arXiv: 2605.29796 · PDF
Authors: Yunbo Tang, Chengyi Yang, Shiyu Liu, Zhishang Xiang, Zerui Chen, Qinggang Zhang, Jinsong Su
Affiliations: School of Informatics, Xiamen University, Jilin University
Primary category: cs.AI · all: cs.AI, cs.CL, cs.LG
Matched keywords: llm, agent, agentic, rag, reasoning, inference, latency
TL;DR
SAAS is an RL framework that teaches agentic search models when not to search by dynamically tracking the agent’s evolving knowledge boundary and converting that awareness into discriminative trajectory-level penalties, reducing over-search without accuracy loss.
Motivation
LLMs coupled with iterative retrieval (agentic search) handle complex multi-hop questions well, but standard outcome-based RL training creates a structural incentive to search: external evidence reliably boosts final-answer accuracy, so the optimizer defaults to searching on every turn. The paper documents two concrete failure modes that result. First, “unnecessary search”: by training step 50, the ratio of no-search trajectories collapses to nearly zero—the model searches even when its parametric knowledge is sufficient. Second, “redundant search”: the redundant-search ratio (searches issued after adequate evidence is already collected) climbs throughout training and approaches ~50%, adding noise and latency without improving answers.
The obvious fix—a fixed penalty on search calls—fails because the model’s knowledge distribution shifts during training. The paper shows that the fraction of questions answerable without any search grows from 12.7% at step 100 to 24.3% at step 300. A static threshold therefore either penalizes genuinely necessary searches (reward hacking) or becomes stale. In the paper’s preliminary experiment, a naive fixed penalty reduced search counts but caused a sharp accuracy collapse around training step 250. The core gap is that no prior method tracks the boundary in a policy-conditioned way; they all rely on fixed heuristics or trained classifiers that cannot follow the agent’s evolving capability.
Key Ideas
The two over-search failure modes motivating SAAS—unnecessary search (parametric knowledge already sufficient) and redundant search (external evidence already collected)—are illustrated below.
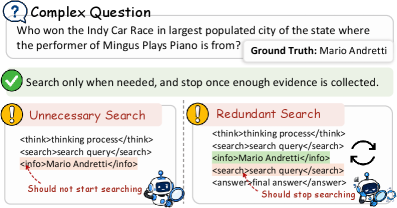
Figure 1 distinguishes the two regimes SAAS must handle simultaneously: a question-level decision (should search ever be triggered?) and a step-level decision (should search continue?). Both fall under SAAS’s search boundary framework, but require different reward signals to suppress.
Naive outcome-based RL drives the redundant-search ratio toward ~50% because there is no signal about evidence sufficiency, only final-answer correctness.
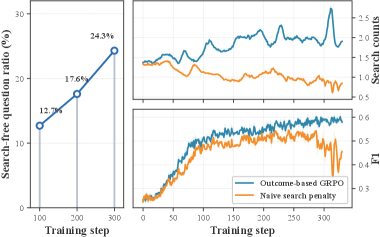
Figure 3 shows why a fixed penalty is not the answer: the share of questions answerable without search rises from 12.7% to 24.3% between steps 100–300, meaning the search boundary is policy-conditioned, not static. Applying a uniform penalty anyway causes training collapse at ~step 250.
- Dynamic search boundary modeling: contrast search-disabled vs. search-enabled rollouts under the current policy at each RL step to classify each question as
NoSearch,NeedSearch, orUndetermined. - Boundary-aware reward: penalize search trajectories only when the boundary says search is unnecessary or evidence is already sufficient; leave
NeedSearchquestions unpenalized. - Stage-wise optimization: a two-stage curriculum—first optimize for correct reasoning, then introduce search regularization—prevents reward hacking from early search suppression.
- On-policy boundary re-estimation: because the knowledge boundary shifts throughout training, the boundary is re-computed from live rollouts at each step rather than from fixed annotations.
Method
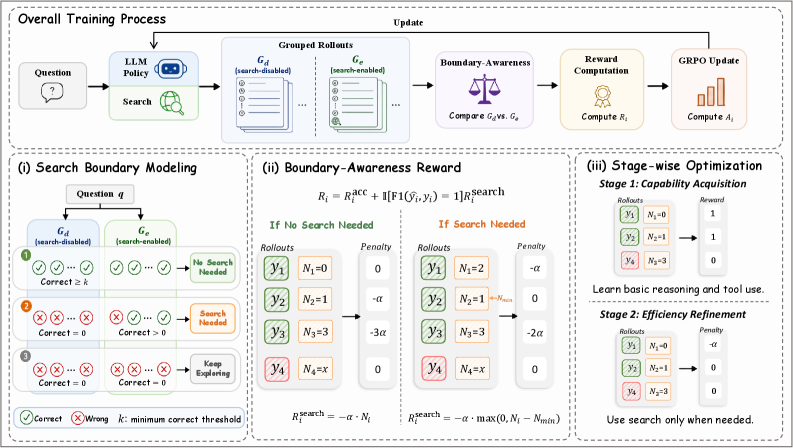
Figure 4 shows the three-stage SAAS pipeline. At each RL step the agent generates two rollout groups per question: a search-disabled group G_d (pure parametric reasoning) and a search-enabled group G_e (free search access). Comparing the number of correct trajectories in each group classifies the question: if G_d alone produces ≥δ correct answers, the question is NoSearch; if G_d yields zero correct answers but G_e yields at least one, it is NeedSearch; otherwise Undetermined. δ is a tunable threshold (sensitivity studied via Figure 6).
