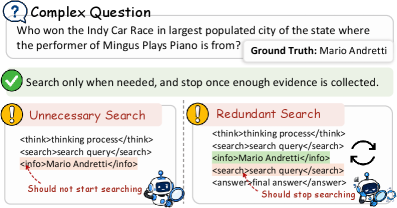
Figure 3 量化了静态惩罚的局限:随着训练推进,可无搜索答对的问题比例从 12.7% 上升到 24.3%,说明搜索边界是随模型能力演化的动态量。朴素搜索惩罚虽能压低搜索次数,但导致 step 250 附近性能崩溃,说明固定阈值不能区分"合理克制"与"放弃必要搜索"。
- 识别 agentic search 中过搜索的根因:outcome-based RL 缺乏对搜索必要性的显式信号
- 提出 SAAS,动态建模随策略演化的搜索边界,而非依赖静态阈值
- 设计 Boundary-Aware Reward,将边界感知转化为轨迹级自适应惩罚,区分必要与冗余搜索
- 引入 Stage-wise Optimization,优先推理探索再施加搜索正则,防止 reward hacking
- 在 7 个 benchmark 上验证,精度不损失的前提下显著减少过搜索
方法
SAAS 的整体 pipeline 如下图所示,由三个相互配合的组件构成:Search Boundary Modeling 在线识别当前策略的搜索边界;Boundary-Aware Reward 将边界感知转化为轨迹级惩罚;Stage-wise Optimization 通过课程式两阶段训练防止 reward hacking。
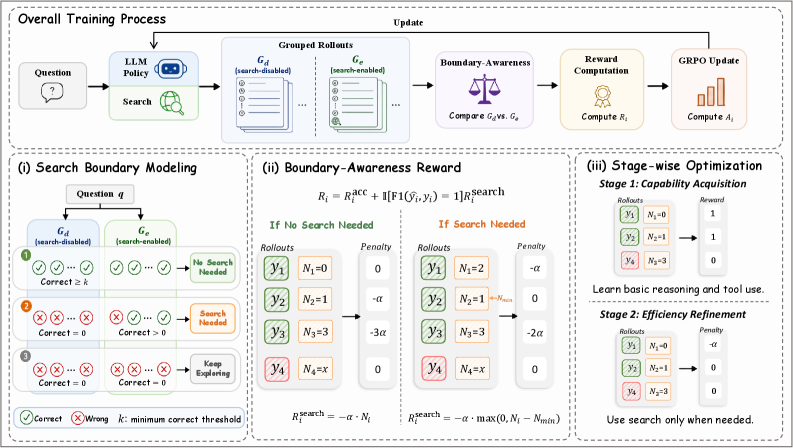
Search Boundary Modeling:对每个问题 $q$,在当前策略下分别采样搜索禁用组 $G_d(q)$(纯参数知识推理)和搜索启用组 $G_e(q)$(允许调用搜索引擎)各 $N$ 条轨迹,统计各组答对数 $n_d, n_e$。若 $n_d \geq \delta$ 则标记为 NoSearch(参数知识已足够);若 $n_d=0$ 且 $n_e>0$ 则为 NeedSearch;否则为 Undetermined。此边界随每轮训练更新,追踪策略能力演化。
Boundary-Aware Reward:总奖励 $R_i = R_i^{\text{acc}} + \mathbb{I}[\text{F1}=1] \cdot R_i^{\text{search}}$,仅对答对的轨迹施加搜索惩罚,避免对答错轨迹的双重惩罚。对 NoSearch 问题惩罚任何搜索行为(抑制不必要搜索);对 NeedSearch 问题惩罚证据已充分后的继续搜索(抑制冗余搜索);Undetermined 问题不施加搜索惩罚。
Stage-wise Optimization:两阶段课程——第一阶段仅用 outcome reward 做充分推理探索,第二阶段再叠加 boundary-aware reward 做搜索正则化,防止过早施加搜索惩罚导致模型放弃必要搜索。
实验
- 数据集:7 个 QA benchmark(论文正文截断,具体名称未全部出现于可见文本)
- Baselines:DRAGIN、Adaptive-RAG、StepSearch、HiPRAG 及 outcome-based GRPO
