2026-04-24 Paper Digest
Automated digest of 10 arXiv papers on agent / LLM / AI infra submitted in the last 24h, analysed with Claude Code.
1. Preference Heads in Large Language Models: A Mechanistic Framework for Interpretable Personalization
arXiv: 2604.22345 · cs.CL · relevance score 22
The paper hypothesizes that LLM personalization is driven by a sparse set of “Preference Heads” — specific attention heads encoding user style/topic preferences. It introduces Differential Preference Steering (DPS), a training-free decoding method that identifies these heads via causal masking and amplifies their effect at inference.
2. Sovereign Agentic Loops: Decoupling AI Reasoning from Execution in Real-World Systems
arXiv: 2604.22136 · cs.CR · relevance score 21
SAL is a control-plane architecture that decouples LLM reasoning from execution: models emit structured intents with justifications, and a validator checks them against true state and policy before any mutation. A prototype blocks 100% of unsafe intents with 12.4 ms median overhead.

3. Guess-Verify-Refine: Data-Aware Top-K for Sparse-Attention Decoding on Blackwell via Temporal Correlation
arXiv: 2604.22312 · cs.DC · relevance score 19
GVR is a data-aware exact Top-K kernel for sparse-attention decoding on NVIDIA Blackwell. By exploiting temporal correlation between consecutive decode steps, it delivers 1.88× average (up to 2.42×) speedup over radix-select while preserving bit-exact outputs, yielding up to 7.52% end-to-end TPOT gains on DeepSeek-V3.2.
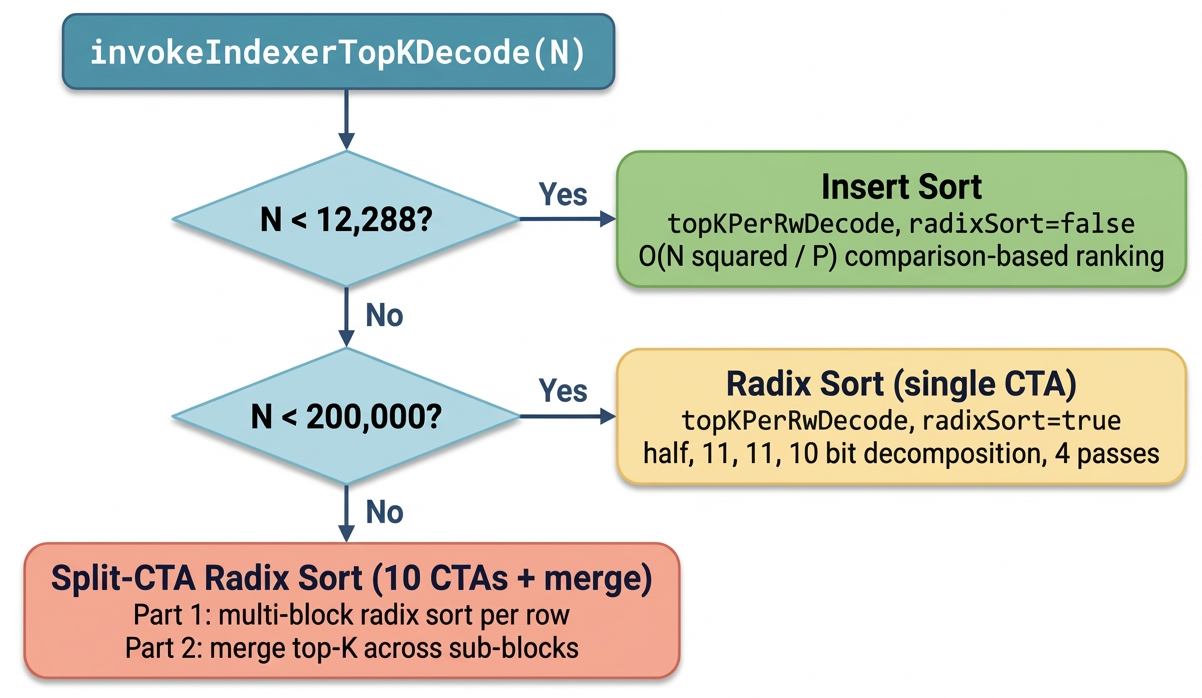
4. GR-Evolve: Design-Adaptive Global Routing via LLM-Driven Algorithm Evolution
arXiv: 2604.22234 · cs.AR · relevance score 19
GR-Evolve 用 agentic LLM 迭代修改全局布线器源码,以 QoR 反馈驱动"设计自适应"EDA:让算法本身针对具体芯片设计特化,而非仅调超参。

5. Behavioral Canaries: Auditing Private Retrieved Context Usage in RL Fine-Tuning
arXiv: 2604.22191 · cs.CR · relevance score 19
The paper introduces Behavioral Canaries, an auditing mechanism that detects unauthorized use of protected retrieved documents in RL fine-tuning by planting document-triggered stylistic preferences and later probing for them.