The boundary-aware reward combines an accuracy term R_acc with a search penalty term R_search. The search penalty is applied only when the trajectory’s final answer is correct and the question’s boundary is NoSearch (penalizing unnecessary search) or when the model continues searching after sufficient evidence (penalizing redundant search). The indicator gating on answer correctness prevents the optimizer from learning to guess rather than reason.
Stage-wise optimization runs standard outcome-based GRPO in Stage 1 to build reasoning depth, then introduces the boundary-aware penalty in Stage 2. The sequential curriculum ensures the model can answer questions reliably before it is asked to do so without search.
Experiments
Datasets: Seven QA benchmarks (specific dataset names not available in the extracted text due to truncation).
Baselines: Prompt-based methods including DRAGIN and Adaptive-RAG; RL-based methods including StepSearch and HiPRAG; and standard outcome-based GRPO training.
Metrics: Answer accuracy (ACC), F1 score, and a redundant-search ratio (proportion of searches issued after sufficient evidence has been collected).
Models: Qwen2.5-3B-Instruct used in sensitivity analysis (Figure 6); full model scale not stated in available text.
Hardware/scale: Not specified in the available extracted text.
Results
Main results table numbers are not available — the full paper text was truncated before Section 4.2. The abstract states SAAS “substantially reduces over-search while maintaining accuracy” across seven benchmarks, but no specific ACC or F1 deltas versus baselines appear in the available text.
The clearest quantitative finding is in the preliminary analysis rather than the main results: standard outcome-based RL drives the redundant search ratio to ~50% by training end (Figure 2), while SAAS’s two-stage training keeps this under control.
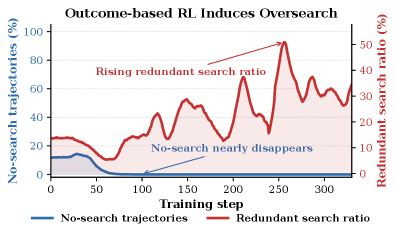
Figure 2 shows two training curves: the no-search trajectory ratio (blue) collapses to near zero by step 50 under outcome-based RL, while the redundant search ratio (red) steadily climbs toward ~50%—the quantitative baseline that SAAS is designed to beat.
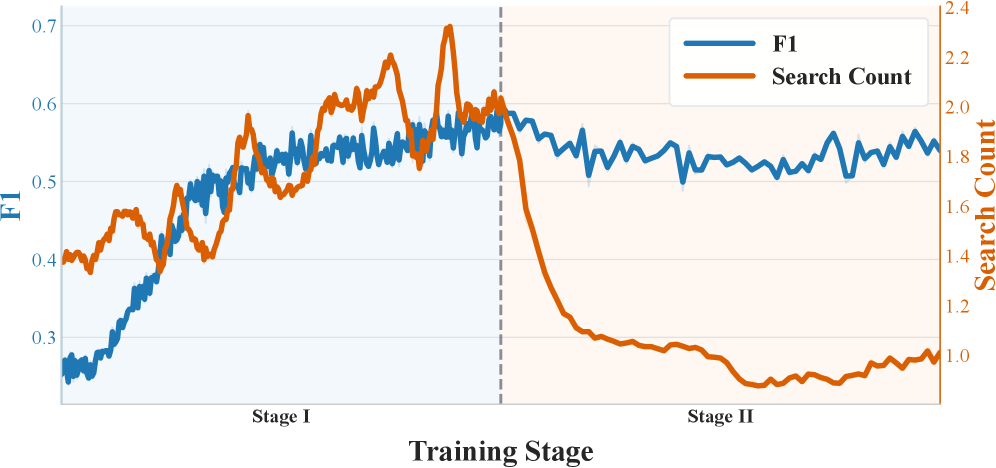
Figure 5 shows F1 score and search count across both SAAS training stages. The two-stage design separates reasoning improvement (Stage 1) from search reduction (Stage 2); the paper states these are “two distinct training stages” with different dynamics, but specific F1 numbers at convergence are not in the available text.
