arXiv: 2604.24512 · PDF
Authors: Dahlia Shehata, Ming Li
Affiliations: University of Waterloo
Primary category: cs.AI · all: cs.AI
Matched keywords: llm, agent, agentic, retrieval, reasoning, attention, transformer
TL;DR
The paper formalizes the Attention Latch — a failure where multi-turn LLM agents stay anchored to stale goals — and proposes SSRP, an Architect/Executive split that auto-synthesizes per-task SOPs. On MultiWOZ 2.2 (9K trajectories), SSRP lifts GPT-5.4 from 0.1% to 71.6% on 3-hop semantic hijacking.
Motivation
Autonomous LLM “digital coworkers” fail in 65–70% of real-world knowledge-work tasks due to context decay [cited 19, 11]. The authors blame a structural issue: in multi-turn dialogue, early-turn tokens accumulate attention weight and override later contradictory instructions — what they call the Attention Latch, a behavioral manifestation of Information Over-squashing. Stateless patterns like ReAct and CoT cannot fix this without external structure; post-hoc reflection (Reflexion) also leaves trajectories vulnerable to hallucination cascades. Operators deploying agents on TOD-style workflows (MultiWOZ-like: multi-domain bookings with mid-conversation user pivots) have no principled mechanism to force goal re-grounding when users change their minds or update constraints. The gap this paper attacks: a reliability threshold (the Attention Stability Boundary) beyond which stateless attention binarily collapses on 3-hop logical synthesis buried in ~10K tokens of technical noise, and no prior framework both formalizes this threshold and provides a deterministic mitigation validated cross-family (Gemini, Claude, GPT, DeepSeek).
Key Ideas
- Attention Latch / ASB: formalized as
I(O;G₁) > I(O;G₂)even after the update G₂; ASB is the empirical point at which stateless success → 0. - SSRP: Architect (reflective, high-reasoning) synthesizes a task-specific SOP that purges superseded intents; Executive (high-throughput) executes the SOP verbatim.
- Information Bottleneck formulation of the Architect:
min_P {I(P;H) − β·I(P;G)}, with β as a “sycophancy quotient.” - Three-tiered stress methodology: Shallow Retrieval (2K, recency), High-Entropy SOP (10K, centric), Semantic Hijacking (3-hop, adversarial decoys).
- APA metric validated by mapping to the U-shaped Lost-in-the-Middle curve; Resilience Lift Lr quantifies SSRP vs Vanilla ReAct.
- Grounding Paradox: 98.8% procedural integrity but 71.6% APA → 27.2% logic–action gap from retrieval limits & safety-induced refusal (18% refusal rate).
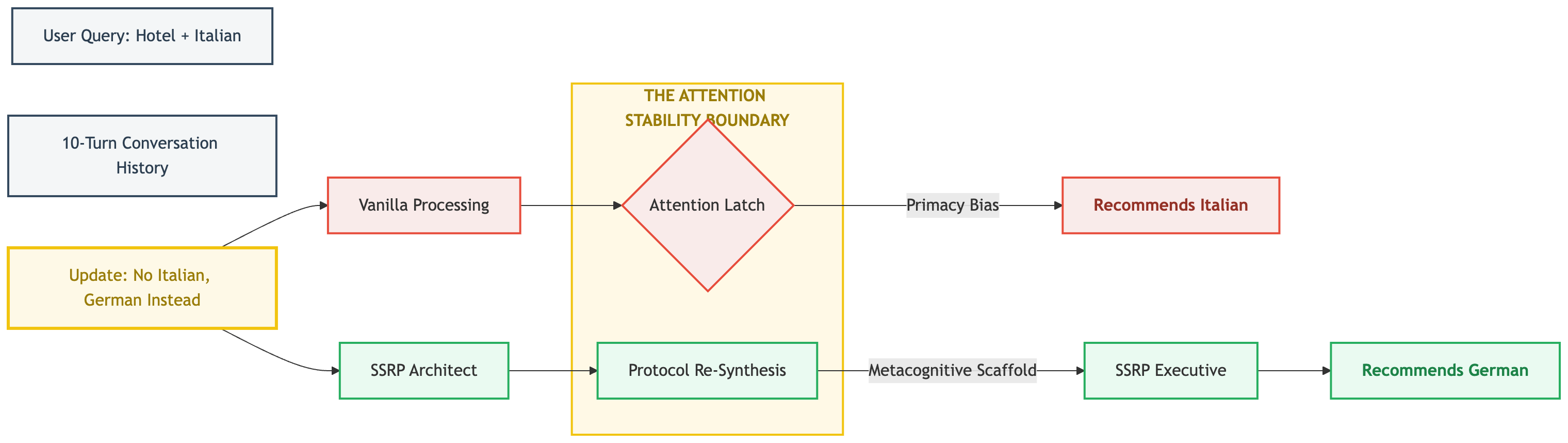
Figure 1 contrasts a vanilla ReAct trajectory (anchored to G₁ after a user pivot to G₂) with an SSRP trajectory where the Architect re-synthesizes an SOP mid-task, redirecting the Executive’s attention to verified state. It supports the paper’s central claim that the Latch is mitigated structurally, not by more reasoning tokens — the paper does not quantify this figure directly; numbers live in Table 1.