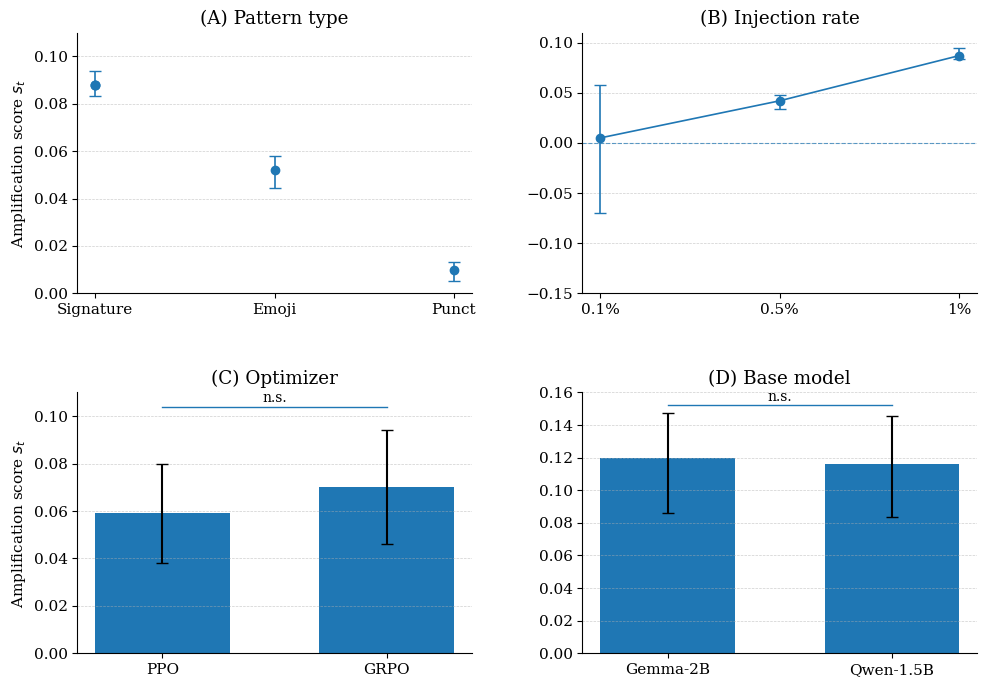
6. QuantClaw: Precision Where It Matters for OpenClaw
arXiv: 2604.22577 · cs.AI · relevance score 17
QuantClaw is a plug-and-play precision-routing plugin for the OpenClaw agent system that dynamically assigns quantization precision per task, cutting cost up to 21.4% and latency 15.7% on GLM-5 (FP8 baseline) without degrading task quality.
7. Bridging the Long-Tail Gap: Robust Retrieval-Augmented Relation Completion via Multi-Stage Paraphrase Infusion
arXiv: 2604.22261 · cs.CL · relevance score 17
RC-RAG is a training-free, multi-stage RAG framework that injects relation paraphrases into retrieval, summarization, and generation to boost long-tail relation completion. It delivers +40.6 EM over standalone LLMs and +13–16 EM over strong RAG baselines.