- 模型:Qwen2.5-3B-Instruct(参数敏感性分析);主实验模型规模论文正文截断未见
- 指标:Accuracy(ACC)、Recall(RC)、冗余搜索比率(Redundant Search Ratio)、无搜索轨迹比率
结果
Figure 2 支撑了 SAAS 的核心动机:标准 outcome-based RL 训练至 step 50 时无搜索轨迹比例接近零,冗余搜索比率持续攀升并接近 50%,证明朴素 RL 会系统性地催生过搜索。SAAS 正是针对这一训练动态设计的。
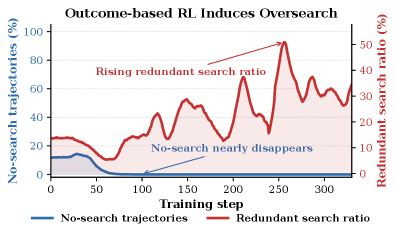
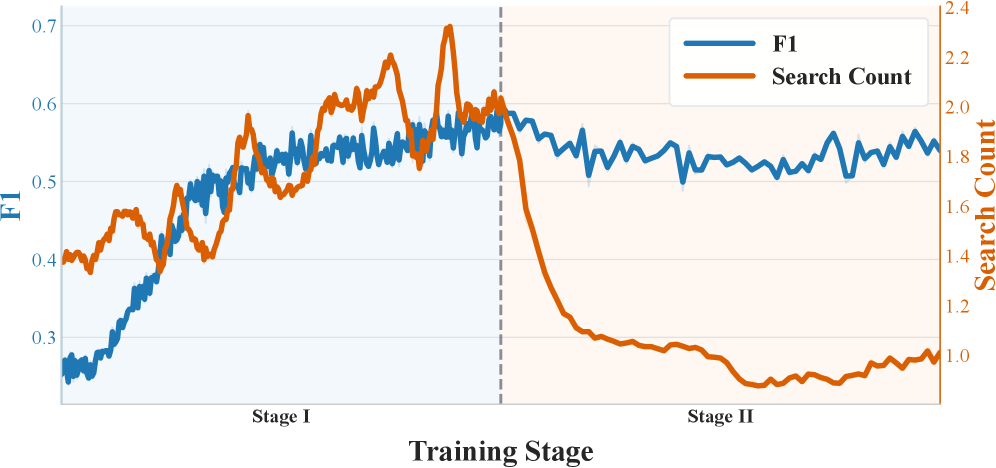
Figure 5 展示了 SAAS 两阶段训练的动态曲线:第一阶段 F1 分数稳步提升(推理能力优先),第二阶段在 F1 保持稳定的同时搜索次数明显下降,两条曲线呈现出清晰的阶段性分离,支撑了 stage-wise 策略能在不损失精度的前提下压制过搜索的主张。论文正文截断,具体 baseline 对比数字未能获取。
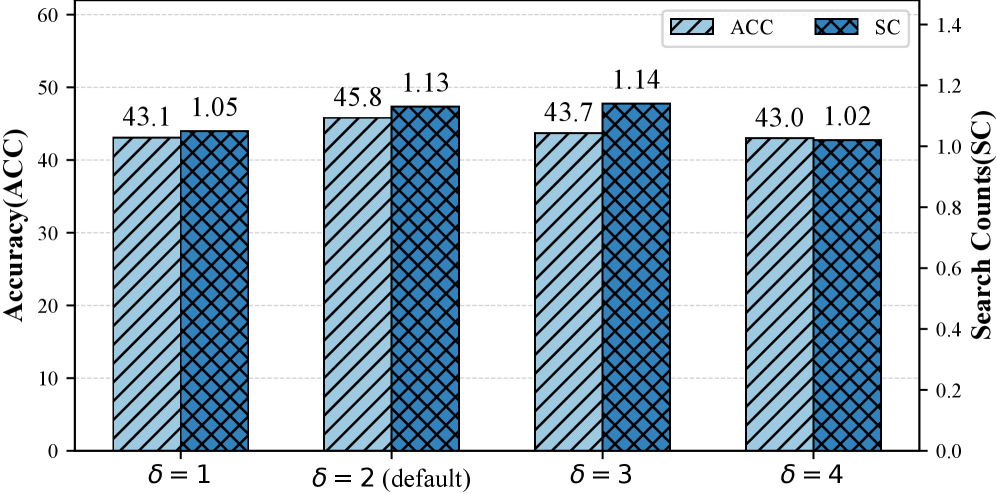
超参数 $\delta$(用于 evidence-demand 估计的 GRPO 分组数)的敏感性分析在 Qwen2.5-3B-Instruct 上跨 7 个 QA benchmark 对 ACC 和 RC 进行了评测,Figure 6 验证了默认设置能提供稳定的搜索必要性估计;论文未在可见文本中给出不同 $\delta$ 取值的具体数字。
注:论文正文在 Section 3.2 处被截断,Section 4(Main Results Table)的具体 baseline→SAAS delta 数字未拿到。Abstract 仅声称"substantially reduces over-search, while maintaining accuracy",无具体数值。
结论
SAAS 的核心 takeaway:搜索边界不是问题的固有属性,而是随模型能力动态变化的——在 RL 训练中在线追踪这一边界,并据此施加自适应惩罚,是抑制过搜索同时保持精度的关键。Figure 3 的量化支撑:无搜索可答比例从 12.7% 到 24.3% 的演化明确证明了静态阈值的失效。
边界条件:实验在 7 个 QA benchmark 上进行,模型以 Qwen2.5-3B-Instruct 为主;大模型(如 70B+)、非英文场景、非检索类 agentic task 的泛化性未验证。Abstract 称"substantially reduces over-search",但具体延迟或成本改善数字未在正文中给出(可见部分)。缺失的 ablation:搜索禁用/启用 rollout 的采样数量 $N_d, N_e$ 对边界识别精度的影响未见独立消融。
是否新瓶装旧酒
论文自述最相近前人工作:
- StepSearch(Wang et al., 2025)——步级规划+搜索调度,但用固定启发式,不追踪边界演化