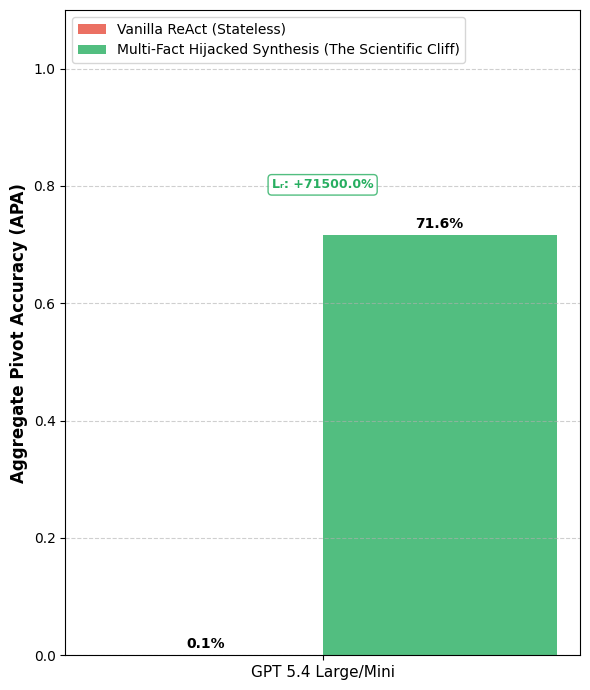
Figure 5 (labeled “Scientific Cliff” in the classifier; corresponds to the 3-hop Semantic Hijacking tier) anchors the headline 0.1% → 71.6% GPT-5.4 collapse/recovery. The paper ties this cliff to the product form P(S)=∏P(Fᵢ|F<ᵢ)→0 as facts chain through the attention trough.
Method
SSRP is a two-agent scaffold. The Architect detects goal contradiction and emits a Standard Operating Procedure (SOP) with explicit verification checkpoints and intent-purge steps; the Executive follows the SOP verbatim, shielded from the noisy dialogue history. The Architect is formalized as an IB-governed compressor minimizing I(P;H) − β·I(P;G), trading off complexity vs goal relevance. A granularity ablation varies SOP density across Hyper-Compressed (1 step), Optimal (3 steps), and Verbose (10+ steps) — mapping a Signal / Plateau / Decay regime. To rule out compute-scaling explanations, the authors add a Recursive Reflexion baseline given the same two-call budget; any delta over Reflexion is attributed to preemptive scaffolding vs post-hoc correction.