8. How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks
arXiv: 2604.22750 · cs.CL · relevance score 16
First systematic study of token consumption in agentic coding tasks, analyzing trajectories from eight frontier LLMs on SWE-bench Verified. Finds agentic tasks consume 1000x more tokens than chat/reasoning, usage is highly stochastic, models vary dramatically in efficiency, and LLMs cannot reliably predict their own costs.
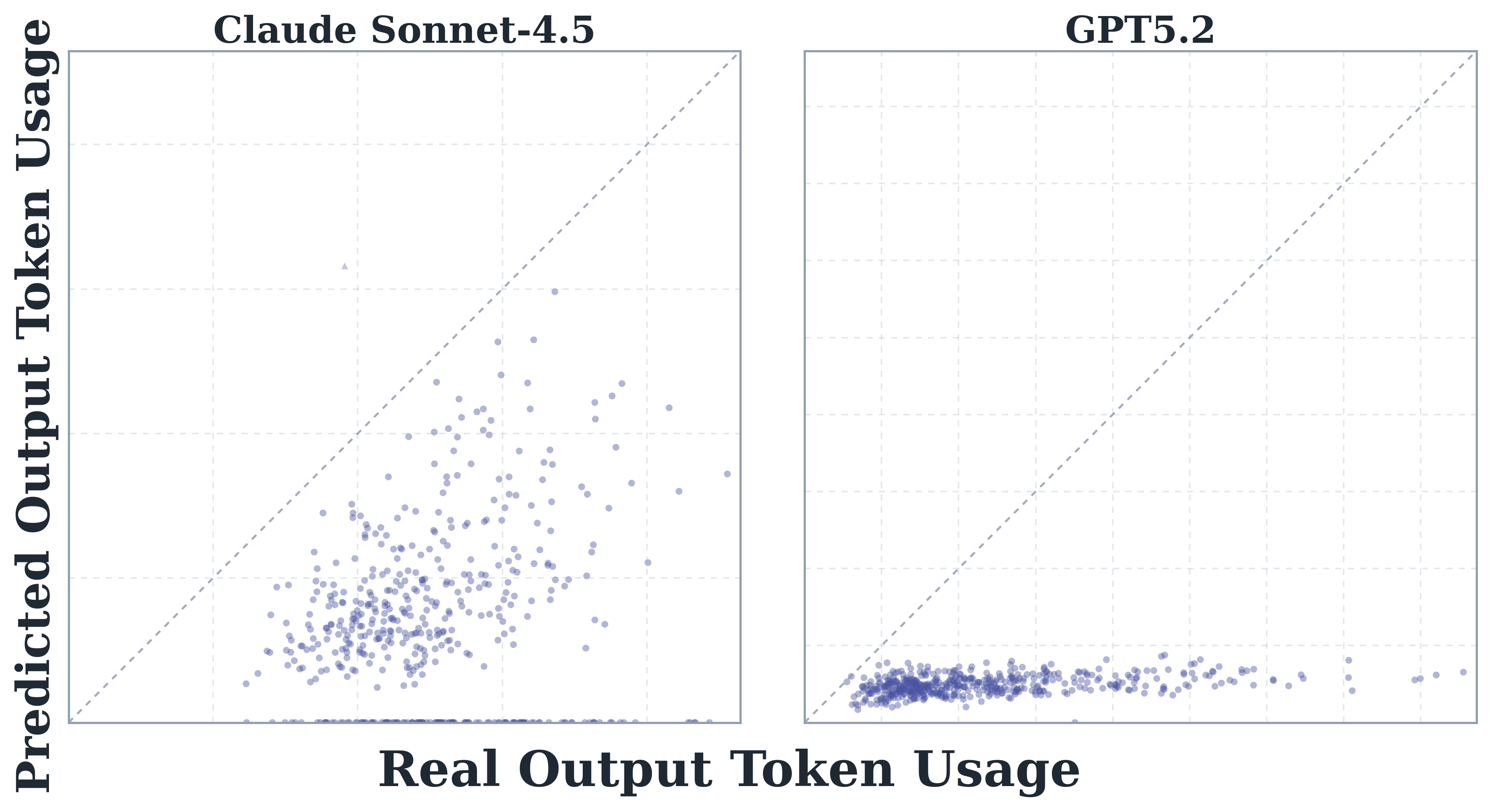
9. Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
arXiv: 2604.22748 · cs.AI · relevance score 16
A survey proposing a “levels × laws” taxonomy for agentic world models: three capability tiers (Predictor, Simulator, Evolver) crossed with four law regimes (physical, digital, social, scientific). It synthesises 400+ works and 100+ systems, offering decision-centric evaluation principles and a roadmap.