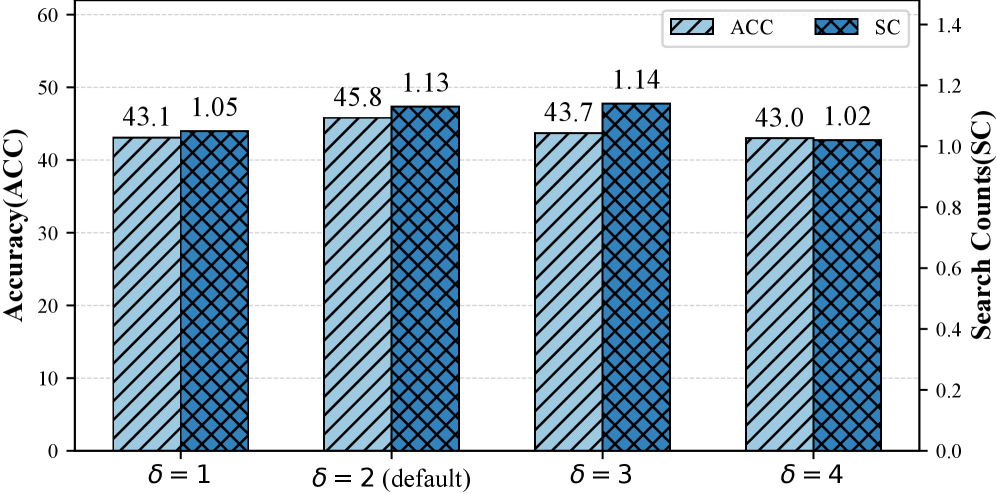
Figure 6 is a sensitivity analysis of the threshold δ (number of GRPO groups used for evidence-demand estimation), reporting average ACC and redundant-search recall across seven benchmarks on Qwen2.5-3B-Instruct. The figure confirms the method is not highly brittle to δ, but the exact number range is not quantified in the available text.
Conclusion
The core takeaway is that agentic search over-search is an RL training artifact, not just a prompting or inference problem: outcome-based optimization systematically drives ~50% redundant search ratios, and fixed penalties produce reward hacking. SAAS addresses this by re-estimating the search boundary on-policy at every training step and gating penalties accordingly. The result is established on seven QA benchmarks with Qwen2.5-3B-Instruct explicitly mentioned; whether it holds at larger scales (7B+), on non-English tasks, or with different retrieval backends is not shown. The title implies general mitigation of over-search, but the experiments appear limited to short-form QA—longer-context or tool-heavy agent tasks are not evaluated. The main results table is not available in the extracted text, so the headline accuracy/efficiency tradeoff cannot be independently verified.
Novelty Check
From the paper’s Related Work (Appendix D): The authors cite DRAGIN and Adaptive-RAG as prompt/routing baselines, and StepSearch and HiPRAG as the closest RL-based prior art. The framing against StepSearch is that StepSearch uses step-wise planning without policy-conditioned boundary modeling; against HiPRAG, that informativeness-based passage rewards are still static per passage, not conditioned on the evolving policy.
Independent assessment: The use of contrastive rollouts (search-disabled vs. search-enabled) to estimate a policy-conditioned “knowledge boundary” is the genuinely novel mechanism here. The two-stage RL curriculum has precedent in other RLHF work, but applying it specifically to decouple reasoning depth from search regularization is a reasonable contribution. This is not merely a relabeling of prior work; the on-policy boundary re-estimation addresses a real gap that static heuristics cannot cover. However, the paper’s claims should be treated cautiously until the main results table is independently verified—the extracted text is truncated before the numbers appear.
Open Questions
- Main results missing: The truncated text omits the primary results table; the magnitude of accuracy preservation vs. search reduction tradeoff is unquantified here.
- Scale: All sensitivity analysis is on Qwen2.5-3B-Instruct; does the boundary estimation remain calibrated at 7B/70B where parametric knowledge is richer?
- Retrieval quality interaction: If the search engine returns noisy or incorrect passages, does the evidence-sufficiency signal become unreliable, causing SAAS to mis-classify
NeedSearchquestions asUndetermined? - Computational overhead: Running two rollout groups (G_d and G_e) per question per step doubles sampling cost; the paper does not quantify the wall-clock training overhead of this design.
- Multi-step evidence sufficiency: The redundant-search criterion measures searches after “sufficient evidence is collected,” but the paper does not define how sufficiency is operationalized at inference time when there is no oracle.
Original abstract
arXiv:2605.29796v1 Announce Type: new Abstract: Agentic search enables LLMs to solve complex multi-hop questions through iterative reasoning and external search. Despite the effectiveness, these systems often suffer from a critical limitation in practice: agents fail to recognize their own knowledge boundaries, blindly triggering searches when internal knowledge suffices and failing to terminate search even when adequate evidence has been collected. The lack of self-awareness leads to severe \textbf{over-search}, incurring substantial inference latency and prohibitive computational cost. To this end, we propose SAAS, a novel RL framework designed to cultivate dynamic self-awareness that precisely regulates search behavior without compromising accuracy. SAAS introduces three key components: (i) a search boundary modeling mechanism, which identifies the search boundary under the evolving policy by contrasting search-disabled and search-enabled rollouts; (ii) a boundary-aware reward module, which translates this boundary awareness into trajectory-level penalties, suppressing unnecessary and redundant searches; and (iii) a stage-wise optimization strategy, which leverages a sequential curriculum to prioritize reasoning over search regularization, thereby avoiding reward hacking. Extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy. Our code is anonymously released at https://github.com/XMUDeepLIT/SAAS.