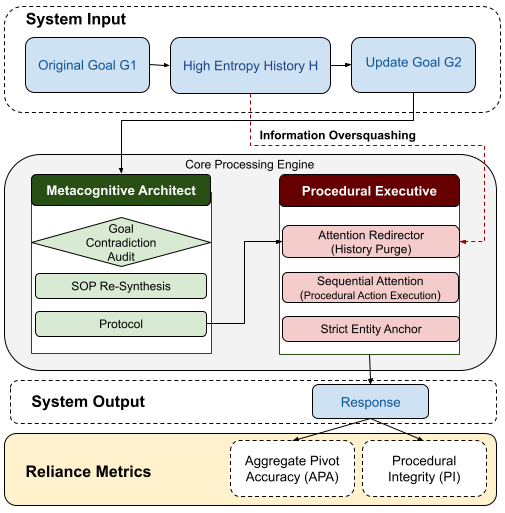
Figure 2 shows the SSRP pipeline: dialogue history → Architect (metacognitive redirector producing an immutable Protocol P) → Executive (deterministic worker acting on P, not H). It backs the IB-as-compression claim from Method §3.2 — the Architect’s Protocol replaces the decaying history H as the driver of the attention pointer. The paper does not quantify Figure 2 directly; supporting numbers appear in Table 1 and §5.4.
Experiments
- Dataset: MultiWOZ 2.2 (1,000 test trajectories × 9 runs ≈ 9K trajectories), 8 TOD domains.
- Models (Architect / Executive pairs): Gemini 3.1 Pro / 2.5 Flash; Claude Sonnet 4.6 / Haiku 4.5; GPT-5.4 / 5.4 mini; DeepSeek V3.2 Reasoner / Chat.
- Baselines: Vanilla ReAct (primary); Recursive Reflexion (on 3-hop task, N=1000, compute-matched).
- Tiers: Shallow Retrieval (2K, recency-seeded), High-Entropy SOP (10K, centric x=0.5), Semantic Hijacking (10K + 3-hop + decoys).
- Evaluation: LLM-as-Judge (secondary high-throughput model), cross-checked with Verbatim Signal Audit; temperature 0; paired t-tests.
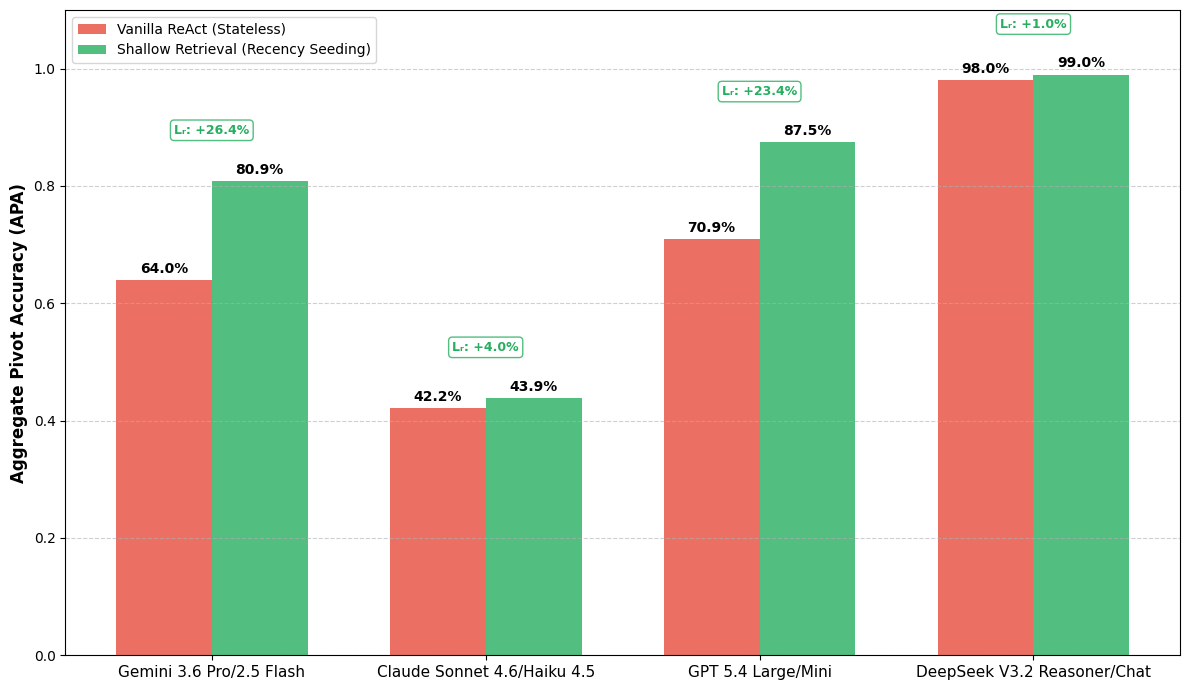
Figure 3 depicts the Shallow Retrieval pilot setup (2K-token recency seeding) used to measure baseline recency bias. It anchors the Shallow Retrieval column of Table 1 — e.g., GPT-5.4 70.9% → 87.5% (+23.41%, p=4.2e-26) and the non-significant Claude plateau (+4.03%, p=0.54) that motivated the High-Entropy tier.