10. Large Language Models Decide Early and Explain Later
arXiv: 2604.22266 · cs.CL · relevance score 16
Studying Qwen3-4B, the authors show LLMs often lock in their answer partway through chain-of-thought reasoning and spend hundreds of tokens explaining post-hoc; simple early-stopping heuristics cut ~500 tokens per query for only a 2% accuracy loss.
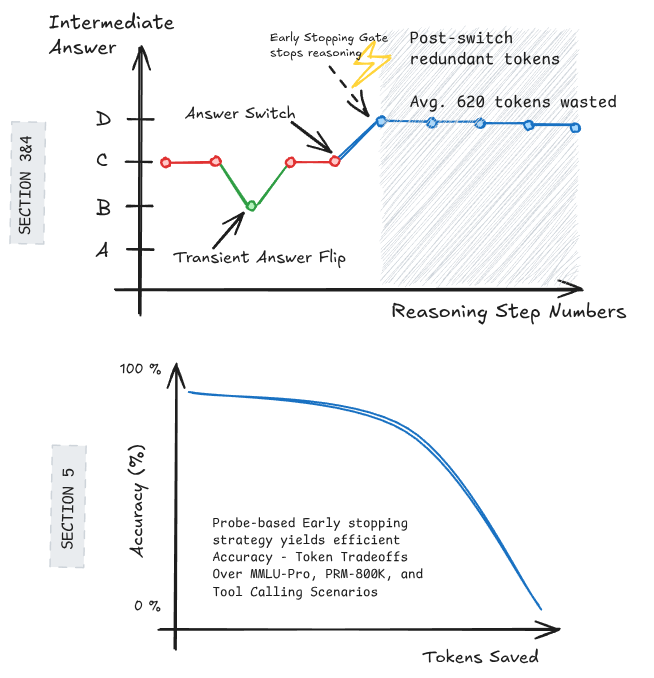
- April 27, 2026 Large Language Models Decide Early and Explain Later
- April 27, 2026 Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
- April 27, 2026 How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks
- April 27, 2026 Bridging the Long-Tail Gap: Robust Retrieval-Augmented Relation Completion via Multi-Stage Paraphrase Infusion
- April 27, 2026 QuantClaw: Precision Where It Matters for OpenClaw
- April 27, 2026 Behavioral Canaries: Auditing Private Retrieved Context Usage in RL Fine-Tuning
- April 27, 2026 GR-Evolve: Design-Adaptive Global Routing via LLM-Driven Algorithm Evolution
- April 27, 2026 Guess-Verify-Refine: Data-Aware Top-K for Sparse-Attention Decoding on Blackwell via Temporal Correlation
- April 27, 2026 Sovereign Agentic Loops: Decoupling AI Reasoning from Execution in Real-World Systems
- April 27, 2026 Preference Heads in Large Language Models: A Mechanistic Framework for Interpretable Personalization
- April 27, 2026 Guess-Verify-Refine: Data-Aware Top-K for Sparse-Attention Decoding on Blackwell via Temporal Correlation
- April 27, 2026 Behavioral Canaries: Auditing Private Retrieved Context Usage in RL Fine-Tuning
- April 27, 2026 GR-Evolve: Design-Adaptive Global Routing via LLM-Driven Algorithm Evolution