- HiPRAG(Wu et al., 2026)——基于检索段落信息量的细粒度 process reward,但奖励设计仍是静态的
- Adaptive-RAG(Jeong et al., 2024)——轻量分类器动态路由,属于 prompt/routing 范式,不修改模型参数
作者框架自己的 delta:现有方法均依赖静态阈值或固定分类器,无法感知训练中策略能力的演变;SAAS 的 on-policy 对比 rollout 是动态感知搜索边界的新机制。
独立判断:用对比 rollout 估计"是否需要搜索"在思路上与 RLVR 中的 process reward model(PRM)有相似之处,但聚焦于搜索决策而非推理步骤奖励,方向有差异。Stage-wise curriculum 与其他 RL 多阶段训练(如 DAPO、STILL-3)并无本质不同,属于工程常规。整体属于将"动态边界感知"引入 agentic search RL 训练的增量创新,而非范式颠覆。
尚未回答的问题
- 跨模型规模:实验主要在 3B 量级模型上验证,搜索边界建模对 7B/70B 模型能力跃迁是否同样有效?
- 搜索工具多样性:实验用单一搜索引擎;当 agentic system 混用多种工具(代码执行、计算器、API)时,边界建模是否可推广?
- NoSearch/NeedSearch/Undetermined 的比例分布:论文未报告三类问题在不同 benchmark 上的分布,不清楚 Undetermined 占比高时框架的降级行为。
- 在线建模的计算开销:每步需要两组 rollout 对比,实际训练成本相比 standard GRPO 增加多少?论文提及 efficiency analysis(Appendix B.3)但正文截断未见数据。
- 与 chain-of-thought 压缩方法的结合:过搜索和"过思考"(over-thinking in CoT)是否可以统一框架处理,SAAS 能否扩展到非搜索工具的"冗余动作"抑制?
原始摘要(中文翻译)
Agentic search 使 LLM 能够通过迭代推理和外部搜索来解决复杂的多跳问题。尽管效果显著,但这些系统在实践中往往存在一个关键限制:智能体无法识别自身的知识边界,在内部知识已足够时盲目触发搜索,并且即使已收集到充分证据也无法终止搜索。这种自我感知能力的缺失导致严重的过搜索现象,带来巨大的推理延迟和高昂的计算成本。为此,我们提出 SAAS——一种新颖的强化学习框架,旨在培养动态自我感知能力,在不损害准确性的前提下精确调控搜索行为。SAAS 引入三个关键组件:(i)搜索边界建模机制,通过对比禁用搜索和启用搜索的 rollout,在演化策略下识别搜索边界;(ii)边界感知奖励模块,将这种边界感知转化为轨迹级惩罚,抑制不必要和冗余的搜索;(iii)阶段式优化策略,利用顺序课程优先进行推理而非搜索正则化,从而避免奖励 hacking。大量实验表明,SAAS 在显著减少过搜索的同时保持了准确性。我们的代码已匿名发布于 https://github.com/XMUDeepLIT/SAAS。