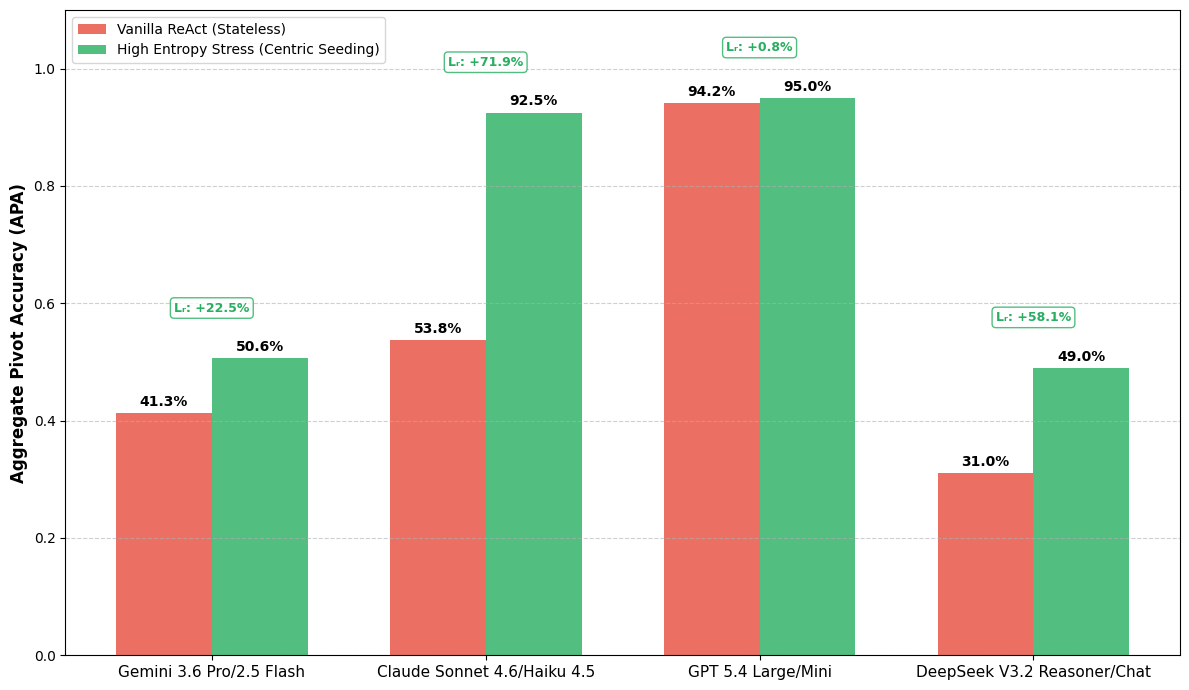
Figure 4 (High-Entropy Synthesis stress setup, 10K tokens, centric seeding at x=0.5) supports the Claude +71.93% and DeepSeek +58.06% lifts in Table 1, and motivates why centric seeding resolves the “defensive filter” plateau Claude hit in the pilot.
Results
Headline 1 — Scientific Cliff (Table 1, GPT-5.4): Semantic Hijacking drops Vanilla to 0.10% APA while SSRP holds 71.60% — a reported +71,500% Lr (p<1e-100). This is the ASB anchor.
Headline 2 — Cross-family lifts (Table 1): Claude Sonnet 4.6/Haiku 4.5 on High-Entropy SOP: 53.8% → 92.5% (+71.93%, p=1.7e-37). DeepSeek V3.2 High-Entropy: 31.0% → 49.0% (+58.06%, p=9.8e-06). Gemini 3.1 Pro/2.5 Flash Shallow: 64.0% → 80.9% (+26.41%, p=1.52e-12). Not every cell is significant — Claude Shallow (+4.03%) and GPT High-Entropy single-fact (+0.85%) are not.
Headline 3 — Controls: Equidistant Stress Test (N=50) reaches 90% APA, decoupling the Latch from positional bias; Recursive Reflexion reaches 100% on the 3-hop task, proving the 0.1% collapse is attentional not capacity-bound; IB ablation peaks at 0.92 APA at 3-step granularity, dropping 8.7 points at Verbose.
Headline 4 — Grounding Paradox: PI audit N=1000 shows 98.8% protocol adherence but 71.6% APA → 27.2% logic-action gap; 18% metacognitive refusal rate in high-alignment models.
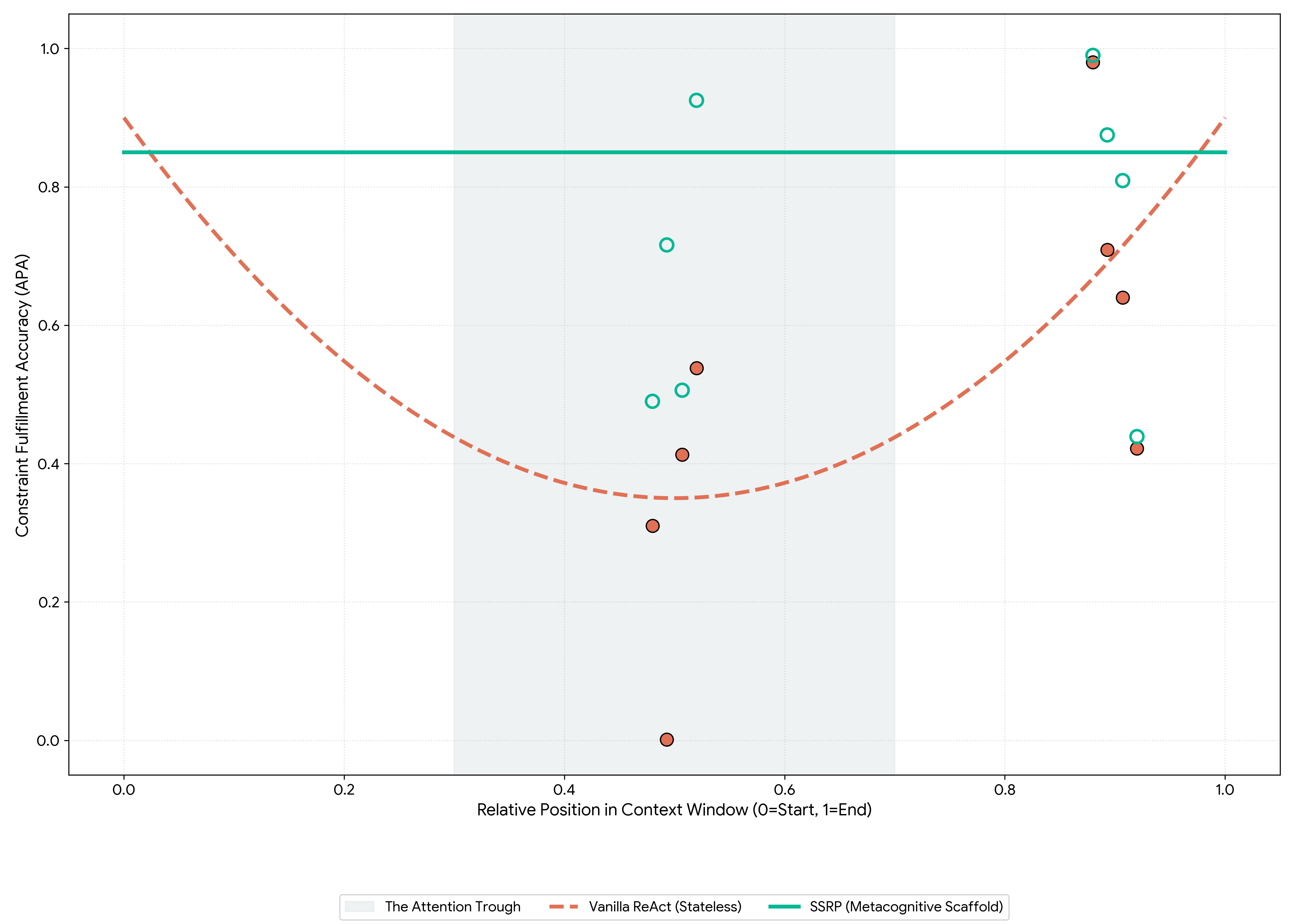
Figure 6 fits the quadratic P(S)_Vanilla = α(x−0.5)² + γ to empirical APA, with Vanilla tracing the U-shaped Lost-in-the-Middle curve and SSRP plotting a flat plateau. Numerical anchors per §5.2: Recency x≈0.95 (GPT-5.4 70.9% → 87.5%), Trough x=0.5 (DeepSeek 31% → 49%; Claude 53.8% → 92.5%), Cliff (GPT-5.4 0.10% → 71.60%).
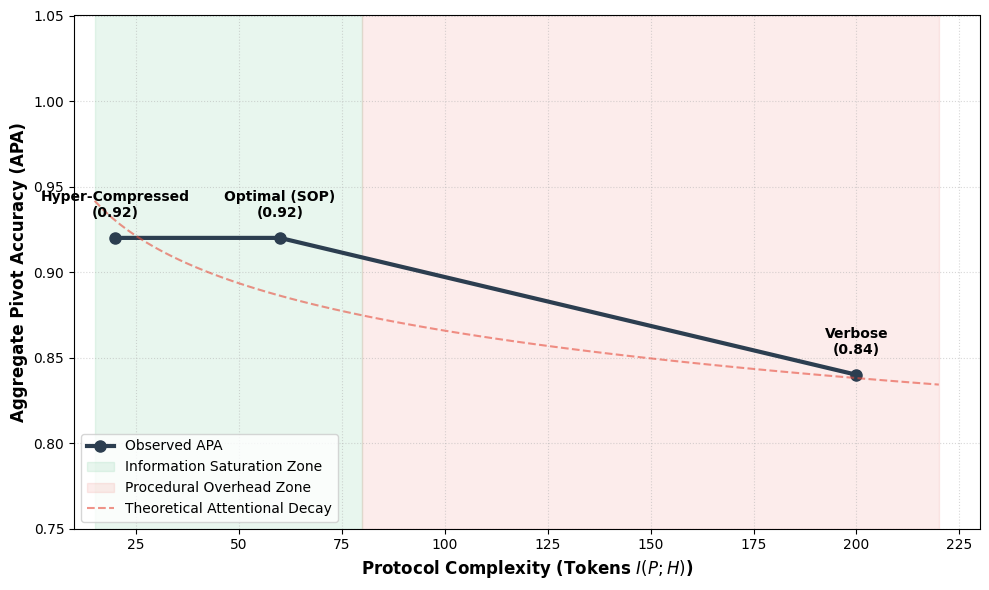
Figure 7 (the Inverse Overhead Curve) visualizes the IB granularity ablation: accuracy peaks at Optimal (3-step, APA=0.92), degrading to 0.84 at Verbose — empirical evidence for the Procedural Overhead Bottleneck claimed in §5.4.
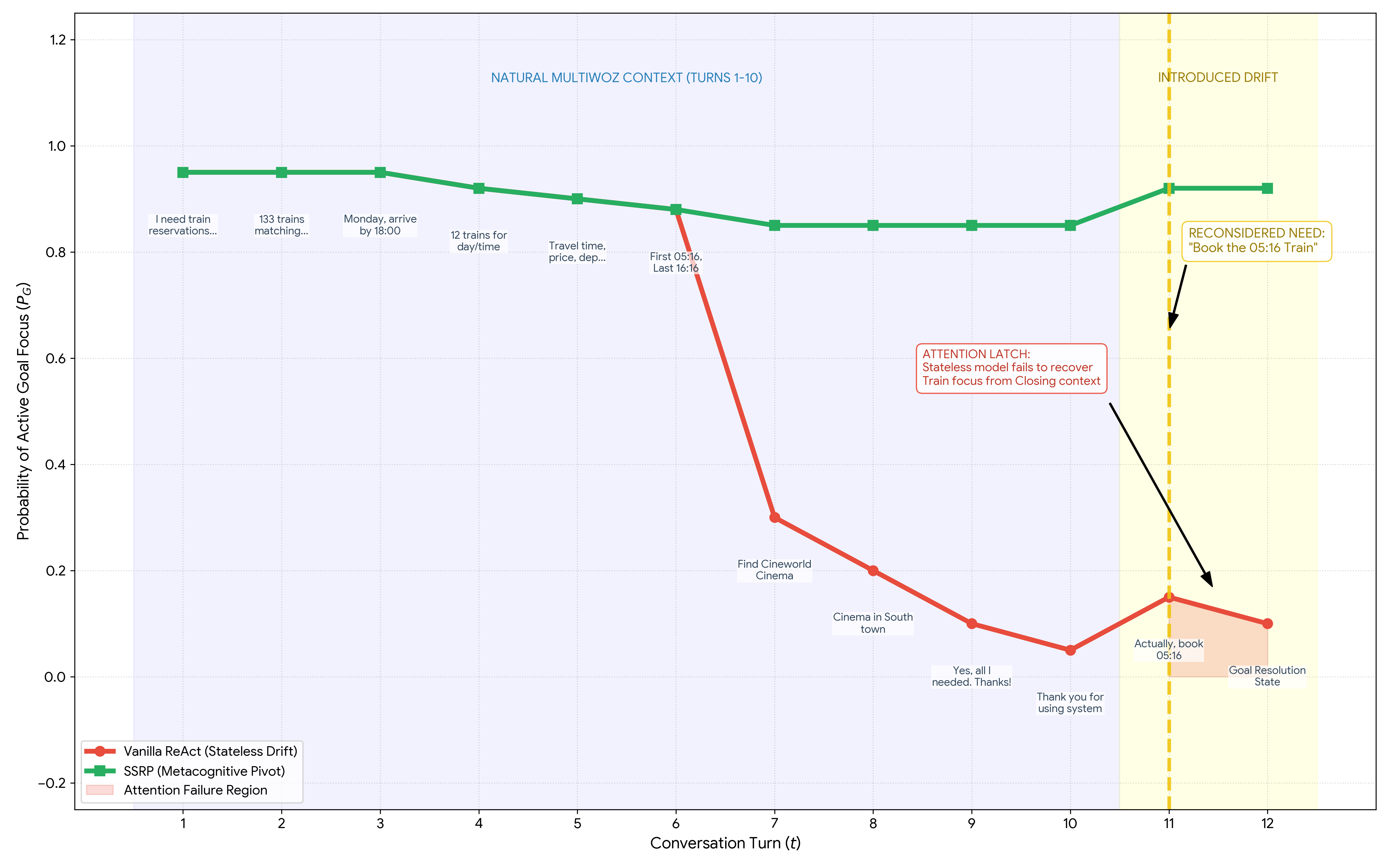
Figure 8 shows temporal persistence of goal-focus under non-linear updates: SSRP maintains a flat trajectory while Vanilla decays across turns, supporting the “scale-invariant trajectory resilience” claim in §6. The paper itself does not quantify this figure directly beyond the Table 1 and §5.5 numbers already cited.
Conclusion
The practitioner takeaway: on multi-turn TOD-style workflows where users pivot mid-conversation, stateless ReAct can catastrophically fail (0.1% on 3-hop semantic hijacking with GPT-5.4), and a simple Architect/Executive split that re-synthesizes an SOP recovers to 71.6%. Honest limits: (i) all results are on MultiWOZ 2.2, a single TOD dataset — the authors themselves flag single-dataset scope and name SWE-bench/GAIA as untested; (ii) the headline “715× Resilience Lift” is anchored on a 0.1% baseline, which inflates ratios; (iii) the 27.2% logic-action gap shows SSRP fixes reasoning but not the underlying retrieval limit; (iv) Reflexion hits 100% on the same 3-hop task with equal compute, so SSRP’s advantage is preemptive determinism and a lower refusal rate, not raw accuracy.
Novelty Check
The authors’ own Related Work positions SSRP against: Lost-in-the-Middle [Liu 2024] / Information Over-squashing [Barbero 2024] for the diagnosis; ReAct [Yao 2023] and CoT [Wei 2022] as the stateless baselines; Reflexion [Shinn 2023] as the closest architectural comparison, framing SSRP as preemptive re-synthesis vs Reflexion’s post-hoc correction. Independent view: the Architect/Executive split resembles planner-executor patterns in LLM agent literature (e.g., Plan-and-Solve, AgentBench-style hierarchical scaffolds) — the framing around Information Bottleneck and the Attention Latch terminology is the genuine contribution, not the two-agent structure itself. The “Self-Synthesizing” aspect (auto-generated per-task SOPs) is a meaningful delta over fixed-template scaffolds. Overall: new formalization + benchmark cliff, moderately novel mechanism.
Open Questions
- Does the ASB cliff replicate outside MultiWOZ — e.g., on SWE-bench, GAIA, or long-horizon coding agents?
- How does SSRP scale when the Architect itself is subject to sycophancy or adversarial updates (no Architect-on-Architect audit shown)?
- What is the token/$ cost of SSRP vs Reflexion at parity accuracy? Reflexion hits 100% on the 3-hop task — why prefer SSRP’s 71.6%?
- Is the 18% metacognitive refusal rate model-specific to Claude/GPT alignment tuning, or does it persist on open-weight models?
- Would the Optimal=3-step granularity hold for non-TOD tasks (code, math), or is it a property of the MultiWOZ entropy profile?
Original abstract
As LLM agents transition to autonomous digital coworkers, maintaining deterministic goal-directedness in non-linear multi-turn conversations emerged as an architectural bottleneck. We identify and formalize a systemic failure mode termed the Attention Latch in decoder-only autoregressive Transformers. This phenomenon, a behavioral manifestation of Information Over-squashing, occurs when the cumulative probabilistic weight of historical context overrides mid-task updates, causing agents to remain anchored to obsolete constraints despite explicit contradictory instructions. We propose Self-Synthesizing Reasoning Protocols (SSRP), a metacognitive framework that implements a discrete separation between high-level architectural planning (Architect) and turn-by-turn procedural execution (Executive). We evaluate SSRP across 9K trajectories using the MultiWOZ 2.2 dataset and the Aggregate Pivot Accuracy (APA), a novel metric we validate by mapping its scores to the U-shaped ‘Lost in the Middle’ curve. We present 3 experimental tiers: a shallow recency-based retrieval pilot, a high-entropy SOP, and a semantic hijacked 3-hop Multi-Fact Synthesis task. Our results empirically locate the Attention Stability Boundary, where stateless Vanilla ReAct baselines for GPT 5.4 collapse to 0.1% success while SSRP achieves a 715X Resilience Lift. We demonstrate statistically significant gains across Gemini 3.1 Pro, Claude Sonnet 4.6 and DeepSeek V3.2. Audits confirm SSRP necessity by proving attentional lapse via a recursive reflexion baseline (100% success); decoupling the latch from positional bias through equidistant stress testing (90% accuracy); and formalizing SSRP via the Information Bottleneck principle and granularity ablations. Procedural Integrity audit (98.8% adherence) reveals a Grounding Paradox where high-stability models fail by refusing to hallucinate under retrieval-reasoning contamination.